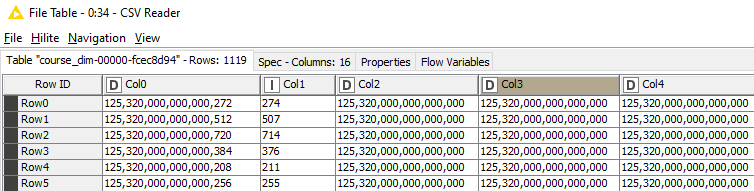
I’m using a CSV reader to import datatable from CSV file which has several columns with IDs related to other tables. The IDs are 18 digits long, When the reading is done, the columns are of a double type and rounded, so the least significant digits are all 0.
How to set the column type to a string and avoid this? One suggestion in another thread was to read IDs as Row IDs, however as I said my tables have many columns with ID related to other tables (as foreign keys), so this is no solution.
(File Reader node is not usable because of the CSV format.)
How about unchecking the “Has Column Header” option in the configuration window of the CSV Reader node? (Also, you have to limit the number lines to be scanned in the “Limit Rows” tab > “Scan limit” option > input 1 or 0) So all column types would be string. Then you can handle splitting the first row (Row Splitter) and use it to assign column headers. Transpose the single row table and then use the Insert Column Header node to assign the headers.
But, may I ask why you have found the File Reader node not applicable here? The node has so many “Advanced” configurations which may help you read the file. Maybe you can share a sample file with us?
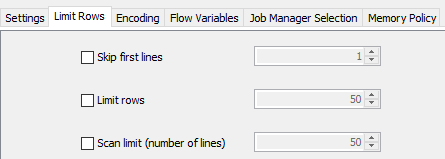
Thanks. I don’t have a header row. Setting Scan limit to 1 or 0 gives
Execute failed: For input string: “\N” In line 381 (Row380) at column #12 (‘Col12’)
(empty “cells” are denoted with “\N” in data file.)
I’m reading several files in the loop, where each file has a different column structure. If I use the File Reader instead of CSV Reader, it reports this kind of errors:
Execute failed: For input string: “some string” In line 1 (Row0) at column #3 (‘Col3’).
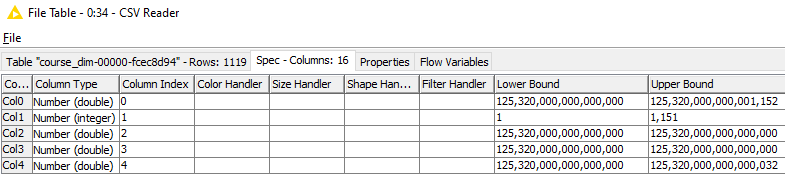
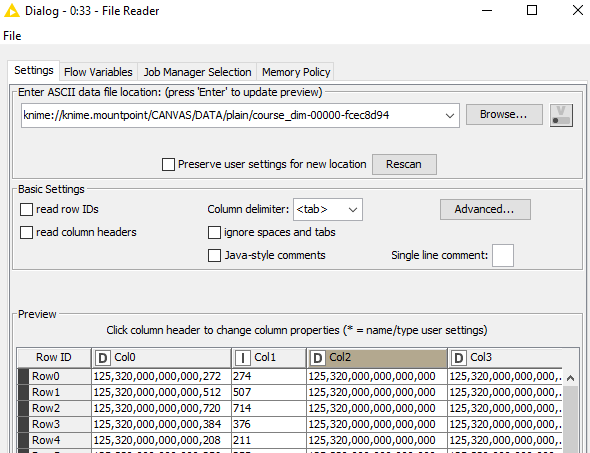
Please note that the 18 digits columns are of type double. Interestingly, Col0 is at first glance OK however the last digits are wrong. The upper limits reported are wrong for all columns except for Col1.
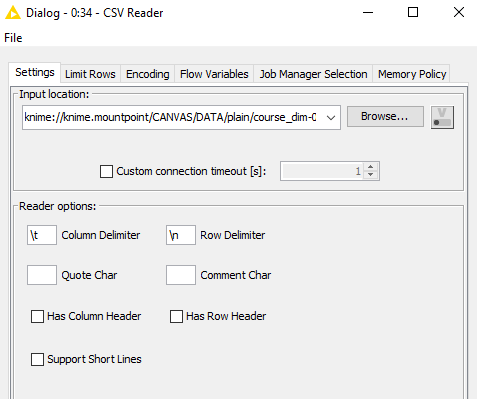
This is the setup:
File Reader gives the same result. Already the preview is wrong:
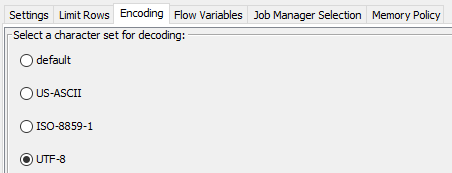
with settings as for CSV Reader (where applicable).
In the table preview section of the File Reader node, double click on column headers and then you can modify the corresponding column configurations (name, type, …).
Different data tables have different number of columns, different types, since they represent different content. I cannot provide the data due to confidentiality.
Are you appending the the content of the files in the loop?
So how about reading all columns as a single column for each file and then use the Cell Splitter to split them?
No, I have a directory of ‘raw’ CSV files which are read sequentially, the resulting tables equipped with column names and then separately written as .table files. The internal structure of tables should be persisted (column order).
Following your advice, I tried to read entire lines with Line Reader and then use the Cell Splitter, however the Line Reader doesn’t preserve the tabs (huh?!). Is there any other way to read lines as they are?
You could use the CSV Reader without column delimiter so all columns will be in a single column and then you can split them with the Cell Splitter. Or you can follow the solution provided by @mlauber71.
Actually, the CSV Reader node and also the File Reader node (if uncheck “ignore spaces and tabs”) preserve tabs but we cannot see them!! Just try the Cell Splitter with \t as delimiter and you will be surprised!
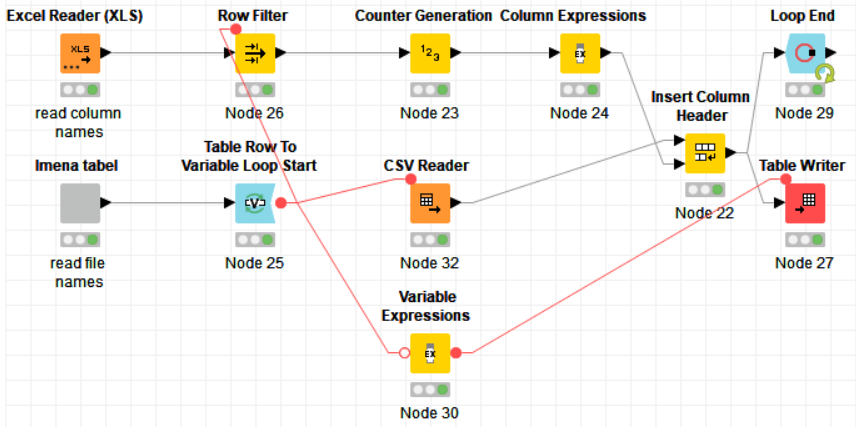
Here is an example workflow in which I have used both nodes to read a CSV file similar to your case and split it to have all fields as strings: csv_tab.knwf (24.0 KB)
How many files are we talking here and is this a repetitive thing or a one-of thing?
I’m gonna say the heretic thing here but if it’s a one-of thing and not too many files, opening them with excel, setting the columns to text and then using excel reader might also be an option.
Albeit I do feel with a proper example from your side and some thinking it should probably work with pure knime.
Thanks, @armingrudd - I followed the settings in your example, the crucial thing was result as a list from Cell Splitter and using Split Collection Column afterwards.
@beginner, no worries, I have >200 files on a monthly basis (API calls), >20 GB plain text.