Hello,
As KNIME stores intermediate data on disc under the workspace folder, is there any setting to disable this and only save the data in the memory?
To save the HD space, I know way to remove the folder after workflow finished. Well looking for ways to improve the speed during the node-to-node processing.
when you save the workflow you can check the reset box in the bottom left.
but there are some nodes mentioned in this thread which maybe will help you.
Btw, what about the memory release? Sometimes working with long work flow and big data. When the data has been transferred to the post node, is there any way to release the memory in the previous node? thank you.
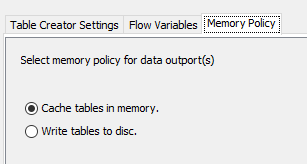
as far as I know nodes should “release memory” on their own, because the data which is currently used is stored in the memory and nodes are working the data of the previouse node. if you like to reduce the memory usage, then you can switch to "write tables to disc"in the “memory policy”-tab in the node.
but i don’t know how huge the impact is, because i never used it really.
Hello @ipazin
The streaming function is great. This is what I’m looking for.
I test it by a WF, and it saves 60% process time.
And thanks for the blog, now I understand how the KNIME process data node by node.
Well, when I try another one, shown up a warning as below:
Original flow:
Component with Stream:
So, Loops node are not supported by simple stream, right?
loops are not supported in streaming mode. Now thinking about it that makes sense, doesn’t it? See here how to parallelize (seems parallelization is actually what loops need) Group Loop:
As a general comment loops are extremely slow in knime. So the best performance optimization one can do is to find a way to not need the loops. What are you doing with a double group oop start by and math node? can’t you do that with 1 or 2 groupby nodes?