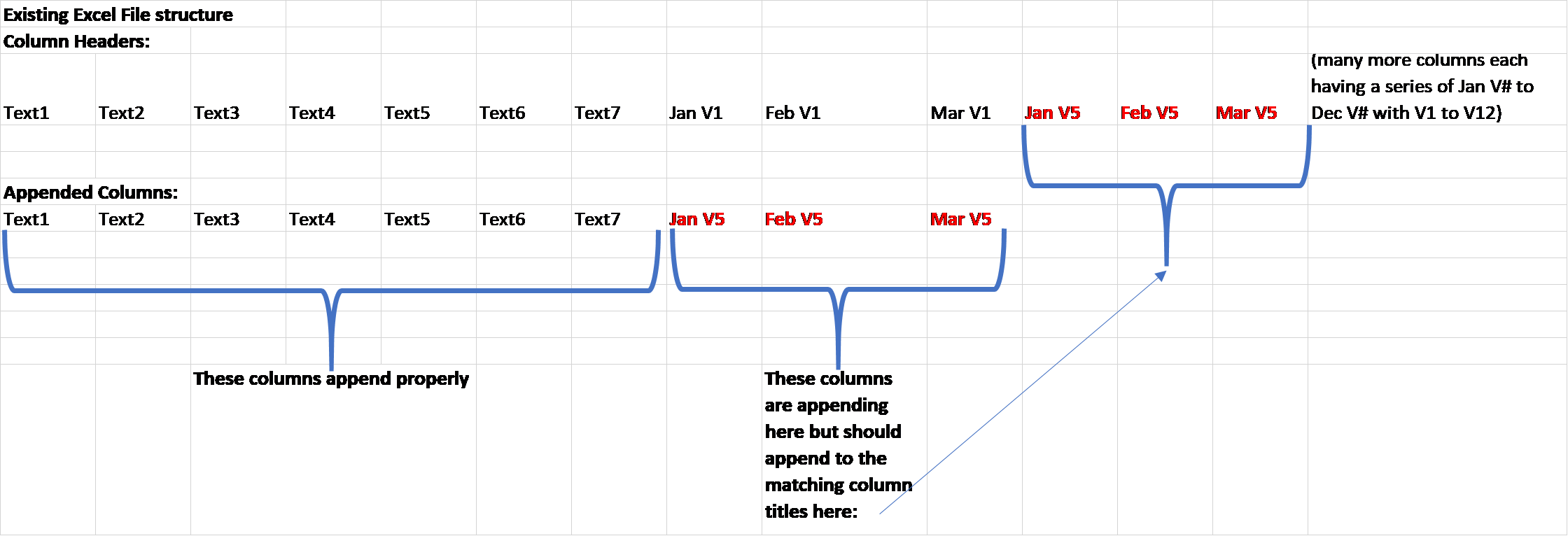
Hello, I’m trying to append workflow results (38 columns and ~3000 rows) to an existing csv file. The columns I’m trying to append are not in exactly the same order as the destination csv file and are not appending to the right columns. To clarify:
The first 24 columns are in the same order as the destination file and are appending properly but the next 14 columns I want to append are not directly adjacent to the first 24 columns in the destination file. They are located about 56 columns to the right this month. Next month they’ll be 68 columns to the right. Does anyone know a node to use or how to program the csv writer to match columns names so it appends to the right columns?
could you give an example for your csv and the workflow results you want to add to the file?
Maybe even how you expect to look like after the merge?
(just a few lines like your format - does not have to be real data)
As far as I can understand you want to add more columns than there are currently in the file -> all existing columns you want to be added to the current columns in the csv, all new columns you want to be added directly afterwards?
Thanks for replying. I don’t want to add more columns than are currently in the file, I want to append to existing columns but they’re not in the exact order of the target file and the location of these will change every month. I basically need a feature that tells it to append to the matching column titles (which by the way I able to easily do in Alteryx). See below. I hope you see what I mean. Thank you.
thanks for the example.
I hope I unterstand your problem correctly now
(in our company we do not use Alteryx, so cannot compare)
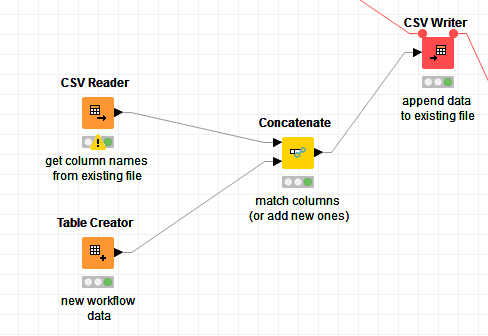
I think the csv writer ignores the column order normally (e.g. just writes the columns as they were in the input table)
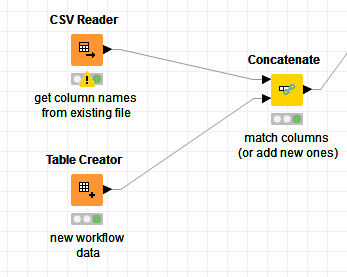
To force it to append the columns on the correct position you can first read in the column order
Then use the concat node (first input port so the order from the current file is used)