Here you are:
pdf_extract.knwf (57.8 KB)
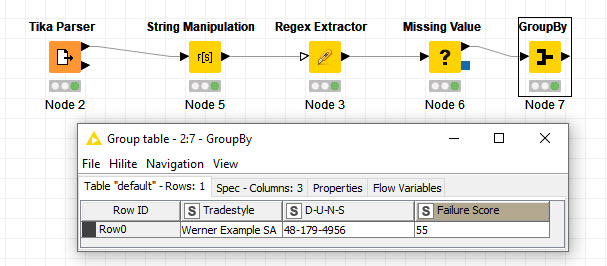
First, I removed line breaks and then used the Regex Extractor node from Palladian 2 to extract and label the values.
The GroupBy node is used to filter a column and 2 rows (which is applicable in this case). Maybe you want to use The Column Filter and Row Filter nodes instead.
