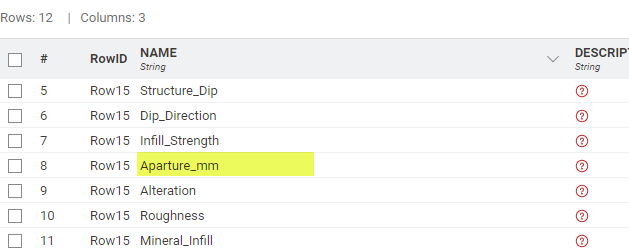
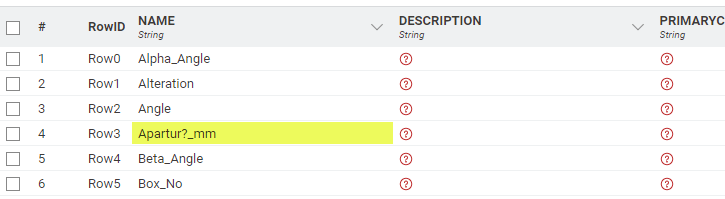
I am seeing some very peculiar behavior that I can’t wrap my head around. I’m inserting some data into a SQL database using the DB Insert node. There is a single string value in my table that gets written incorrectly every time I try. For some reason, it converts the string “Aparture_mm” to “Apartur?_mm”.
Hi @mlauber71 , good question. It’s a MS SQL database (2019, case insensitive if that matters).
I’ve not noticed it happening with any other strings.
I found that if I change the value to something slightly different, it inserts without any issue, so I am just going to accept this workaround and move on for now.
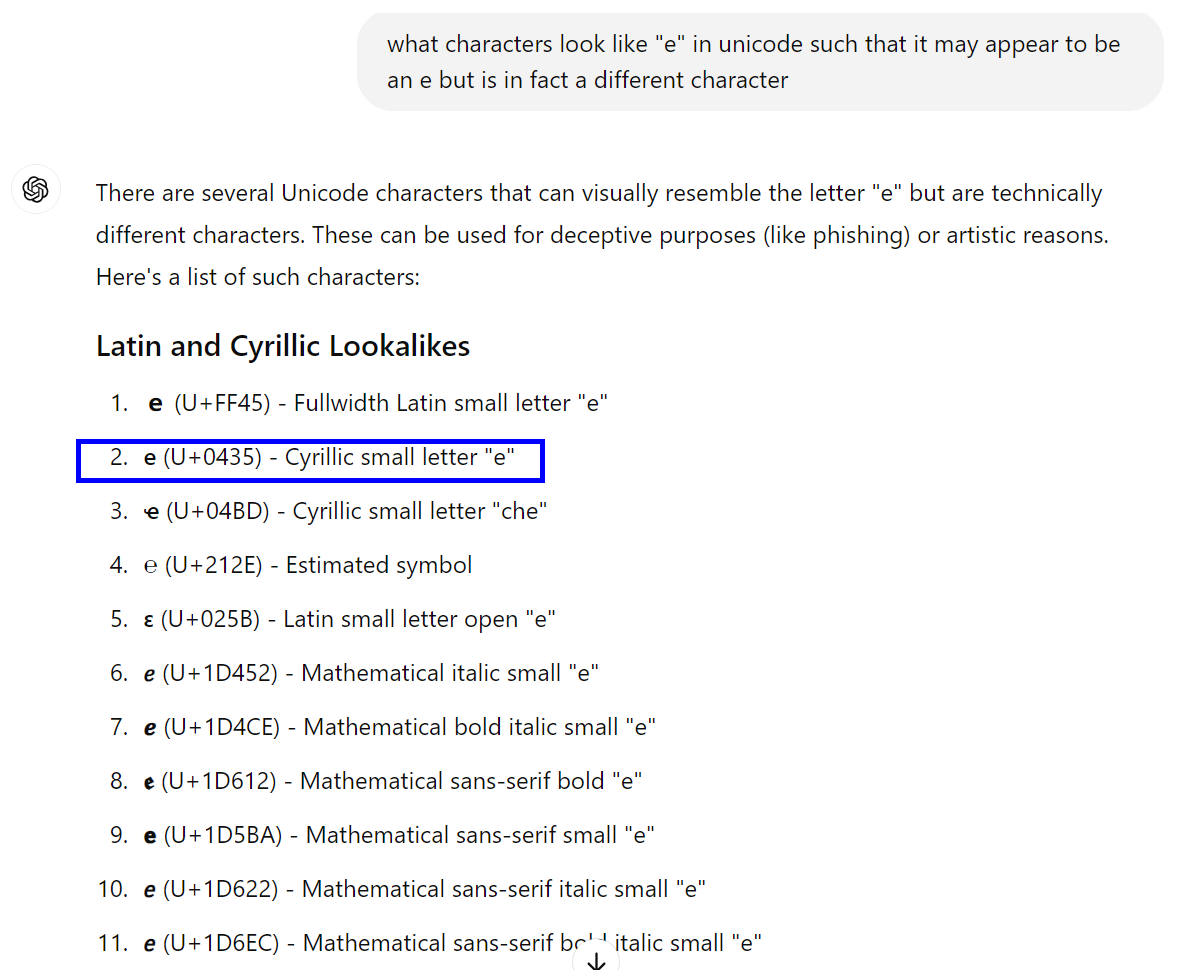
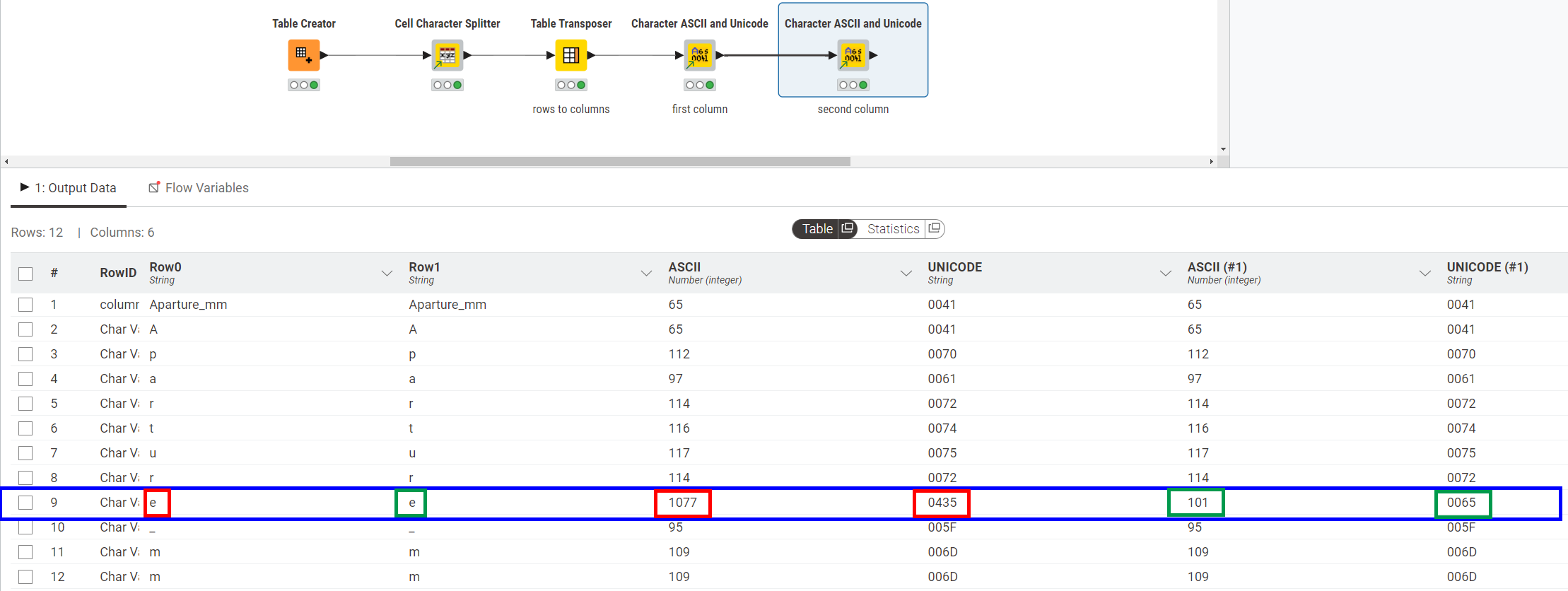
Although the data appears to be the same in both rows, it isn’t. Row 2 contains a regular “e”, but row 1 contains a “Cyrillic e” (item 2 on the below list from my chatGPT conversation)
Wow, this community is amazing. Thank you both (@mlauber71 & @takbb ) for taking the time to investigate, and provide such detailed replies. I have no doubt that your assumptions are correct, and it is an issue with the encoding (something that I know pretty much nothing about).
Unfortunately I have edited the dataset, to eliminate the offending record, and now I can’t reproduce it. So I can’t confirm it with the components you’ve provided.
Looks like the issue is with character encoding. Some special character in the string might be causing it to change to a question mark. Since you’ve already fixed it by editing the dataset, it might not happen again. But if it does, you can use the tools shared here to check the character’s encoding.
@Neha_Kakkar wow I never knew this could happen - can you explain again how the tools like Correlation Filter or Range Slider Widget can help address this?
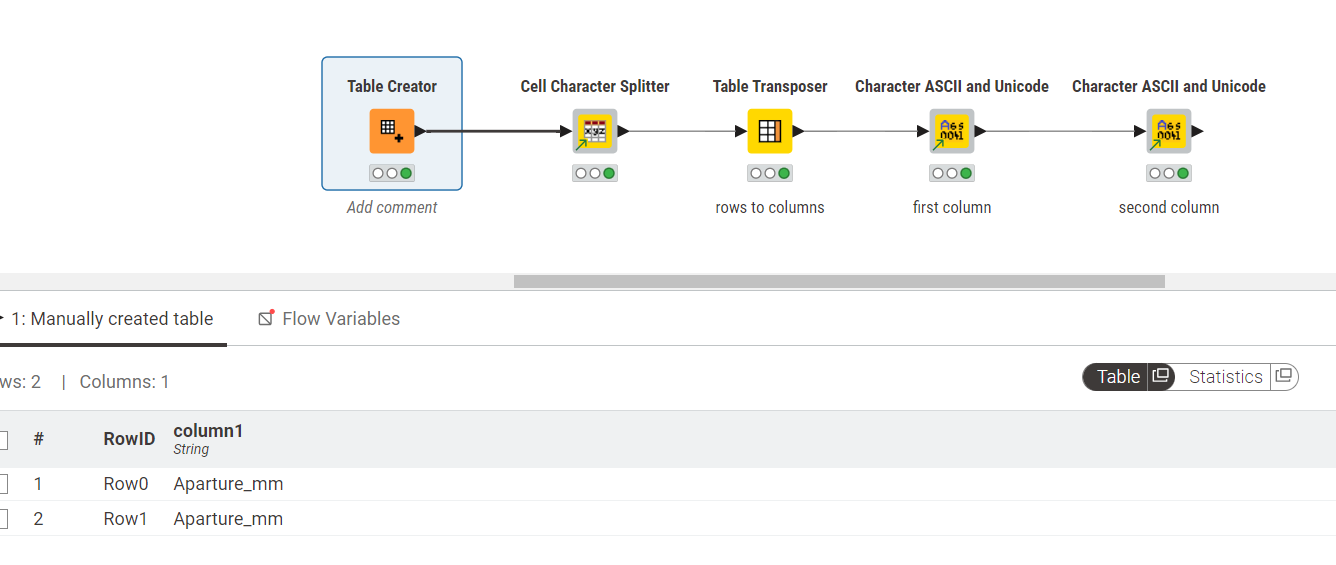
Hi @MartinDDDD, I think you misunderstood. I was talking about the tools shared by @takbb, like ‘Cell Character Splitter’ and ‘Character ASCII and Unicode.’ These tools can break the string into characters and show their encoding. They help find any unusual characters causing the issue.
No problem. The ‘Cell Character Splitter’ and ‘Character ASCII and Unicode’ might not be built-in KNIME nodes. They could be custom nodes or part of an extension. You can check the KNIME Hub or forums to find them.
I understand that there is a string, and for some reason, the letter “e” causes an issue.
Should the correction be made within the database? In other words, in the database column where the information will be stored (by altering the column type)?
Off-topic: now GenAIs are really becoming cyber-garbage generators. You can easily find misleading information on the web. Hilariously, GenAIs are continuously being fed with the garbage they’ve produced.
Disclaimer: not relevant to the reply until he/she make a choice of a or b😉
To be fair, I think the previous reply pointed to the workflows in this reply: