I have a question regarding KNIME’s data manipulation in the machine learning process.
In KNIME it is possible to put categorical data as a column (i.e. as a string) in a ML model, without a manual preprocessing step.
I am interested in what is KNIME doing with these data in the background? Are they doing a numeric transformation or an one-hot encoding?
The following models are relevant:
XGBoost Tree Ensemble Learner
RandomForest Learner
Gradient Boosted Trees Learner
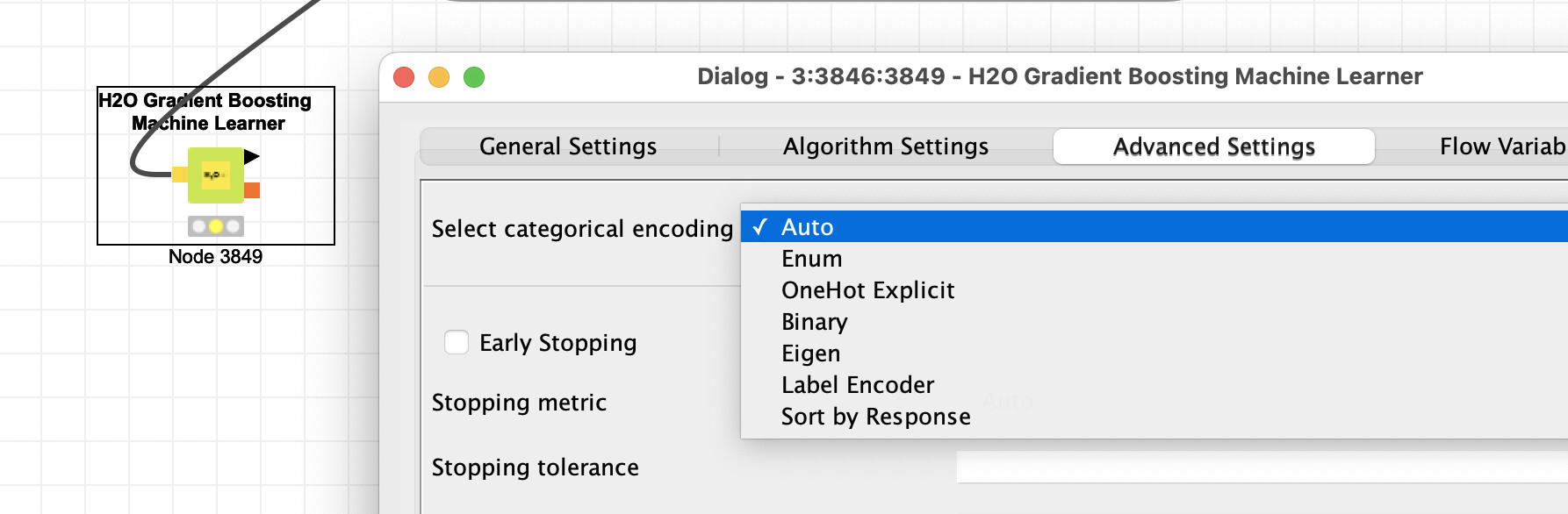
H2O Gradient Boosting Machine Learner
H2O Random Forest Learner
I would really appreciate an answer to this topic.
Hi @moritz_skb ,
Welcome to the KNIME Community!
One-hot encoding is one of the steps that could be performed. In KNIME you can try to use the One to Many nodes to achieve this.
Hi @sanket_2012
I think the question is how this is implemented within the algorithms in KNIME.
eg Trees do not need one hot encoding by default however in sklearn I think it is still required. So if someone drags a learner node into KNIME what happens “under the hood” with the data? E.g. Does it do ohe in the background or how is data handled? Detailed Documentation could be helpful if this is somewhere available
br
There you will find additional links and literature to explain what has been done. In this case to the official documentation and there you will find what the algorithm does:
@moritz_skb Apologies for the wrong interpretation.
Thank you @Daniel_Weikert for pointing it out and @mlauber71 for jumping in with the detailed explanation.
@moritz_skb Let us know if you have any other queries.