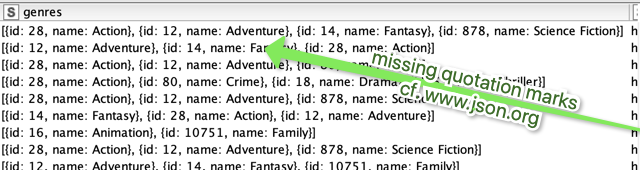
I am starting to use Knime so I apologise if my question is too basic. So here is the thing: I have a csv file and some columns in this file have a json notation, as the following:
I need to find a way to treat these kind of columns properly in order to do some interesting 'whatever' analysis. So, I tried to use json to table node but the console box says 'No column in spec compatible to JSONValue'. I also tried to import the csv file as a json file and was not accepted.
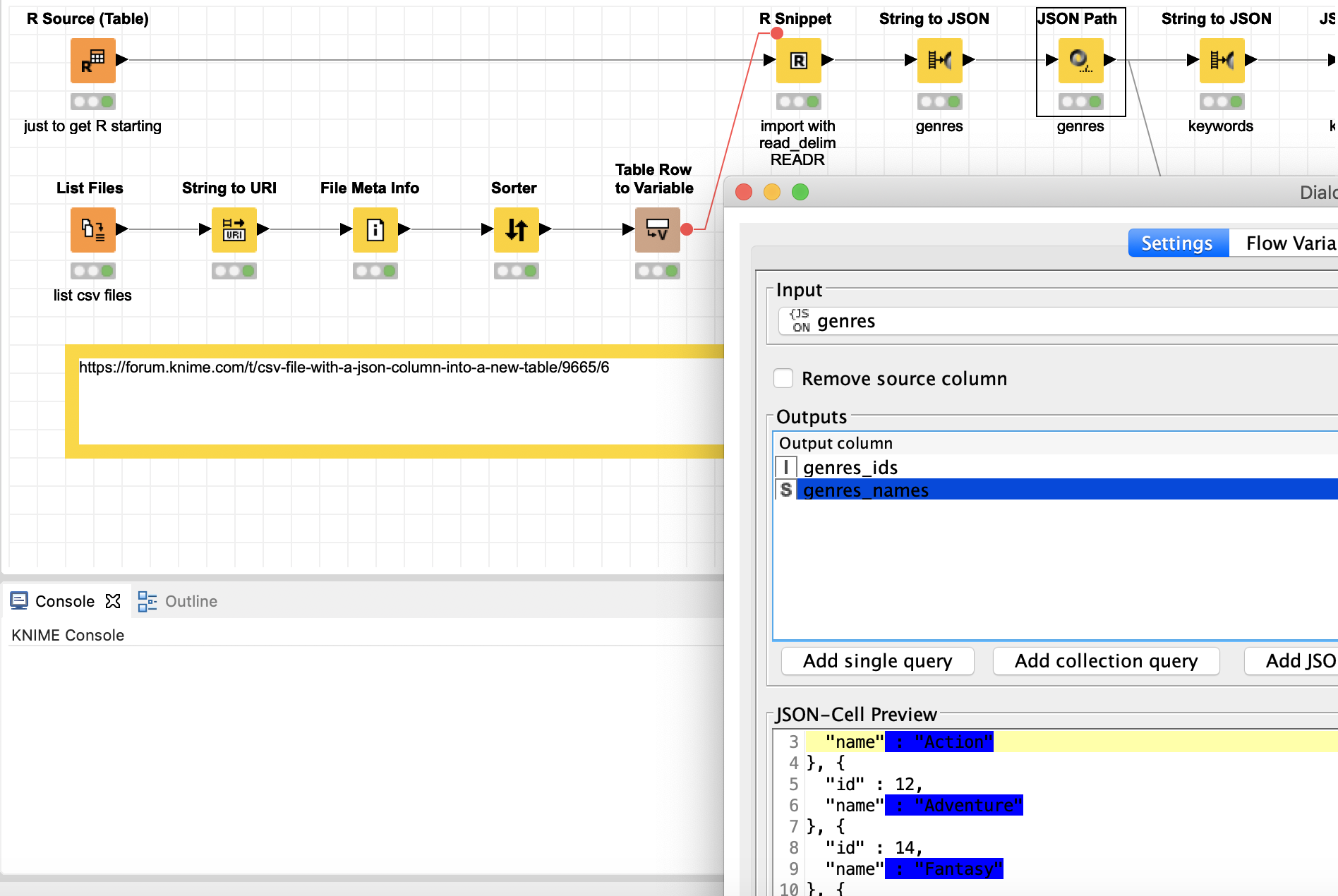
no matter what kind of reader (e.g. file or csv reader) you used, it does not automatically recognise that some columns might be in JSON format. It just reads it in as a string. So you first have to convert the column and its values with a String to JSON node. Afterwards the column format is JSON and you can use a JSON path, JSON to table or whatever node you like to do your transformations. Hope that helps.
I am trying to convert the columns genres to a JSON and then to parse it in a traditional table with multiple records but I did not manage to do it. Please, could you help me? Please find attached the workflow
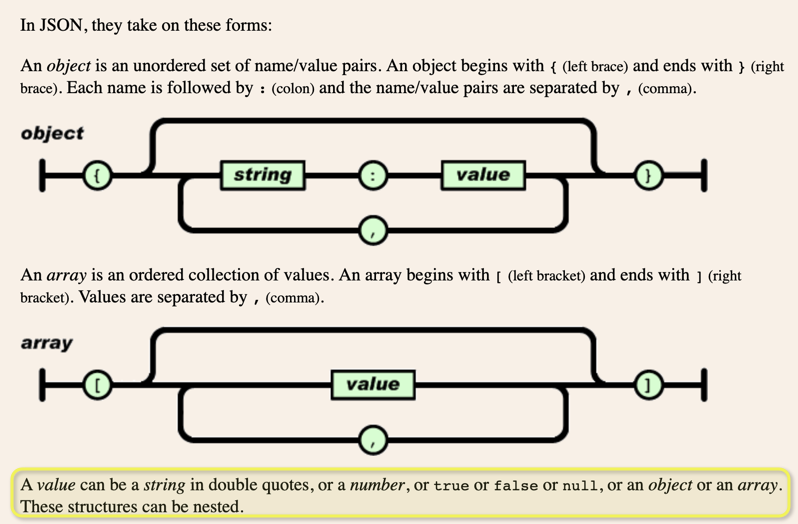
do you have the data in any other way? From my perspective the JSON format lacks the quotation marks. It could be possible to manipulate them back in but better to get clean data.
Or alternatively, this approach with a Java Snippet might work (seems like that the screenshot is no longer embedded into the post, probably due to the forum migration, but the link “Bildschirmfoto” will show it):
Dear all,
Thank you for your answer. Please find attached the original file. As you can see the quotation marks exists in the original file (it is also present here https://www.kaggle.com/tmdb/tmdb-movie-metadata). You cannot see the Quote in Knime File Reader because to import it correctly I had to add the Quote as a Quote Character in Advanced Tab of the File Reader node.
So how how can I import and parse correctly this fie?
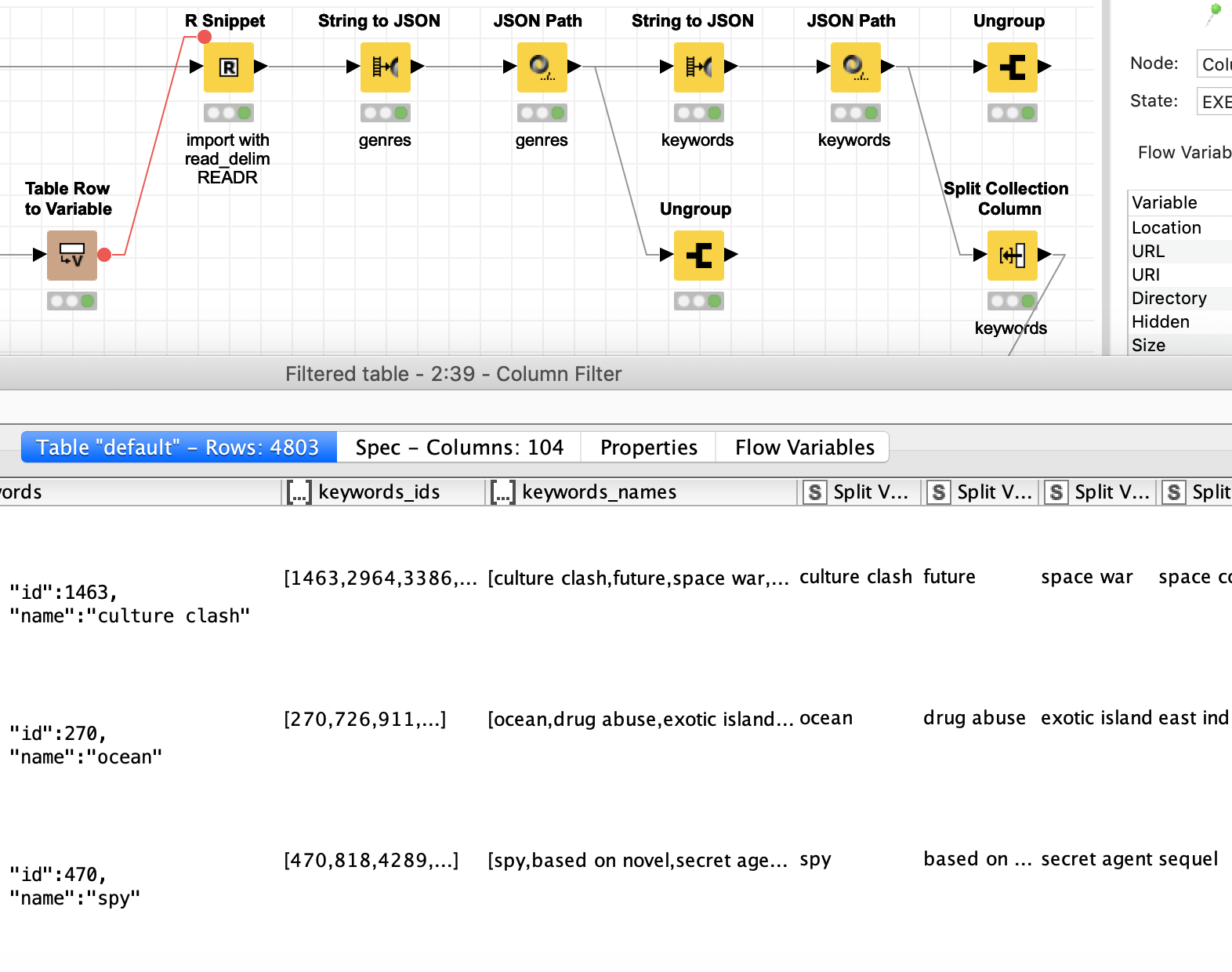
If you use the R package readr to import the CSV file it will handle (hopefully most of) the quirks and preserve the Json strings.
These strings can you then convert to collection columns and ungroup them, that gives you the information (note with ungroup there will be one duplicate line for each original entry.)