I have classification data represent Credit risk , the problem when I do cross validation it takes more than 8-9 days I’m not sure If I’m doing wrong steps in the workflow or not, I need from you to check If this long time period (sometimes endless time) is logic or not ? where is the problem exactly.
This is the workflow:
The dataset you are using is indeed big and it may clog your computer depending on how much ram memory you have.
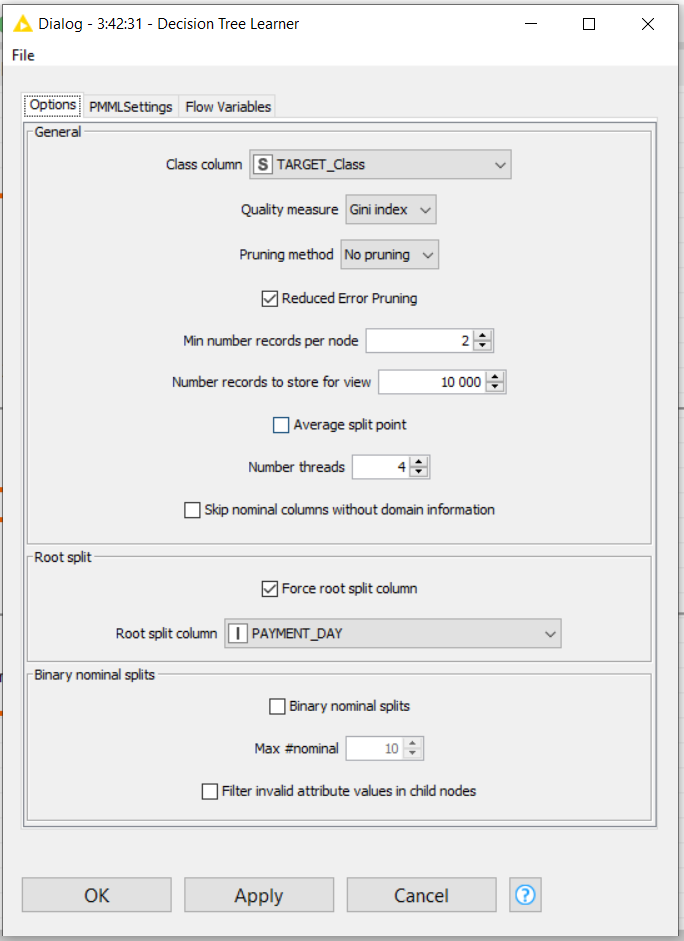
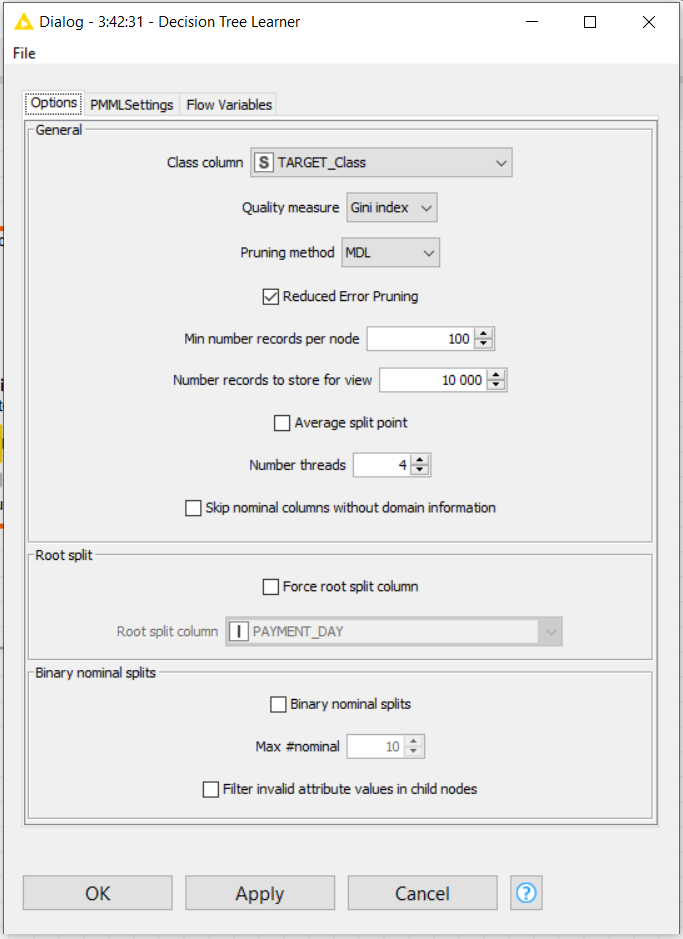
I have taken a look at your Decision Tree classifier and there are a couple of modifications that you might make to improve the speed and statistic performances of your workflow. For instance, the Decision Tree Learner configuration is the following:
The speed should improve a lot if you change the “Min number records per node” from 2 (default option" to something more reasonable for a such big training dataset, for instance 100. This number can be optimized later based on required performance.
Secondly, “PAYMENT DAY” is selected as root split column and “Force root split column” is checked. I would not check this to start with. If “PAYMENT DAY” is not an informative column, it then makes results and speed performance worse.
I did these two modifications and the DT cross validation finished in a few minutes in my computer.
I did not have a look at the other classifiers but I guess there must be room for improvement too
@aworker Thank you so much for this informative information , I’ll do it for the Decision tree , Kindly can you help me about the SVM which is the worst algorithm that cause the delay in un-reasonable matter ? , need your advice.
Concerning the SVM nodes, As you can see from the configuration window of the -SVM Learner- node, there are very few parameters which can be optimized to improve the training speed of the SVM learner: only the type of kernel and a few related parameters. In my opinion, one cannot optimize the training of the -SVM Learner- node just by playing with its parameters. Its training necessarily takes a lot of time given the way the SVM algorithm is designed (a resolution of a system of equations with as many equations as samples and as many unknowns as dimensions).
I do not hence recommend to use it here without a deeper knowledge on modelling based on machine learning.
Besides what I mentioned before, I notice a few choices that I believe are not correct in the implementation of your modelling solution, for instance:
Normalization of data should not be done before splitting the data into training and test sets. Normalization should only be done based on the training set and then the obtained normalization model should be applied to the test set.
Normalizing data using the Min-Max normalization is not a good choice in your case because of the presence of outlier values in this dataset. Rather use Z-Score.
This data is very imbalanced and this has to be taken into account to achieve its classification.
In the workflow, the choice of the kernel in the SVM Learner node is polynomial of order 1 which is equivalent to do linear classification. This is most probably not the underlying nature of this dataset and hence a more complex model or setting is most probably needed to solve this classification problem.
@MAAbdullah47 I would kindly recommend to follow some training in machine learning before to tackle a complex problem of this kind in order to understand the problems (just a few cited here among others) that arise in the implementation of your ML workflow.
@aworker thank you for your kind response , I’ll consider all your guidance , need to be reviewed , I’ll get back to you soon by today , then to close the case.
Hi @aworker , could you share with me the setting update you made it to the (Decision tree) if you don’t mind to make sure and learn from the setting you mentioned in your last thread replay?
@MAAbdullah47 I have toyed around with your data and used some sample workflows and Jupyter notebooks I have recently provided in my machine learning space (mlauber71/Machine_Learning – ml_binary – KNIME Community Hub). Also I have compiled two reports with sweetviz and Pandas Profiler. As @aworker has said - your data might need more understanding and preparation as it stands and also maybe an inspection if the data provided can possibly contain the information you want.
Also if you want to learn more about machine-learning in gerenarl I have compiled a few ressources:
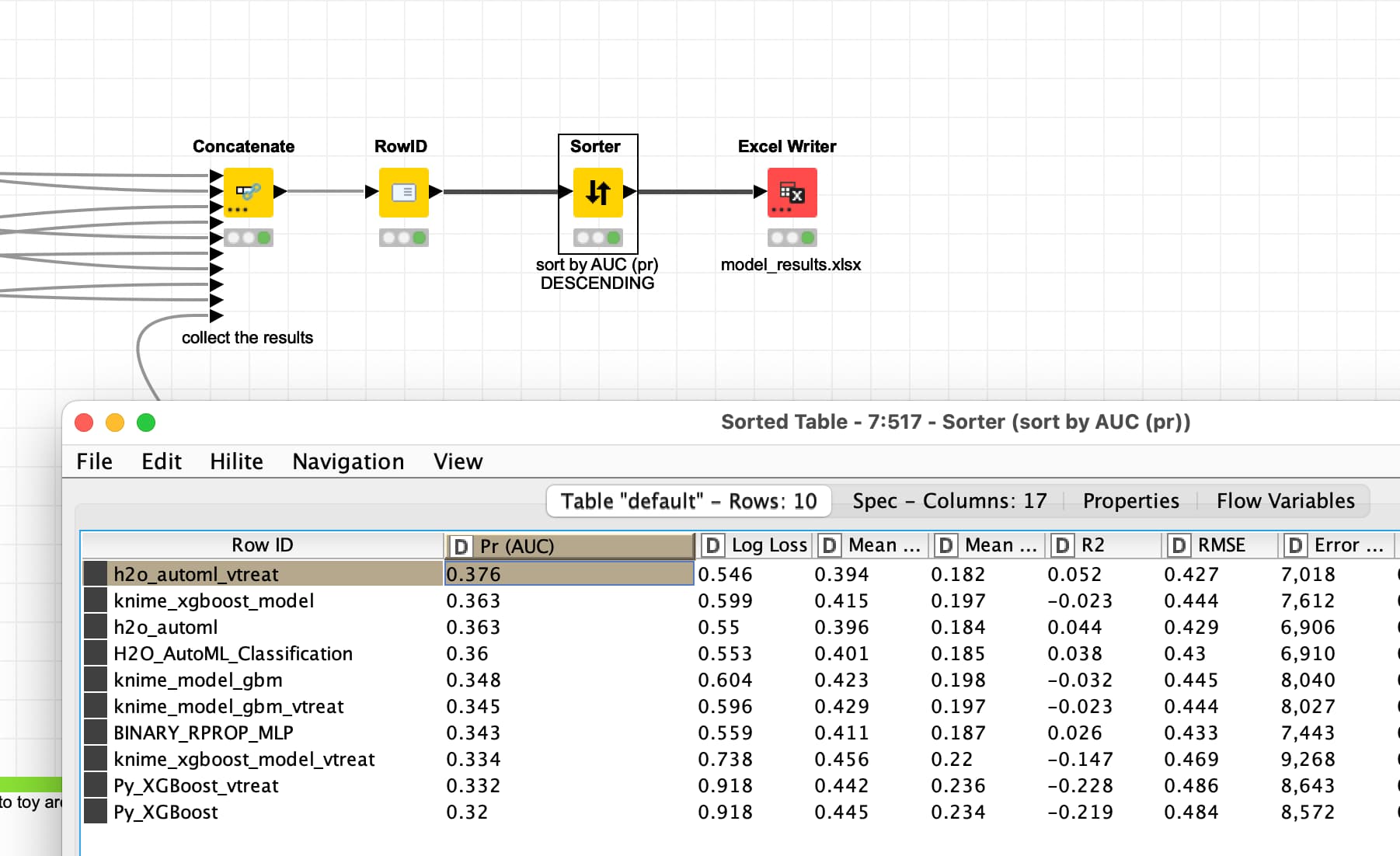
Then using the data provided these are the best outcome so far with using vtreat and H2O.ai AutoML combined. For a credit risk task they do not seem to be very good. Also you might clarify what the Target=1 would actually mean. Is this a default or just some risk? While being unbalance a 20%+ default rate on credit would seem very extreme for me:
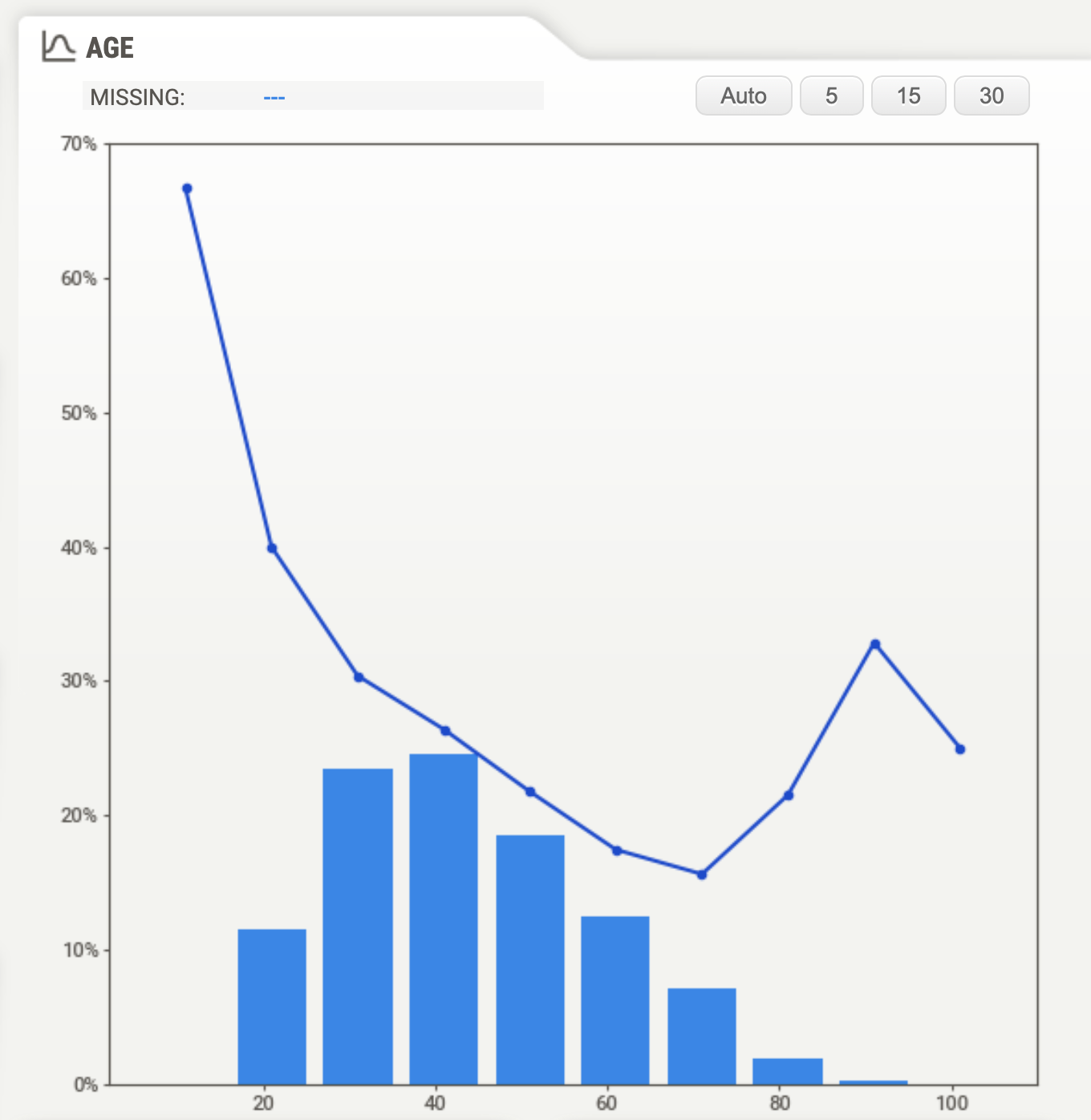
Age is shaped that very young and elderly people seem to be most at risk for credit default (which would make sense). The blue line in the sweetviz report representing the % of Target=1 per age group.
Also if you have a landline you run less risk of default.
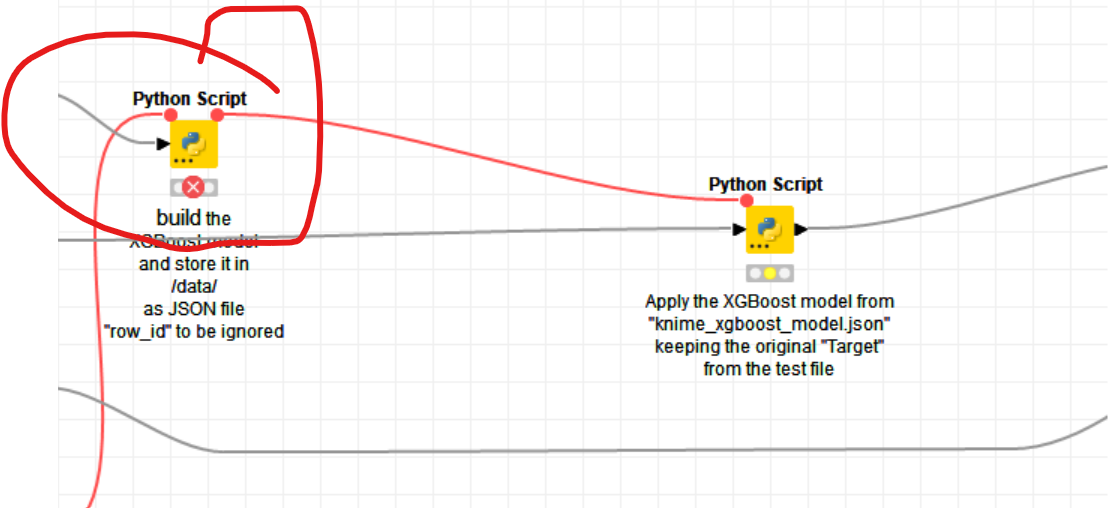
I am not sure if employing SVM would make the model much better. The improvement thru using vtreat (Data preparation for Machine Learning with KNIME and the Python “vtreat” package | by Markus Lauber | Low Code for Data Science | Medium) might hint at the need to employ more data preparation, while the overall precision currently is not that good and the strong regional variables might need more attention if you would expect these patterns to hold or if you only have very small regional entities you might have to combine some. But here is the workflow I have adapted:
In the subfolder/data/notebooks/ there are more Jupyter notebooks to play around following ideas presented here:
I suggested this configuration just to show that limiting the minimum final number of samples per leaf in the tree reduces the time of execution of the -Tree Learner- node. This setting is not necessarily the best in terms of statistical or time performance and that needs to be optimized too.
@mlauber71 has suggested a few links to help you with the task of setting a classification model and applying best practices. I would hence recommend to read them and follow his wise recommendations and then come back to the forum with questions if there are things for which you need extra help.
@Daniel_Weikert not really. You can adapt how long the H2O.ai nodes would run and also how many models the other nodes would do. I have put together some models that might make sense - you would have to be careful about overfitting but H2O.ai tries to take care of that.
Something might also depend on the very version of H2O. They keep adding new features like explainable AI. Very interesting.
Hello dear , Today I didn’t do the performance test , I was in a tutorial series as @mlauber71 recommends , I promise you to do that tomorrow , so please accept my apology.
Hi @MAAbdullah47
I would be interested in an “apples to apples” comparison between knime and python regarding execution time (same ml models and configuration)
If you could shed some light on this i would appreciate it
br
You might want to install Python on your machine in order to execute the workflows. The node you are using has been configured for MacOSX (Apple Silicon). There is one for Windows right next to it. More details here. Yes might sound a little bit more work but once you have mastered it you will have KNIME and Python at your fingertips:
H2O.ai AutoML also has been implemented with only KNIME nodes. It should be in the example.