I am raising this as a bug as I’ve gone to extreme length bullet proofing the approach. By analyzing the results I see strong indications that the CSV Writer is still writing the data to the file but workflow execution already continues.
Let me explain the workflow:
Goal: Parallel process data but write into the same file to prevent individual chunks processing the same data (i.e. newly identified URLs during a scrape).
Approach:
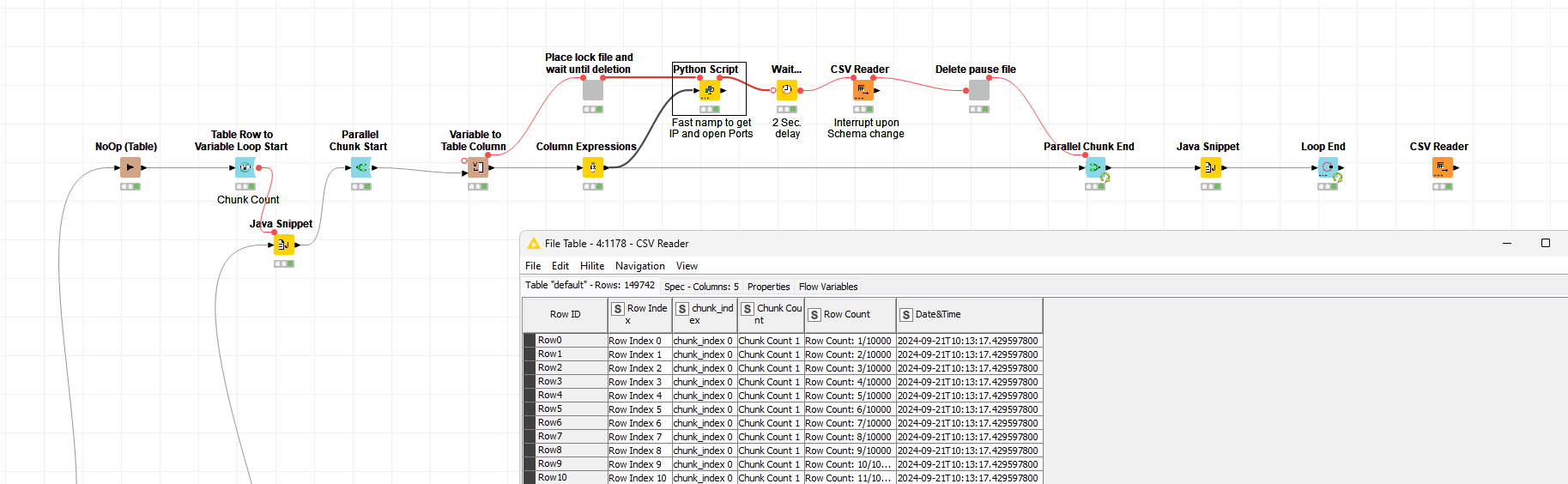
Create Chunks and process data
Wait until all chunks placed their lock file
Identify write order based on lock file creation date&time stamp
Loop until all lock files coming before that of the current chunk got deleted
Write results to CSV
Delete lock file of current chunk
Reiterate
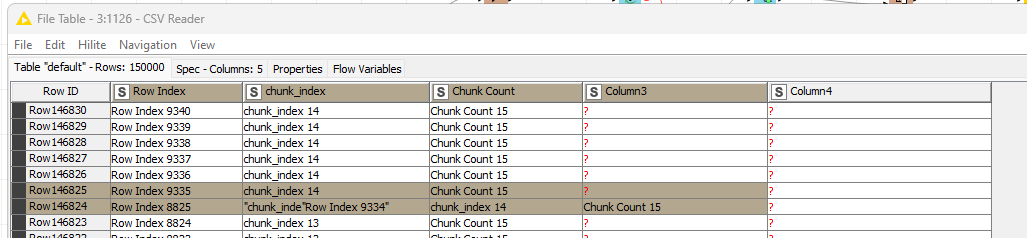
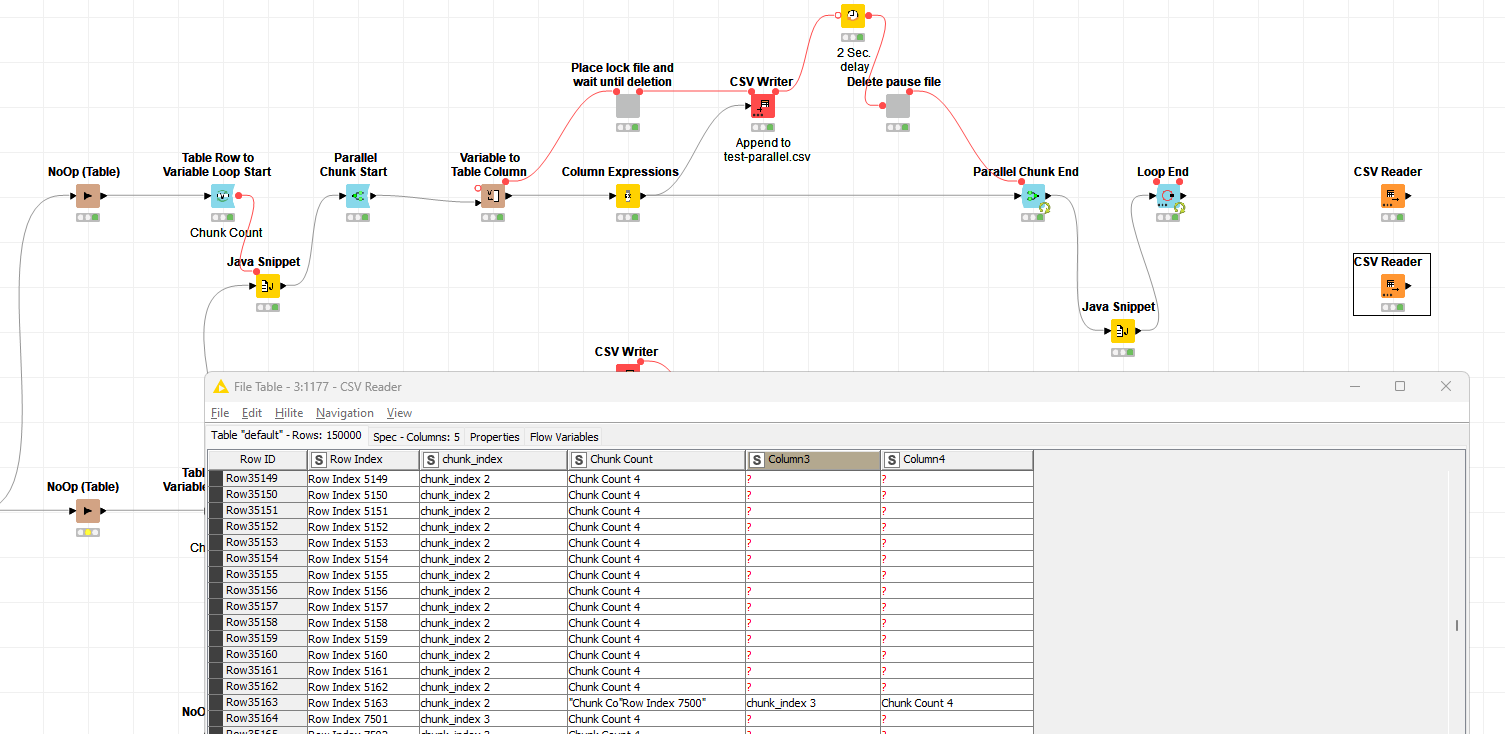
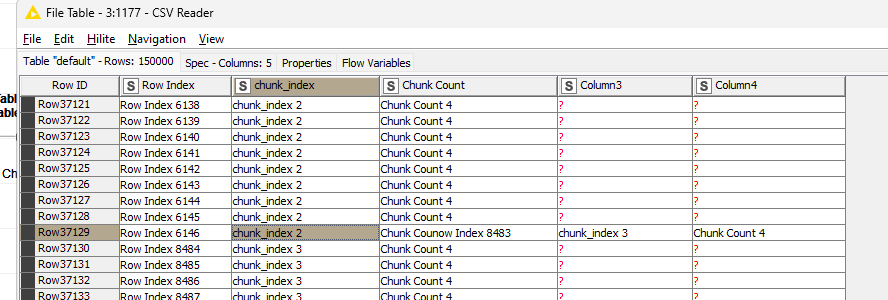
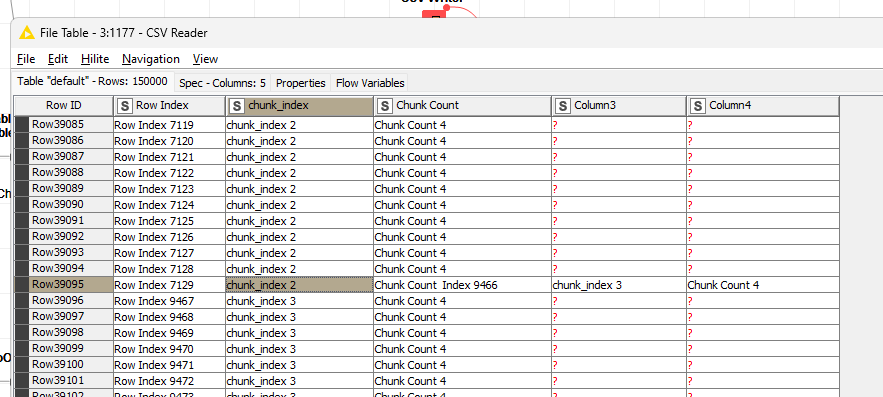
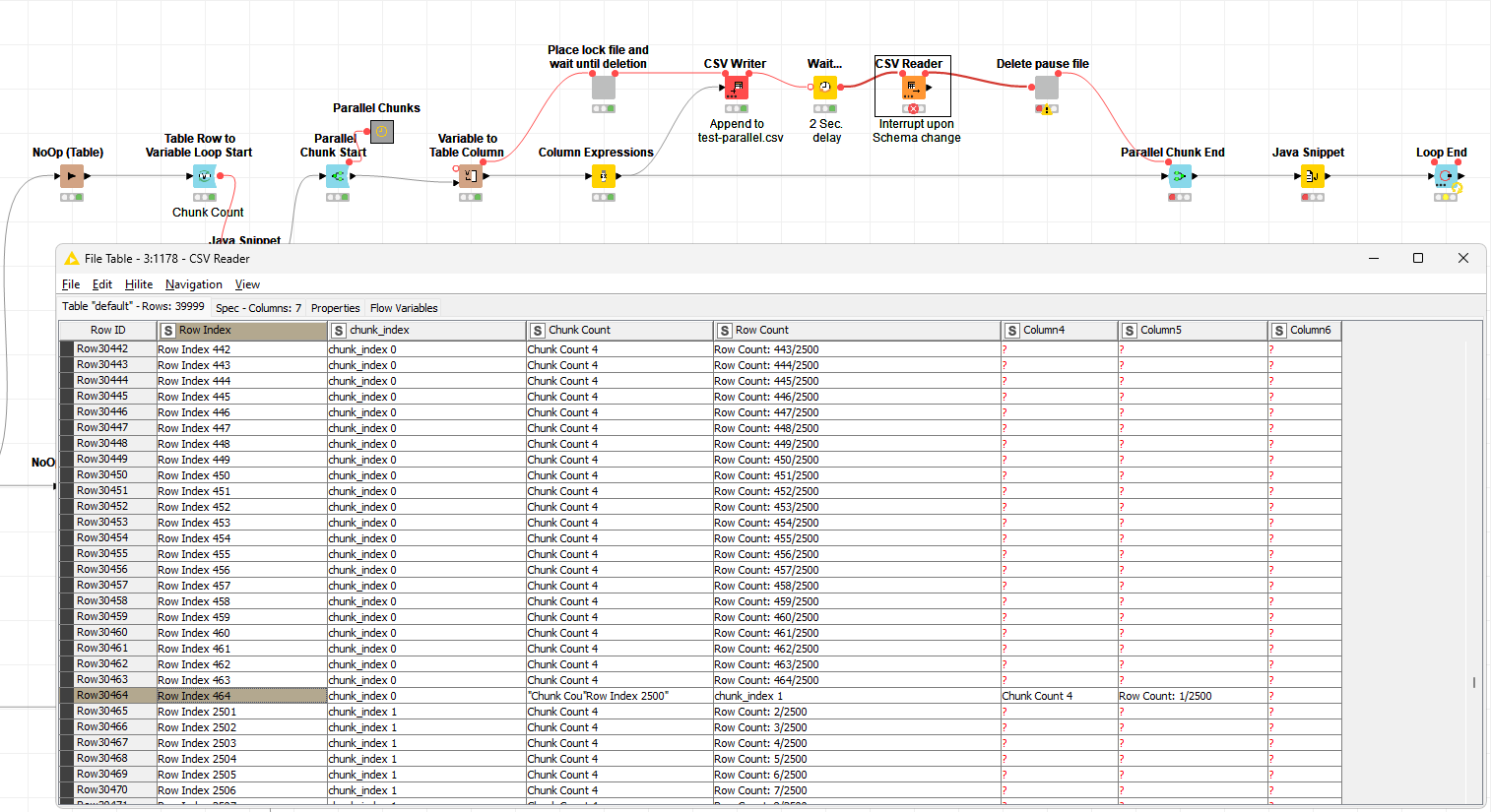
Both tables, that of the loop end and CSV Reader, at the end should match. However, the CSV Reader clearly shows a different structure.
Further digging into the data, by introducing a conditional breakpoint if the schema changes, it seems the data is written in chunks of about 115 rows (30464 to 30579).
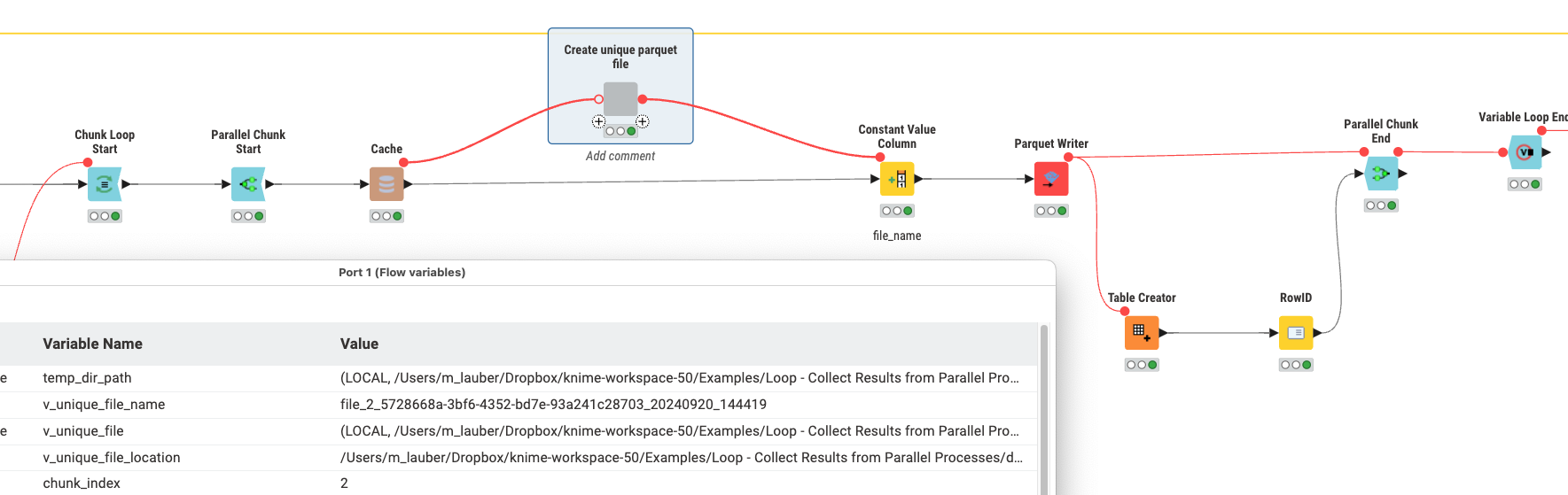
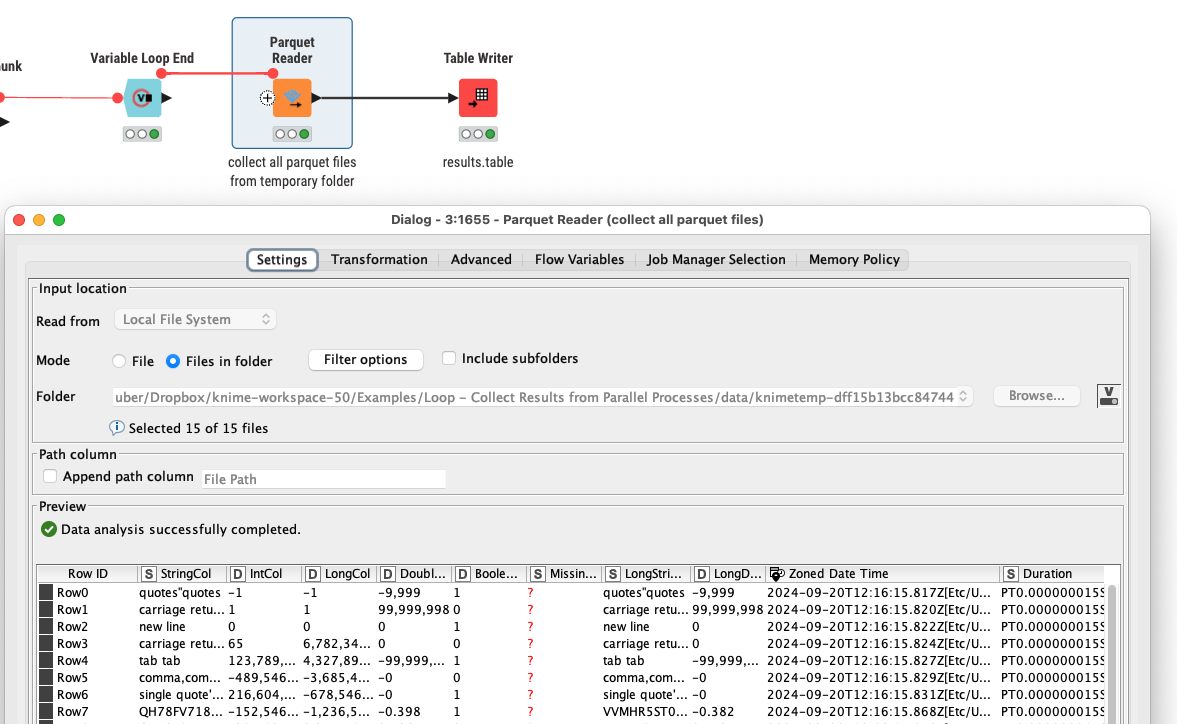
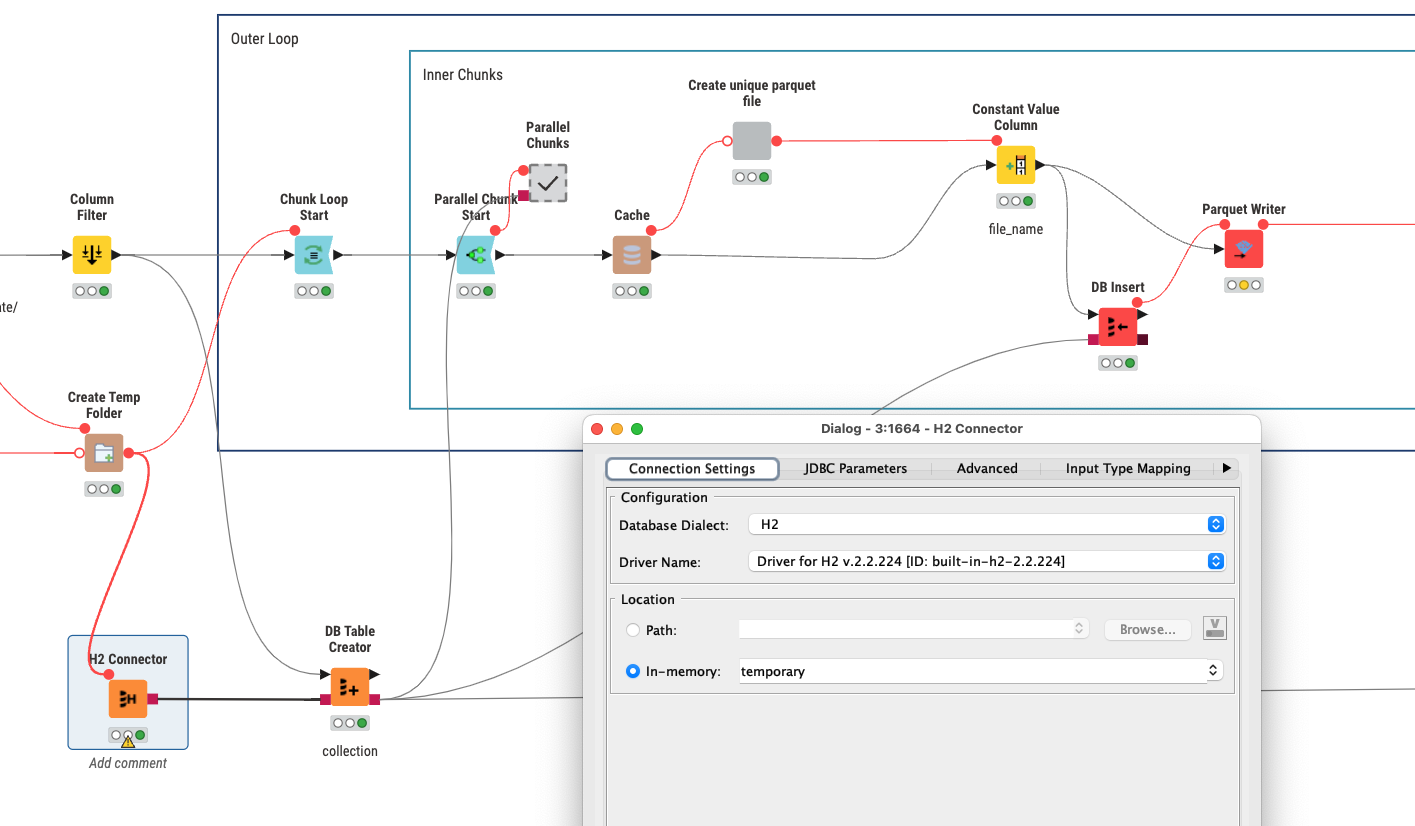
@mwiegand to be honest writing from parallel processes into the same local file is always a risk and will most likely result in failures (and this is most likely not a KNIME specific ‘bug’ but the way it is). From my perspective the best way to deal with this is to create unique file names in loop and chunk and write to individual parquet files (could also be CSV or Excel) and then import them back into a single file.
Maybe you give it a try. I will expand the workflow over time. The other thing which could work would be to collect the results in a database like H2 or SQLite which might be able to deal with parallel accesses.
yes, I have a similar approach in place but for the given scenario, it is necessary that all chunks share some sort of memory. The real life scenario is to scrape a website in parallel chunks.
Imagine you fed a list of 10k URLs to a scraping workflow. Newly discovered URLs are added to each batch. But since you divide the URLs in the first place, you end up scraping everything X-times based on the chunk count.
This might not even be a problem of parallel writing. If you write a file of large size, the write node then finish and the next iteration starts, this might very well result in the same situation … a corrupt file.
@mwiegand what you could try is use a H2 in memory database as an intermediate storage and access this storage to check if a newly find URL has already been processed. This might not be 100% reliable but it will reduce the number of duplicates
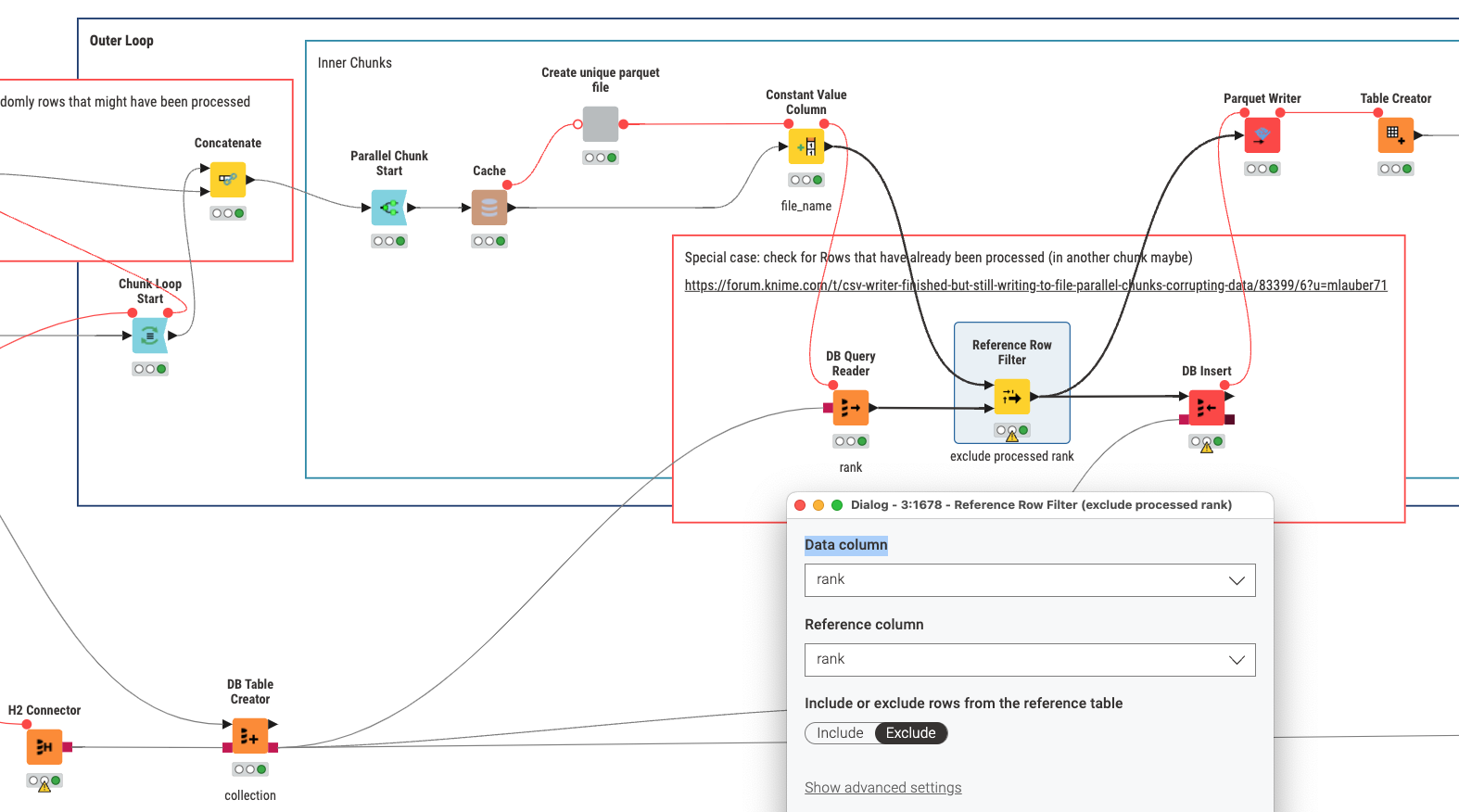
@mwiegand I inserted a test case in the workflow where for each chunk I will deliberately pull in some random additional rows (some of which might already have been processed. Before storing the data into the parquet file I pull the list of IDs (rank as a long format) from the H2 database and exclude the ones that have already been done.
This is not 100% perfect because within one chunk a row might already be in the works while it is also been processed in the new one. So out of 100 rows I will have 104 in the end producing some duplicates. But most duplicates will have been avoided.
Currently I store everything in the H2 and pull out only the rank. In order to speed things up you could work with a H2 database in memory that will just process the IDs.
This should also work if you produce some additional URLs (IDs) in the course of a chunk and then store them in the H2 database. If you choose shorter intervals this might result in less duplicates but cost more processing power.
I got another idea based on the principle to prevent running into conflict when the same file is used. I encode the data in a concatenated string, hash and write that to a directory. If another parallel chunk finds the same hash, it discards it.
Nevertheless, I’d like to better understand the described issue. @thor, apologize for dragging you in here but your superb technical feedback you once gave stuck. Any idea why the CSV writer finished writing data but other chunks still ran into conflict? Even with a two seconds artificial delay and all the logic I established with lock files …
Update: I did a few more test as I had a strong opinion that the cause is rooted in the CSV writer node.
1st approach, based on the assumption the CSV writer writes in 115-ish chunks at a time, I converted each column into a collection of one cell and converted that to a string. Result, still failure.
2nd approach, attempting to eliminate the CSV writer as a cause, using Python to write the data into the CSV. Result, SUCCESS!
I will complete the example workflow later on and provide it for everyone.
Update
Aaand finished … here is the final workflow. I will also write an article about that later on, publishing it in the knowledge sharing section as well.
I’d appreciate you feedback in case you want to have a look @mlauber71
@mwiegand using some sort of trigger or blocking file to steer executions (or prevent them) is one way to overcome limitations in some extreme cases.
In general I would strongly advise not to write to the same file in parallel regardless if you pull it off to initially get the results. I would only use dedicated systems like databases that are built to receive write operations in parallel. Depending on the operating system, the surroundings, some aggressive virus scanner some micro delays you will most likely run into troubles in a real life scenario.
Trying to deliberately break a system might be interesting to test some fringe cases. In most productive environments there is a good chance you are setting yourself up for problems that are then complicated to first detect and then to fix. When it is not super important to squeeze the last microseconds out of a process (if this is the case you might need advanced in-memory techniques) it is best to keep things so that you can easily track them, give them unique names and better rely on a loop or something so as to safely collect. Also built-in pauses and caches might sometimes go a long way to improve stability as well as (like you have done) retry and catch constructs.
The question when it comes to robust processes is not if you are paranoid - the question is: are you paranoid enough …
on another note: I currently get an error message when trying to install the Nodepit Power Nodes. I do not have the energy to investigate. I would just use the Cache node instead.
Usually system have / offer safety measures to prevent writing to the same file simultaneously. I.e. opening the same Excel file twice and writing to it usually throws an error. Though, utilizing these options seems up to the developer.
What bugs me are the safety measures taken in combination with a forced delay of two seconds still being insufficient. Even without parallel processing, it could mean by pure iteration data might get corrupted.
Or curious
I winder what the take of the Knime-Devs is on that …
My point simply is, following an „it just works“ expectation Knime users might have as Knime is so accessible, that this ease results in a false perception of safety. Though, I believe that With the ambition to ease access an „it just works“ mindset is what Knime-Devs might aim for.