Has anyone run into this situation before? Using the CSV Reader node to import a text file and it’s missing about 100K rows and doesn’t show an error message. As far as the node is concerned, it would appear as though the entire file was loaded.
The File Reader (Complex Format) node reads in the entire file, but using this node isn’t a great solution as it sometimes doesn’t import the entire file either (but in those cases the CSV Reader does!).
Not working with large files here, generally under 1.2MM rows total. Visually, there doesn’t seem to be anything unusual about the rows that are skipped - no extra delimiters or strange characters.
I’m using Knime 4.4.0.
Appreciate any advice on how to diagnose either the issue in the file or improve the ability of the CSV node to read all rows (or throw an appropriate error).
Hi @JX_367,
I would be happy to have a look. Do you have an non-confidential example file that you can share? And when you say it is missing about 100K rows, are those all at the start or end or does it drop rows randomly?
Kind regards,
Alexander
To be honest, I noticed this issue. In my case, the issue comes from SAP, which extract txt/csv files and write them wrongly (it adds unwanted tabulations or “\t” or incorrect end of lines “\n”). This error occurs only for files with a lot of lines.
So I made an alternative with a component. I read the file with line reader and “clean” the file myself. That way I never miss a line. You can try it if you want :
If you use it, you should remove this node (it’s useful for me 'cause SAP add some line above) :
@AlexanderFillbrunn,
I don’t think it’s Knime fault. In my opinion, it’s file related. Everything works well (with CSV/File reader) except this case. I’ll try to share some data with you, but for now I only have conf. data (work related).
Thanks for the quick feedback - it prompted me to go back and examine this a little further, and I think I can mark my issue as solved.
Unfortunately I can’t share a non-confidential version of the file, but it is basically a daily transactions file. 80% of the time, there are no issues with reading in the file using the CSV reader but 20% of the time this issue was occurring.
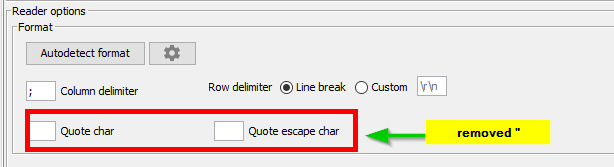
I thought the skipped rows were randomly spread across the file because I was using a RowNumber field that was generated within the file itself. I assumed this field was sorted, but by using the Row ID field that Knime adds in, I was able to see that my RowNumber field was not sorted, which then let me see that indeed, the 100K skipped rows were sequential. Tracing it back to the last complete row before the “missing” rows allowed me to see that a " quote in a customer field was causing the issue and basically ~100K rows of data were being captured within one cell. An error wasn’t being thrown because I had deselected “Limit memory per column” under the “Advanced Settings” tab.
Removing " as the Quote char/Quote escape char on the Settings Tab solved this issue for me. All rows are now read in.