@MAAbdullah47 like @Daniel_Weikert said you will have to use the right environment or tell the python node to use the basic one.
Also you could use the environment propagation provided. It hopefully is all in the article.
@MAAbdullah47 like @Daniel_Weikert said you will have to use the right environment or tell the python node to use the basic one.
Also you could use the environment propagation provided. It hopefully is all in the article.
Hi guys,
I kown that I’m late, but I’d like to share some performence tips with you.
Import Files
========================
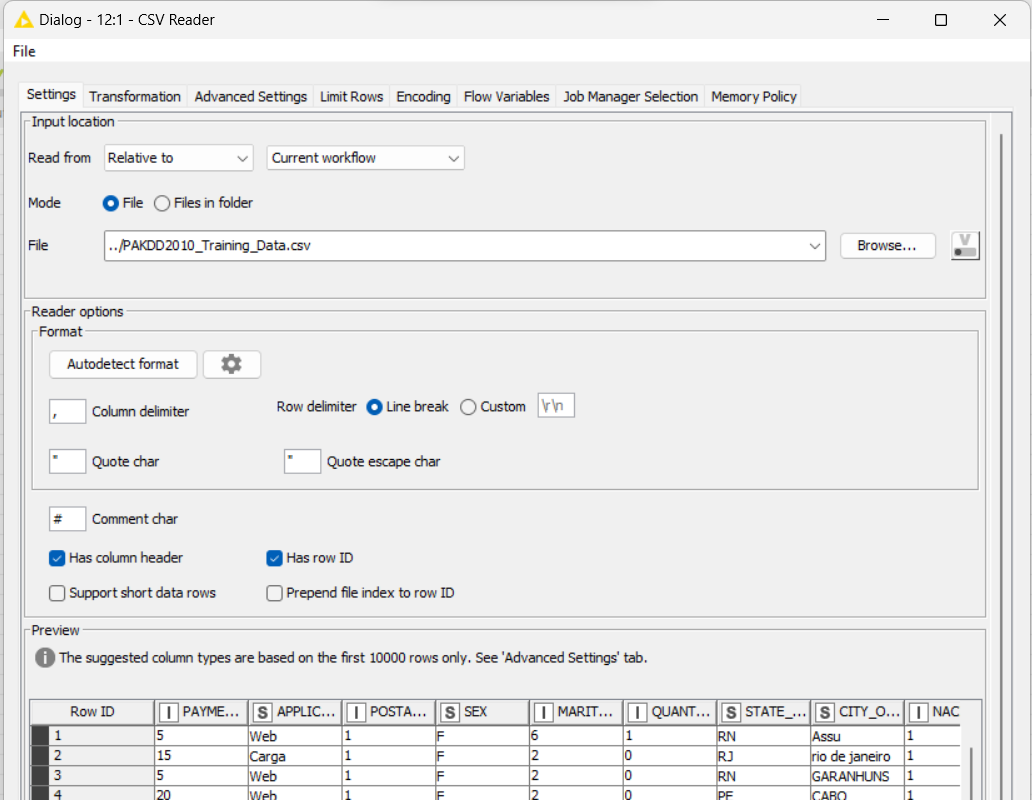
If you import files like CSV, use the csv reader because you can set all information about the file and make a batch if there are more than 1 file at the same folder.
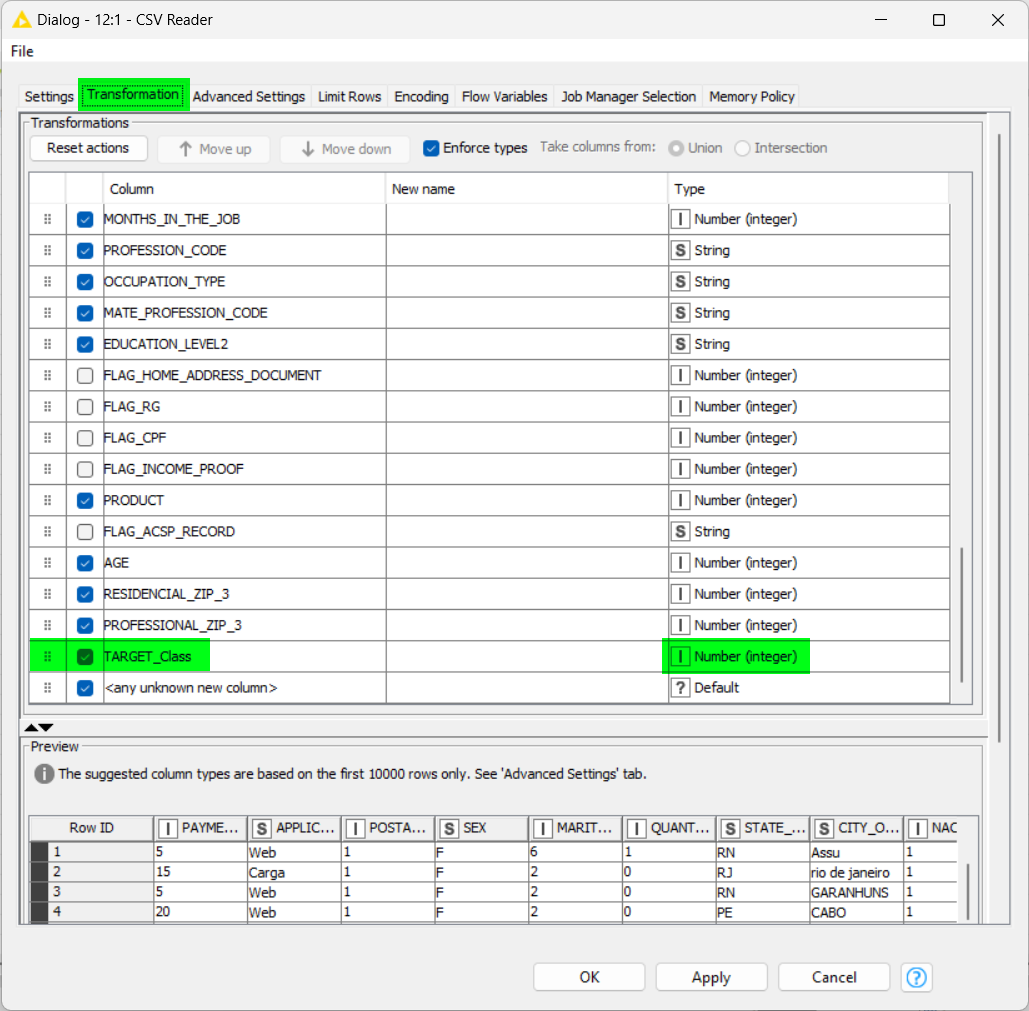
More that that, you can select the columns that you’ll really use for this flow, removing extra data from the memory. For this, go to the tab called “Transformation” to setup the fields, unckeck the columns that won’t be read… It can save a loto of memory cache.
By the way, You can change the type of the column at this moment, avoiding to use another node to do it! Just chance the type at the right column information.
Missing values
====================
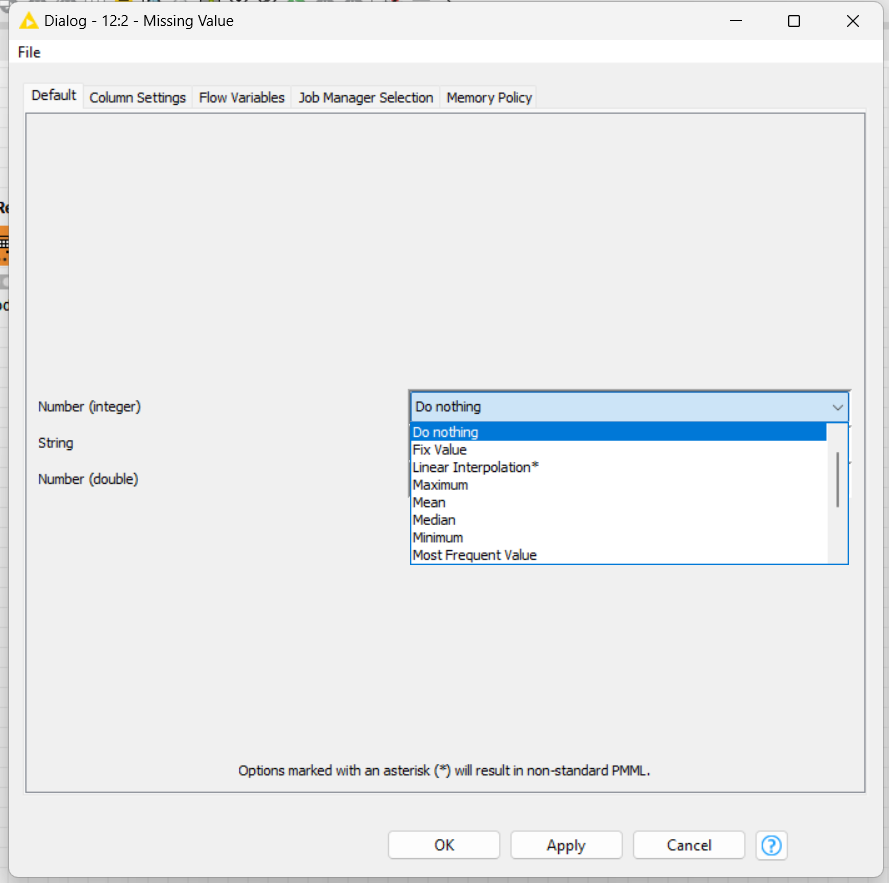
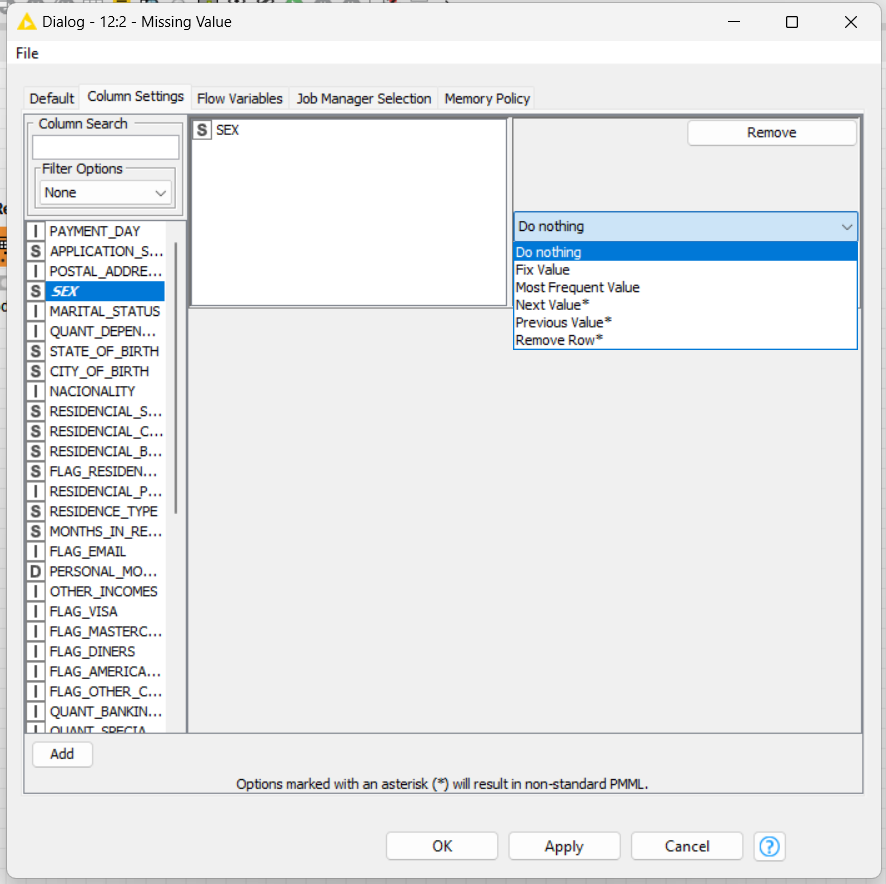
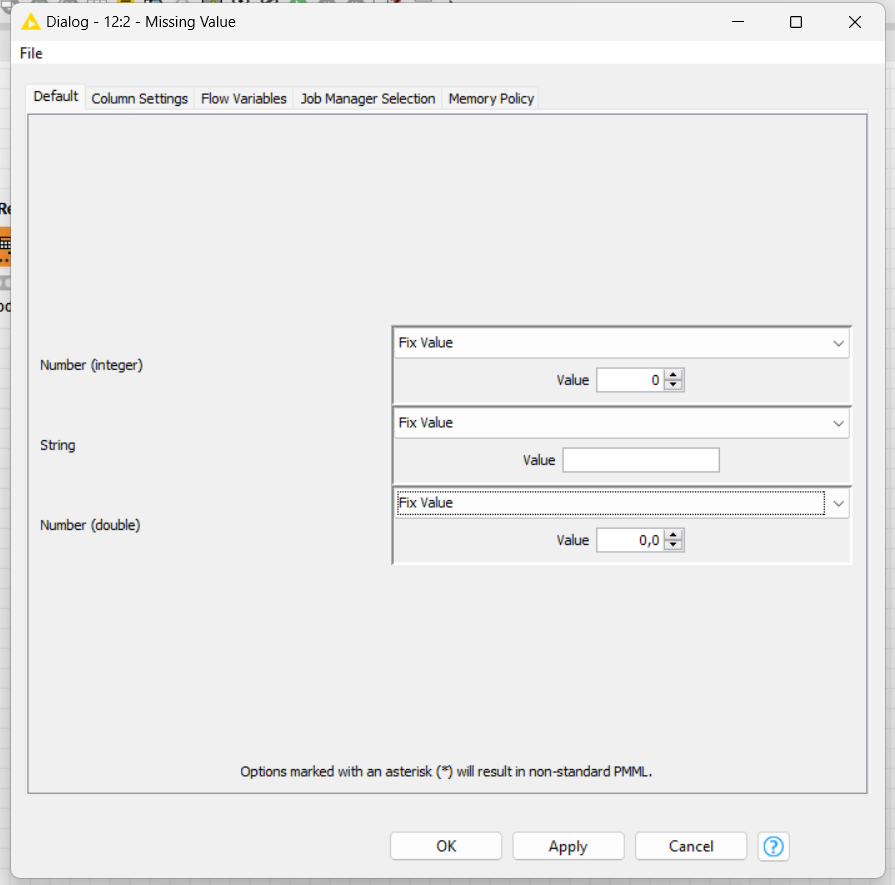
I saw that some columns have missing values. You can use “Missing node” to fill it with default values or bring information from other lines (prev line, next line…).

At the first page from this node, you can set for all columns or at the “Column Setting” insert each field that you need to fill with something.
For my example, I’ll set all the fields with default values
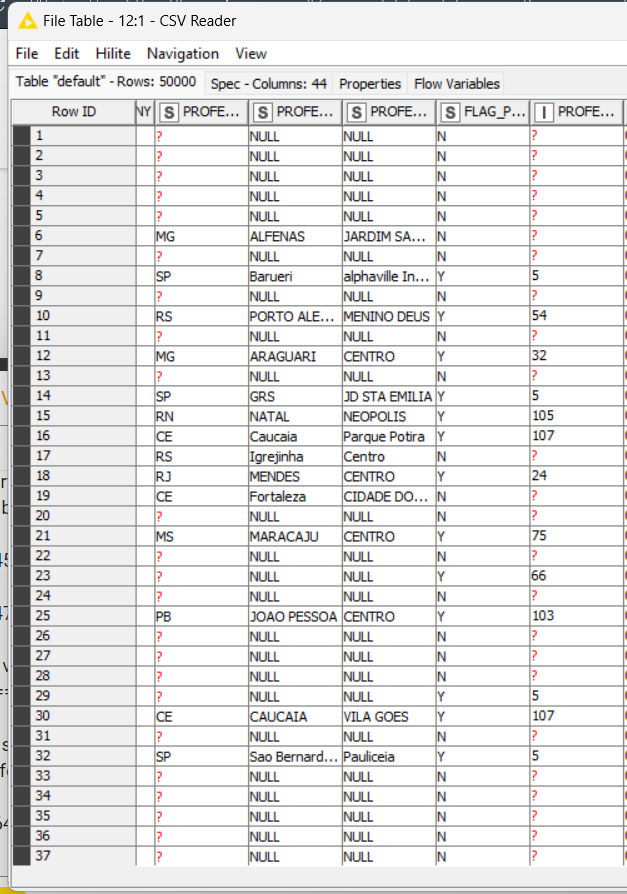
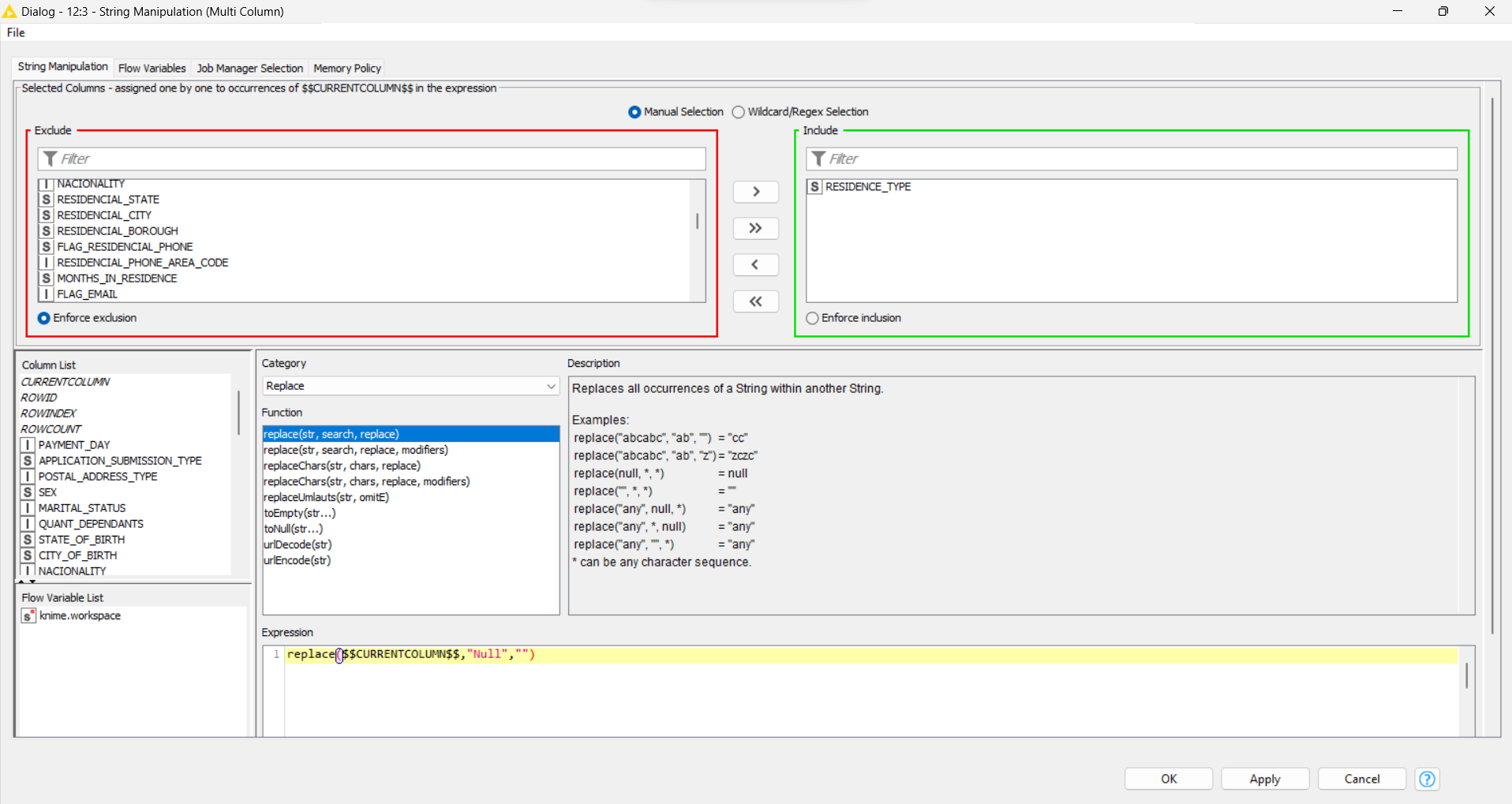
After that, I saw that some information came as “Null” value, but you can change it using “String Manipulation (Multi Columns)” node to set a empty value.
From the example above, I selected the “Residential_Type” String to change “Null” to “” (empty value), overwriting the column value. If you select other columns, this note will apply the same expression for all of them (*selected at the include window at this node).
I force the filed to be empty instead a missing value and replace the same column.
BUT, check first the type of the column to make changes before it, same time and optimize the kind of the information (date, number, string…) all of it is very important as ETL process / modeling data. Some columns could be transformed before but i won’t make this transformation now, only if necessary to check/validate/evaluate a information.
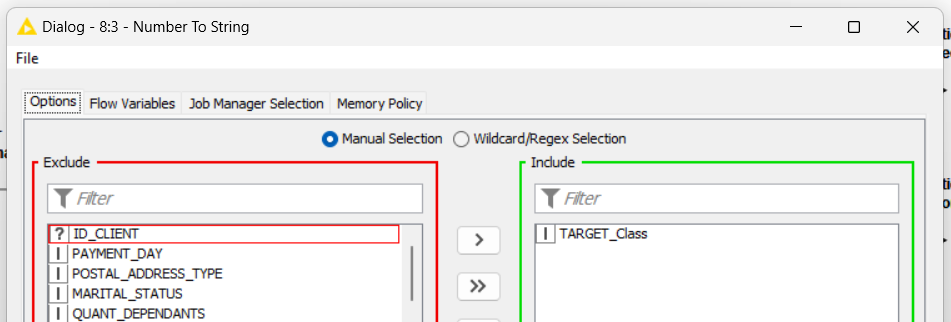
At your 3rd step, you made a change of kind for the column “TARGET_Class” from number to string. You can setup from the first step as I told you at the transformation tab on CSV reader.
FROM:
TO:
Sometimes the CSV reader identify the kind of the information and change automatically, make it easier for you.
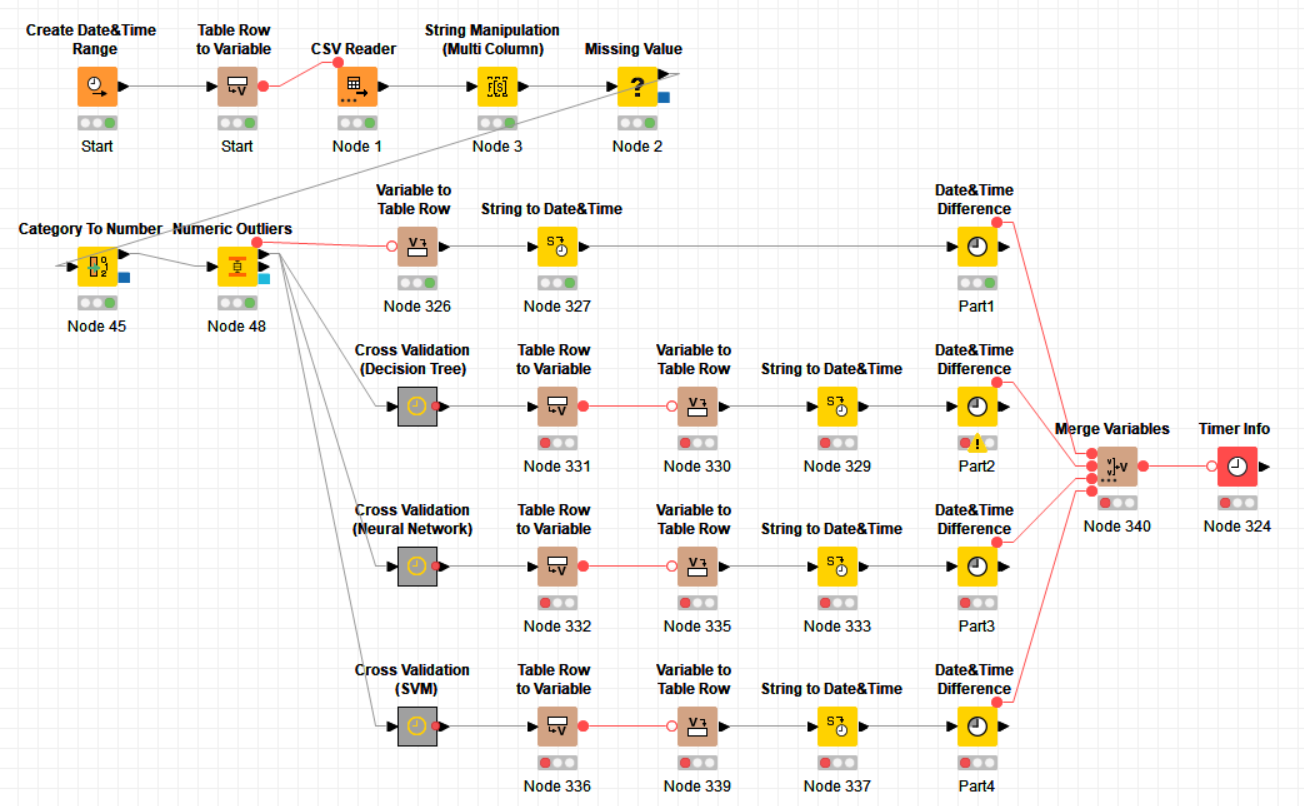
Until the node “Numeric Outlines”, it took 5 minutes to process the data, after that, each component take a lot of minutes to process. i believe that you need to check each one to understand where is the neck and make some changes to resolve your problem.
I put some “Date&time” node at the begin and after the “Numeric Outline” to check the performance until there, and can be used with the others components, or you can use the “Time Info” node to make a resume from all the nodes and process to identify which one take longer than other to correct or remove.
That was my flow with your data to you validate it.
BZL_C_RISK2.knwf (112.6 KB)
I hope that tips can help ypu and the communit too!
Tks,
Denis
Hi @denisfi
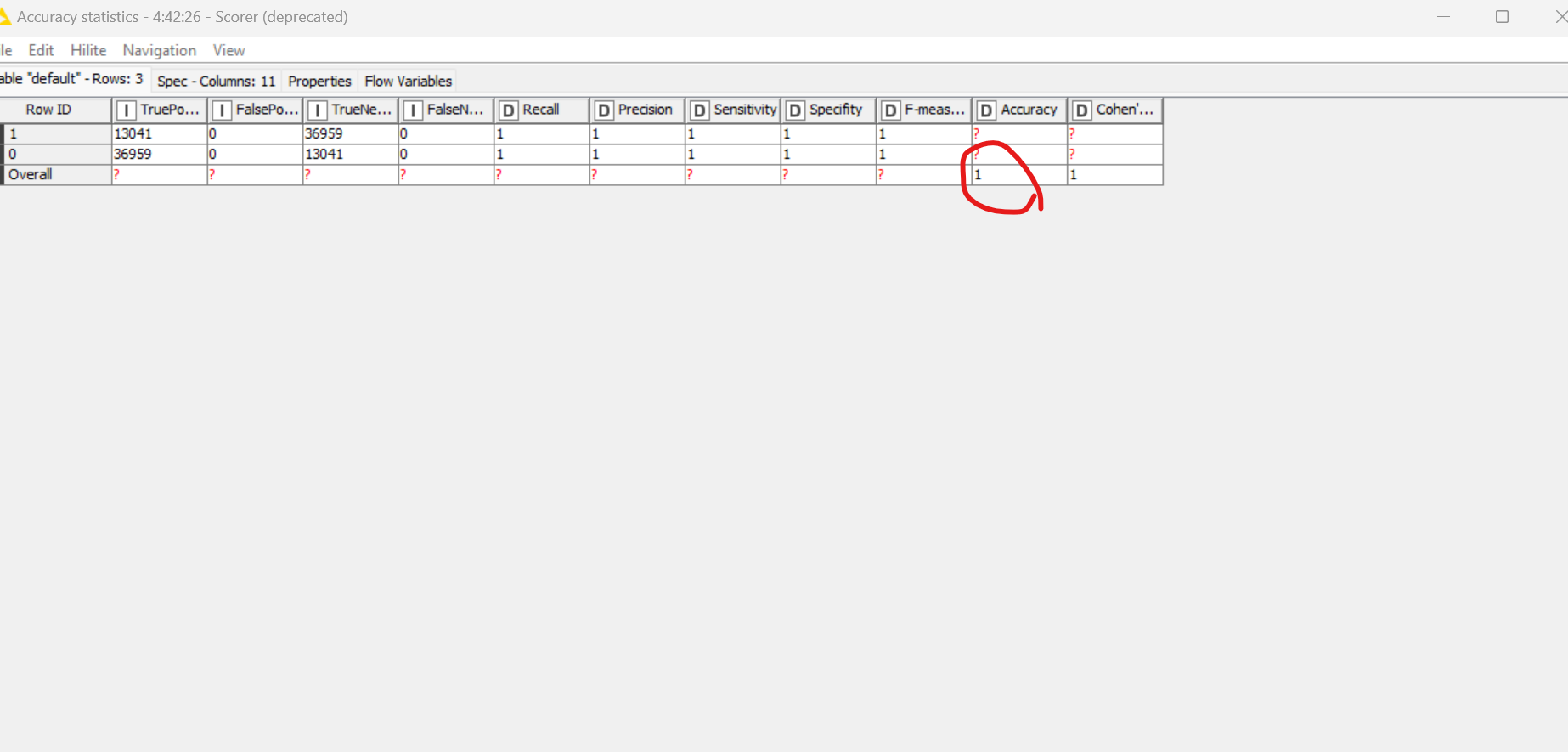
Thank you so much for your assistance , at the moment the decision tree is over and it takes less than 14 minutes , the strange result the accuracy is 100 % here is a screen-shot:
Later when other Algorithms finish I’ll share with you the results and thoughts.
Waiting also @mlauber71 on how to fix the python scripts installation errors , to share also the experiments of Python.
Hi @denisfi
Could you confirm the same results for the DT algorithm ? I think this impossible .
Well, you can set a rule engine node to check if all columns are filled and make a true/false column to filter later or change the values from this column to 0.
Another tip is to break a part the flow between the components. If you save in a database table the result, you can call other workflows to load the information and calc sequentially not in parallel mode. It’ll save memory and process quicklier too…
Best reguards,
Denis
I didn’t understand could you repeat by example?
However I attached the workflow with the results
BZL_C_RISK2_2.knwf (132.9 KB)
Here is Decision Tree
Here Neural NW
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.