New to the forum so please excuse any problems/gaps with my question.
I am looking for a way to automate the selection of different stop word lists, when different situations are at hand.
For example, if I am analyzing weather situations, ‘weather’ itself has the highest frequency and hence this needs to excluded. But if I am analyzing property damage, ‘weather’ would not appear in the stop list in that instance.
I understand the custom stop word list is a .txt format which can only contain one column, so how could I achieve such a dynamic stop-word selection?
I use two stopword files one specific for the task at hand and a generic list (in my case dutch).
The file to be used for the specific case is specified by a string input node, so that it is a simple task of pointing to the right file. See diagram below
The second “Preprocessing” metanode in the center of the workflow contains a routine to filter terms that occur either very rarely or very often. Since you’re going for terms that occur in most documents, you’ll be able to catch them using this metanode.
BTW, RAPosthumus’ solution uses the new Stop Word Filter node that is currently only available in the nightly build, in case you were wondering why your node doesn’t have a second input port
Thanks Roland, learning something new every day here at the forum.
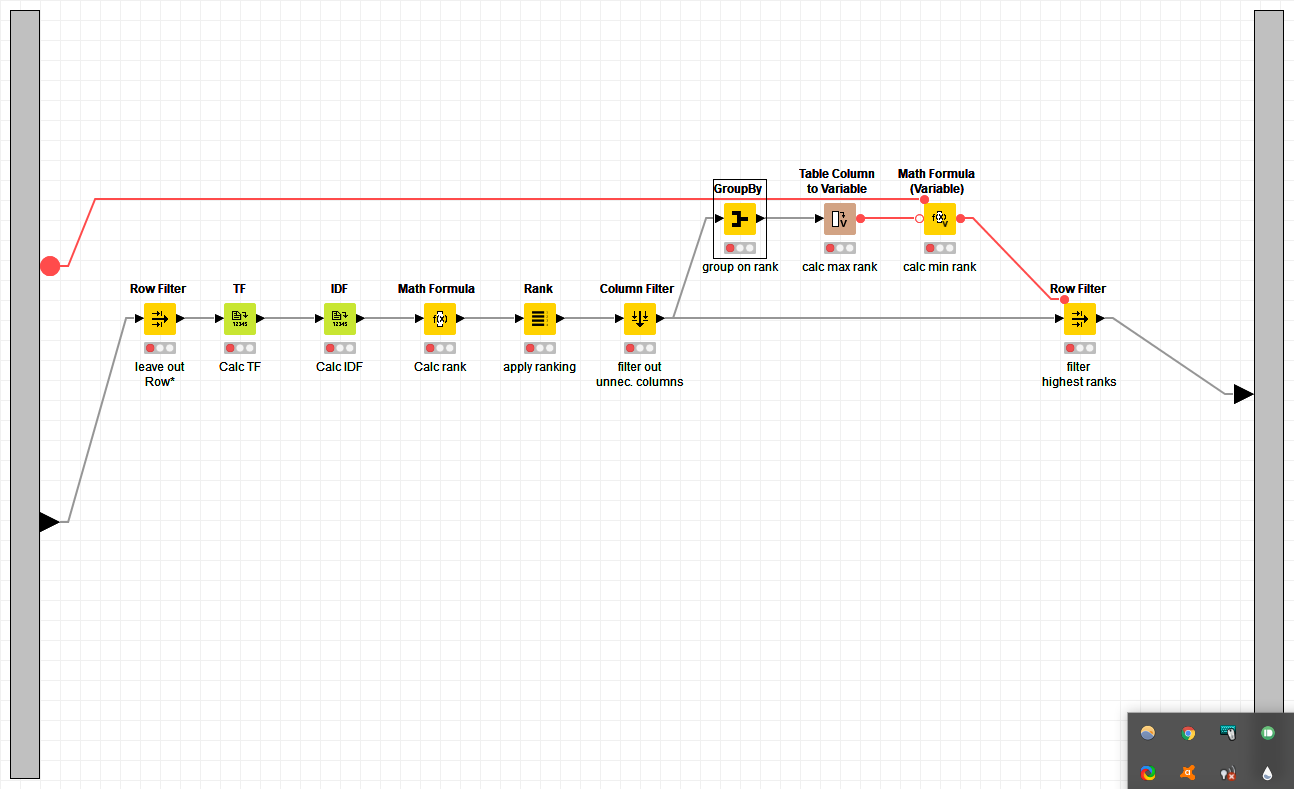
I use a two pass method: first run over all the words, calculating for every word a rank.
Next calculate a rank range (e.g. the words with two or three highest ranks) and filter on those for further processing.
Thanks so much RAPosthumus and Roland - both solutions would work well!
Out of interest, the ‘new Stop Word Filter’ RAPosthumus used is almost exactly what I was hoping for - it would allow me to loop through the file reader and select the task-specific stop word list needed for the case (without knowing Java coding). Please advise how best to get this double input stop filter - I am not sure what it means by it being only available in the nightly build.