I have a PDF , in Page 2 there is a table containing an image …I want to get that table as output in excel/Gsheet. Can Somebody help me here? I am trying using Image Reader and Tess4J nodes but not making any progress.
Hi @Mayank_2611 and welcome to the forum.
This is a question that comes up now and then. Take a look a this post, maybe it can work as a starting point:
I went ahead and removed the PDF example file you uploaded since it contains personal information (names and addresses).
First step with two ways:
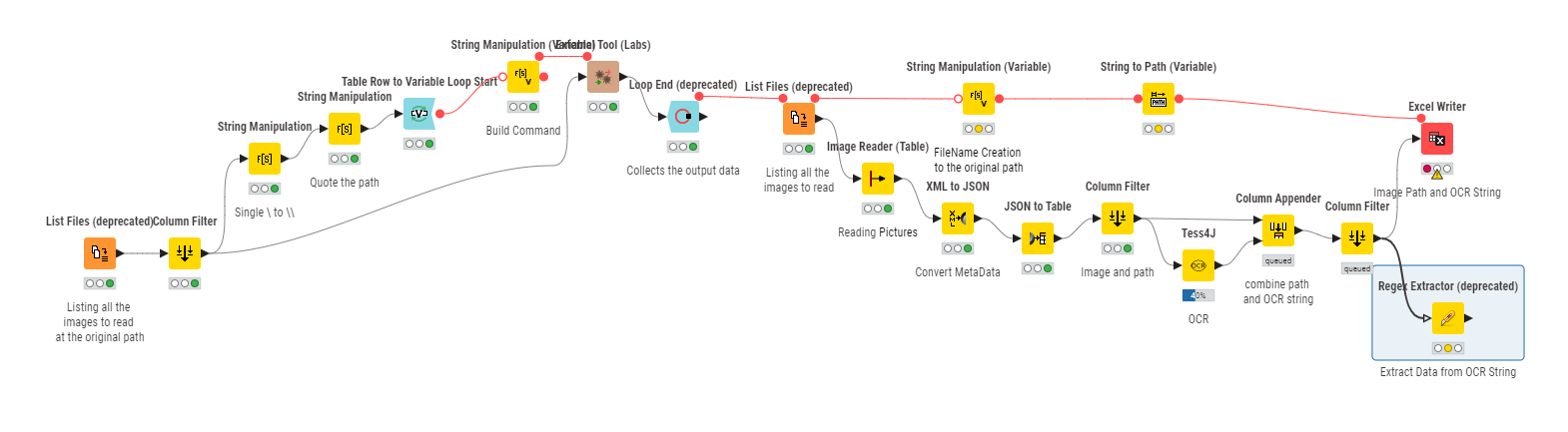
- I’m using Tikka node with embedded pictures saved to a particular folder (not running with the lastest versions of PDF with new format of embedded pictures encoding).
- I’m using a external open source and free library (poppler) to convert PDF pages into pictures saved to a particular folder.
From this folder, I create images and use Tess4J to make the OCR of pictures.
KNIME_OCR.knwf (66,1 Ko)
For new encoded embedded pictures, I search external free and open source tools.
It should be great if KNIME can create a node ![]()
1 Like
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.