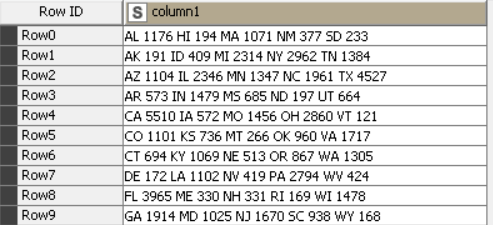
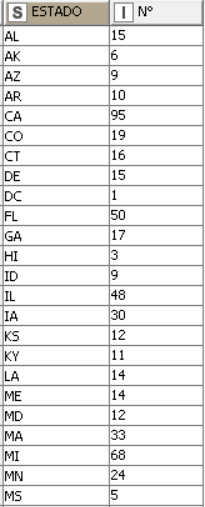
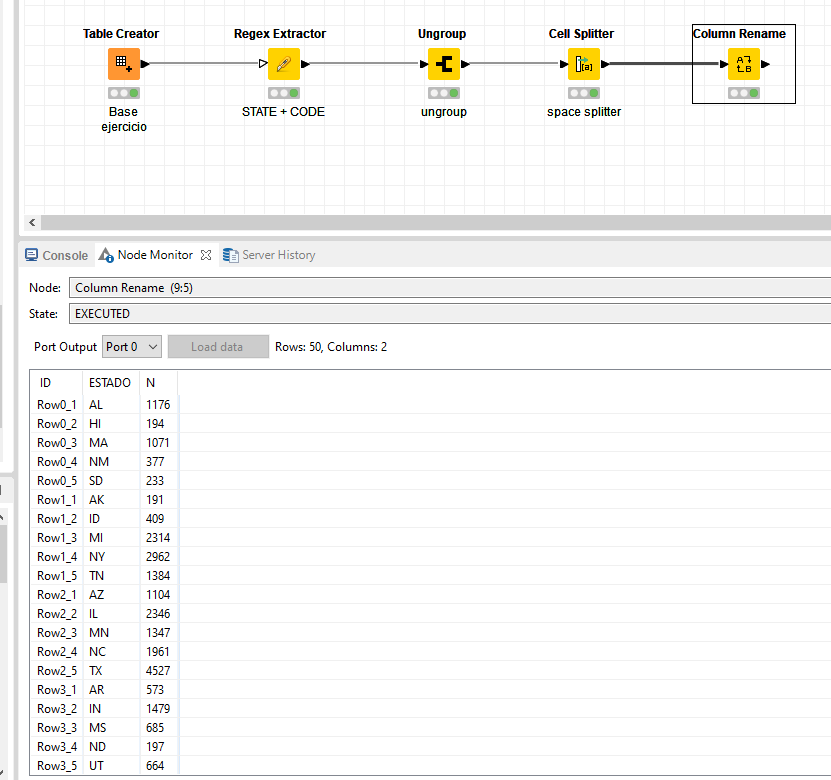
I see now You can approach this in multiple ways. One way is through regex extraction by using the associated Regex Extractor node (Regex Extractor — NodePit).
Thank you very much @ArjenEX for the help, have an excellent end of the week
I cannot find the node that was used, I looked for it in the repository without success, from what I understand it is deprecated and I don’t know where to look for it or what would be its replacement, do you know how to install it?