First step with two ways:
- I’m using Tikka node with embedded pictures saved to a particular folder (not running with the lastest versions of PDF with new format of embedded pictures encoding).
- I’m using a external open source and free library (poppler) to convert PDF pages into pictures saved to a particular folder.
From this folder, I create images and use Tess4J to make the OCR of pictures.
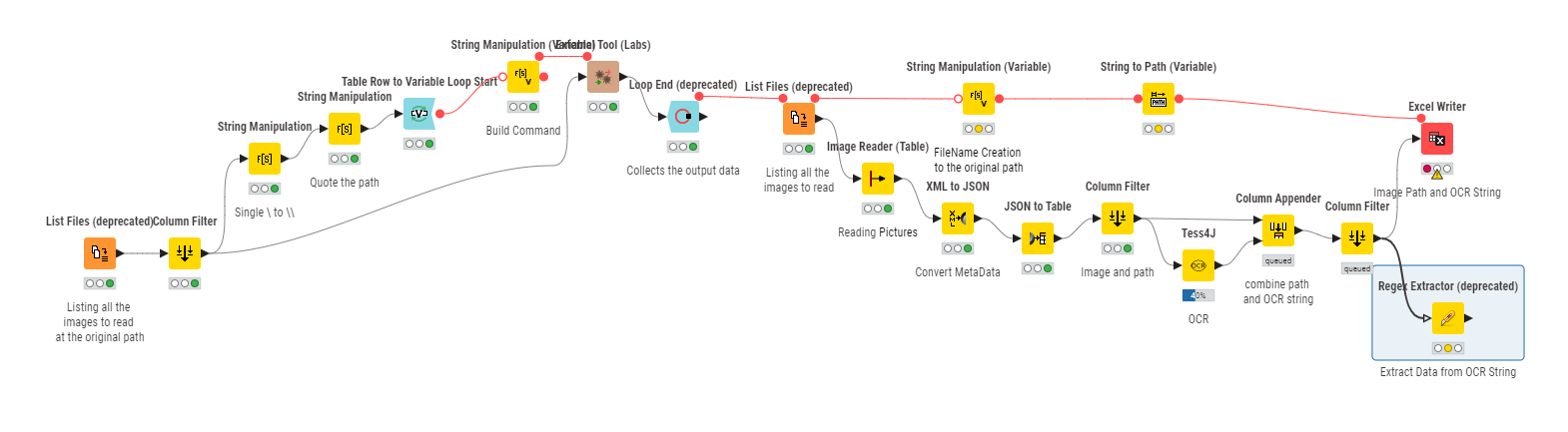
KNIME_OCR.knwf (66,1 Ko)
For new encoded embedded pictures, I search external free and open source tools.
It should be great if KNIME can create a node ![]()