Hi @davidbaker, my guess is similar to @mlauber71 's.
In the attached workflow I have a table containing two rows that I have manually keyed in:
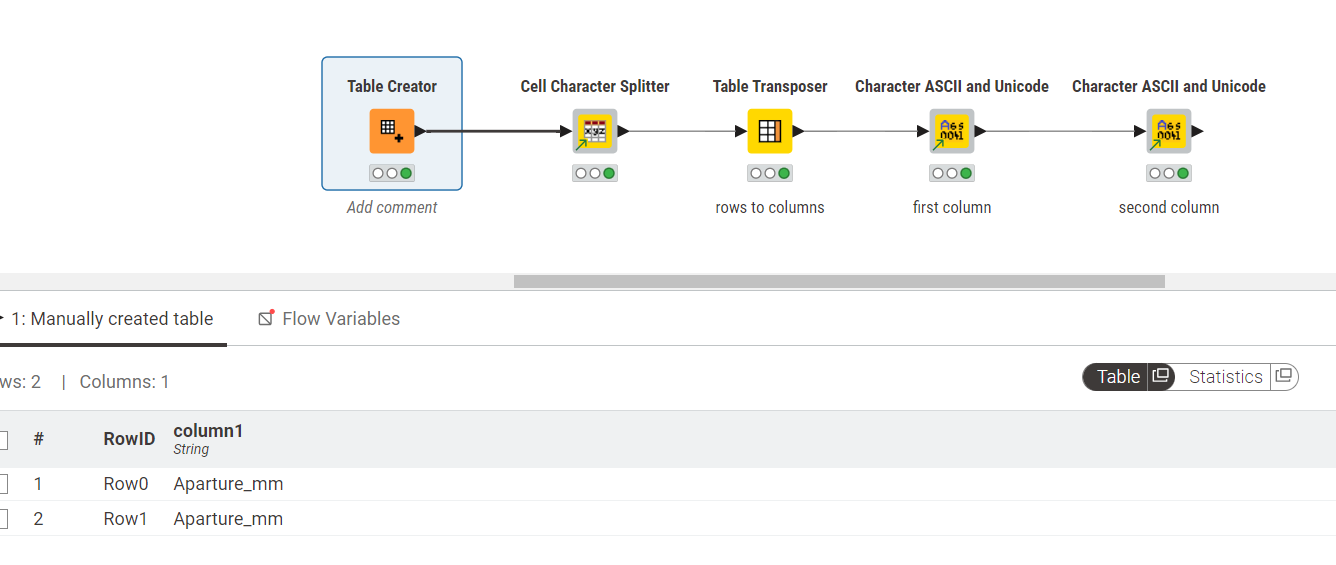
Although the data appears to be the same in both rows, it isn’t. Row 2 contains a regular “e”, but row 1 contains a “Cyrillic e” (item 2 on the below list from my chatGPT conversation)
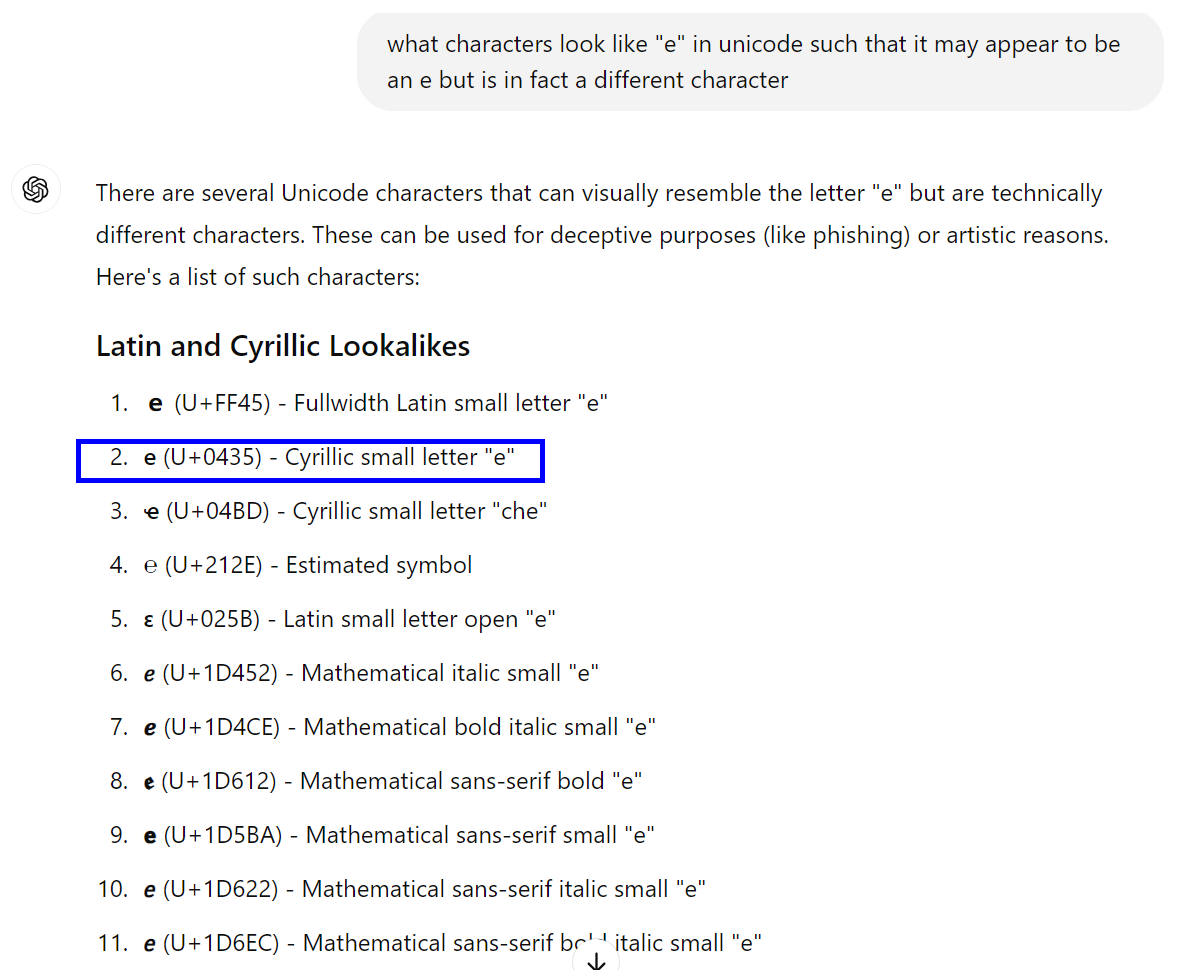
If it is an “encoding” or “character set” thing, then it is possible that this may appear as unrecognised in SQL Server.
I’ve used a couple of my components to help identify where the “e” characters differ:
This workflow generates the ascii and unicode codes for each character. It may be of assistance if you feed in the offending row in you actual data.
Here you can see that the codes for the “e” character transposed from Row0 are outside of the regular western character set range.
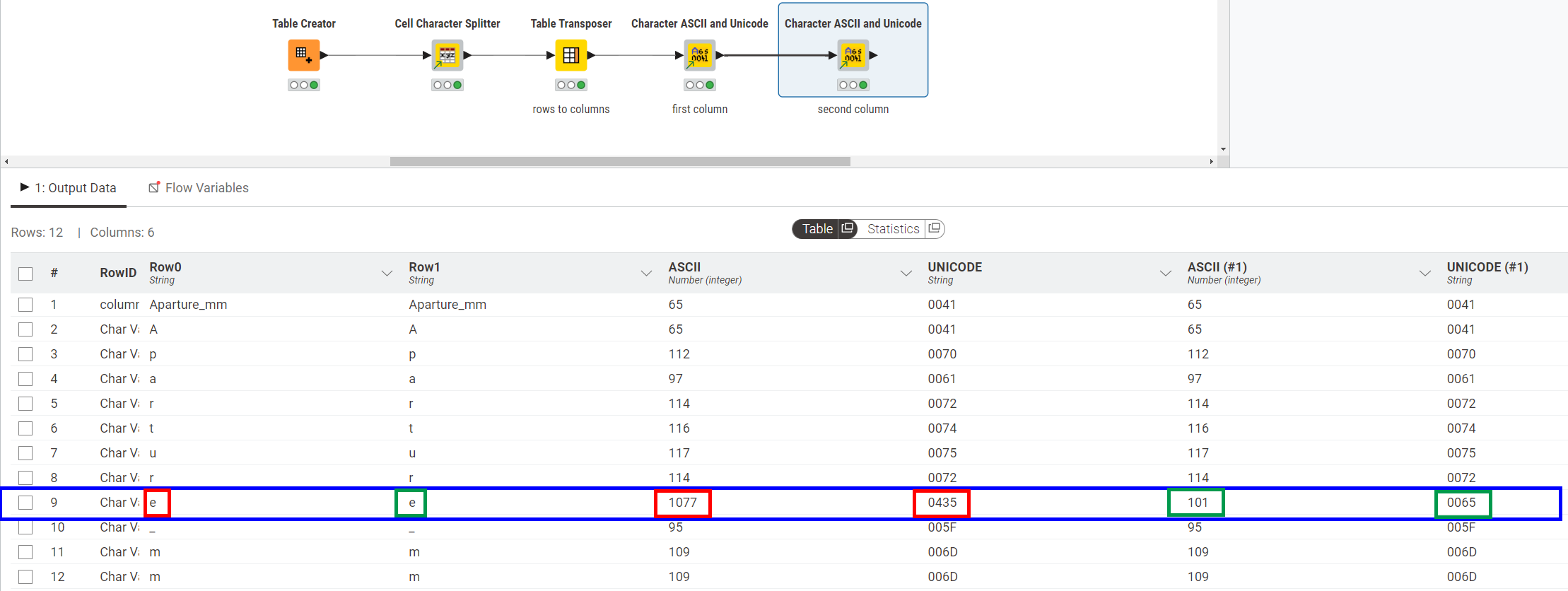
Investigate Characters in data.knwf (113.1 KB)
Of course, if it is this, I’m afraid I don’t have any clues about how it came to be in your data! ![]()