Is there any good source on the nodes / possibilities available to extract data from a PDF?
I am struggling with all the different concepts here.
In my case, which is very basic I am trying to extract a scoring number and a company name from different PDF files. The information is not in a table but in different parts of each report.
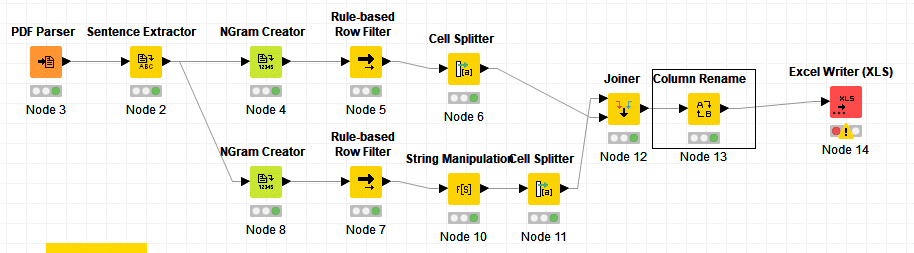
I created the flow below which seems to be working. The problem I have is to link the scores with the company names since I have failed to find an option to export together with the ngram the name of the original PDF file.
Maybe there is a better alternative workflow you could think of?
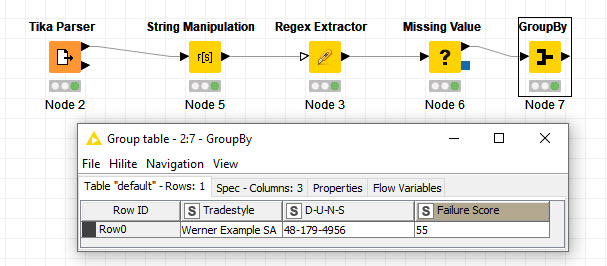
First, I removed line breaks and then used the Regex Extractor node from Palladian 2 to extract and label the values.
The GroupBy node is used to filter a column and 2 rows (which is applicable in this case). Maybe you want to use The Column Filter and Row Filter nodes instead.
I am loving the Knime forum in every way. Here are some of my queries:
Can we parse Annual reports in PDF format which includes text, tables, diagrams. Sometimes the PDF is also having some security issues and watermark which hinders the parsing.
Can we parse and extract only English words in the dictionary and leave out Sanskrit language words and names of people.
welcome to the KNIME forum! I will try to answer your questions.
Yes, you can parse PDFs. I would recommend to use Tika Parser node, which allows you to extract the text and you can extract inline images to a specific folder. The images can then be read into KNIME by using the Image Reader node. Regarding security issues, I would say just try it out. It is possible to read password-encrypted PDFs, but I’m not sure if parsing images works if they are somehow protected.
This should also be possible, but not while reading the PDF. It’s only possible to read the whole PDF, but you could go for several preprocessing nodes afterwards. For example: Sentence Extraction -> Tika Language Detection -> Row filter to remove all sentences in Sanskrit or just use the Dictionary Replacer / Replacer node to remove words you don’t need.
Thank you there. @julian.bunzel
Useful indeed.
Tika languare detector works are sentence level. Tried it.
I want at word to word level language detector. Any options?
One more query: Is there any way to check text similarity at Bi-gram with Documents
currently, there is no dedicated option for word level language detection, but what you could do:
Use the Unique Term Extractor to get a set of all terms occurring in all documents. Afterwards you can use the Strings To Document node to convert each term to a single document and then use the Tika Language Detector again which will then try to detect the language for each word. I don’t know how reliable the outcome will be, since it’s way easier to do the detection on whole sentences, but it could be a good starting point. Then you could filter based on languages you want to remove from your original documents using the Row Filter on the Language column and afterwards the Stop Word Filter to remove the remaining words from your Documents.
Bi-gram similarity: I recommend you to have a look at the NGram Creator node. It allows you to create n-grams on word and character level and as well counts the occurrences on sentence, document and corpus level. If you need every term as own column, there is also the Term Neighborhood Extractor which extracts the N-neighborhood for each term and creates a new column for each word. To calculate String distances you can use the String Distance node in combination with the Distance Matrix Calculate node.
This workflow might also be interesting for you: Fuzzy Matching of Strings.
@julian.bunzel That is useful for me. Term neighborhood extractor is a good node for NGram analysis.
I am trying something on cosines similarity and tanimoto similarity. The node description does not give me exact picture of the options available. Is there any video/workflow to see the implementation of this. Would be very useful. In that cosine distance 0 means - the documents are closest and 1 means farthest. Is that right?