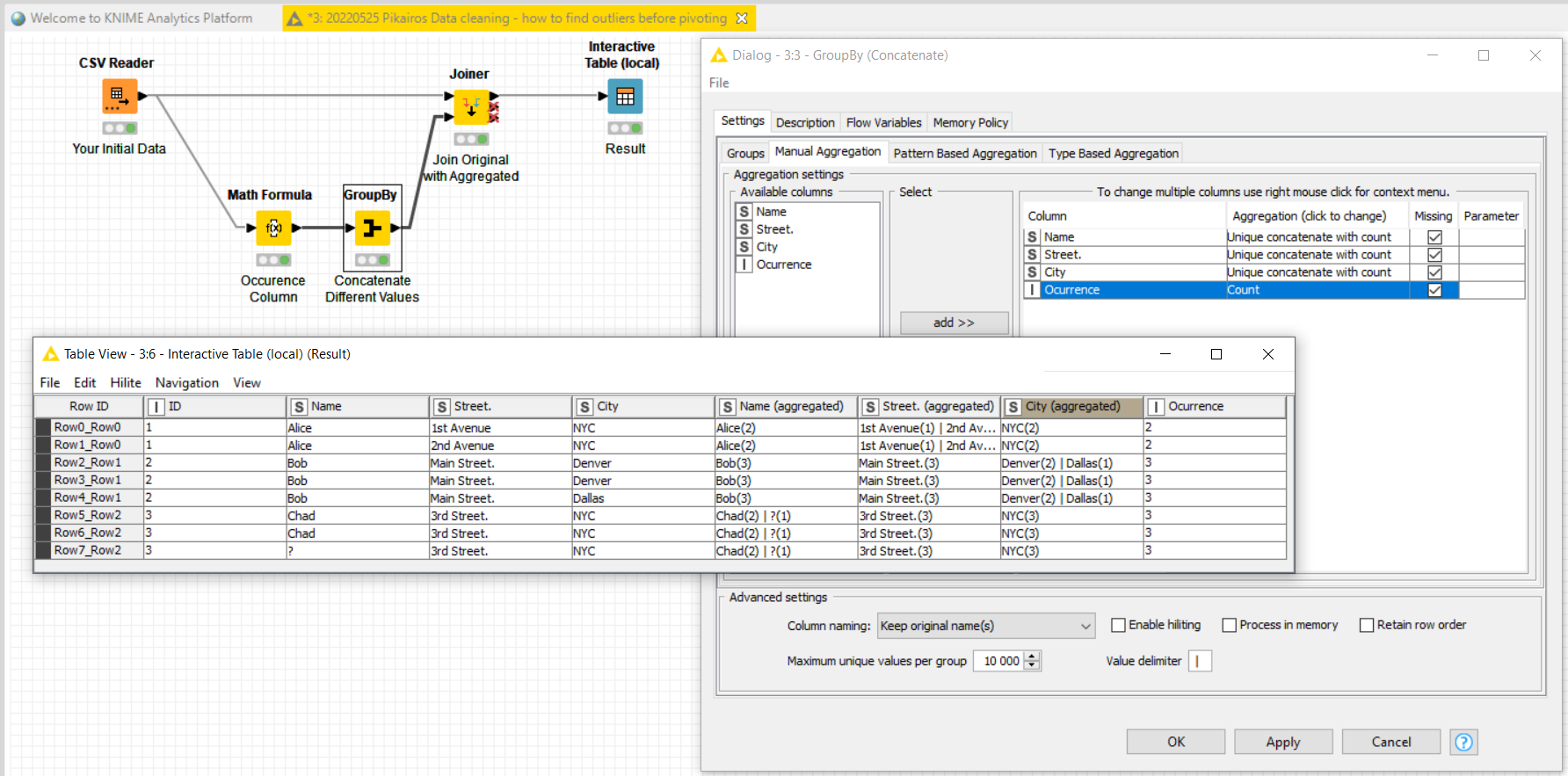
I am dealing with non-normalized data (I mean database normalization) which I want to normalize. I know the Data does contain some errors in the sense that rows which should be equal are not equel.
Here is an example
ID Name Street. City
1 Alice 1st Avenue NYC
1 Alice 2nd Avenue NYC
2 Bob Main Street. Denver
2 Bob Main Street. Denver
2 Bob Main Street. Dallas
3 Chad 3rd Street. NYC
3 Chad 3rd Street. NYC
3 ? 3rd Street. NYC
Name, Street and City column SHOULD be identical for the same ID, but are not. The street differs for ID 1, the City for ID 2 and the Name has a missing value for ID 3.
How can I find which columns differ (for the same ID)?
This is a simpliyfied example, my original data has 40 columns and a few hundred rows. I allready filtered my data so that only rows which contain errors of this type are included. But how to find which column is the culprit?
My expected result would be something like
a) an additional column for each column showing where the difference is
or
b) an additional column at the end containing the name(s) or IDs of the columns which differ
An easy way of checking for duplicates and knowing what is different among them is to do a -GroupBy- by ID and aggregate by “unique concatenate with count” ALL the other columns with a symbol as separator which is never present in any of the columns. I’m posting here a possible solution that you can customize to fit best your need:
I’m using here as separator for the concatenation the character “|” which I’m assuming for this example that it is not present in your database. You could use too a combination of characters as separator, for instance "§|§’ to make sure that you could easily identify it later to process the aggregated columns, for instance to split back the column cell content.
You can use GroupBy and Columns Aggregator node like this:
1st GroupBy node:
Add ID as group column
Add other columns as aggregation columns with Set as aggregation type, with missing values
2nd GroupBy node:
Add ID as group column
Add columns with Sets as aggregation columns with Element Count as aggregation type
Every aggregated column with number greater then 1 means that you have more then one unique value in that column for specific ID
To filter such rows use Columns Aggregator node:
select columns with Element count as aggregation columns and choose max as aggregation method → every row with max value greater then 1 is a row with ID containing more then one unique value in columns other then ID
btw: is there a tutorial on the available set functions in Knime. I thought about using group-by + set but I did not know how to further process the sets.
Usually and in terms of data type or structure, one can use the same operators as for lists and collections in KNIME. The only specificity of a set is that it is a list with sorted unique values. The easiest way is to try and see whether a given node or operator does the job when the input data is a set instead of a list or collection.
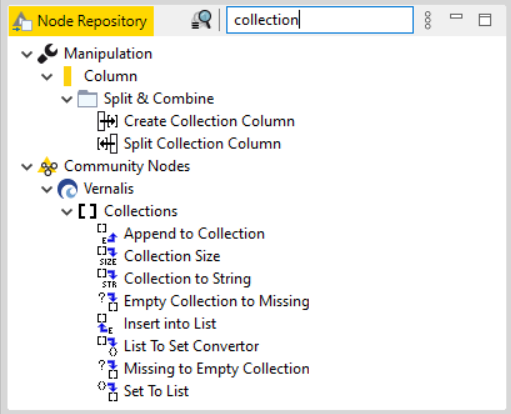
@Vernalis has a very nice plugin with nodes to specifically handle collections and convert sets to collections or lists (and viceversa) in case this would be needed a priori: