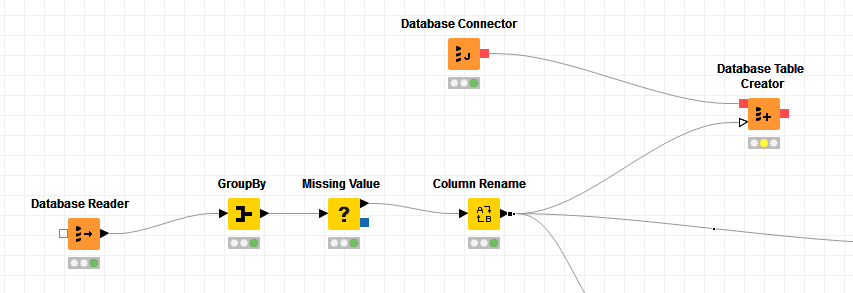
This sounds like a type mismatch between your table structure, and the data you’re trying to populate the table with - but it’s hard to tell without seeing the workflow or the data. Something about the data in column 50 is not playing nice. Can you provide any additional information?
(Also, if you have access to KNIME 4.0, you might consider using the new DB nodes, which give you additional control over variable types.)
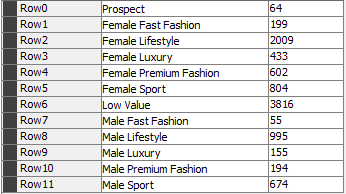
The first column is a string (Varchar(255)) and the second column is an integer column highest value is 3816.
The database that I’m trying to create the table in is Apache Hive. I believe I have the appropriate jdbc driver. I can create a table using SQL in the database reader node.
Can you post the data and a sample workflow (or at least a screenshot)? I can try to recreate it using KNIME’s Local Big Data implementation.
EDIT: Corey made a good point that the column 50 here probably references the 50th character in your varchar string. You likely have an unescaped special character in your data.
Hmmm. Nothing about that data looks unusual. I guess it’s possible there could be a hidden TAB character or some other weird whitespace issue that wouldn’t show up in a screenshot.
Have you tried using the DB nodes - instead of the Database nodes - to see if this strange error persists?
The new nodes I’m referring to are available in KNIME 4.0, and include the following you might want to try in your workflow (of course, there are many other DB nodes too):
Hello ray_pruett,
as far as I know Apache Drill only supports table creation via a select statement. For details see the Drill documentation´. These tables you can create with the Database Connection Table Writer node.
If you want to create a table in Apache Hive with the Database Table Creator you need to use the Hive driver e.g. using the Hive Connector to connect to Hive. For more details on this see the KNIME Big Data documentation.
Bye
Tobias
Hi Ray,
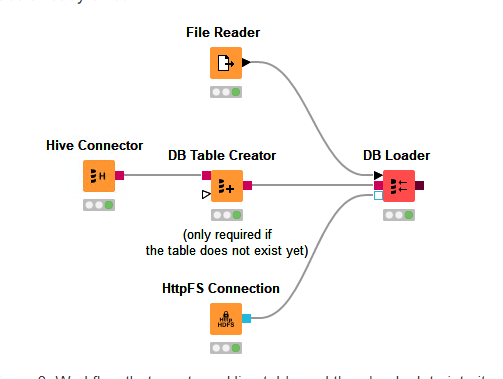
yes the DB Loader needs the HttpFS connection to upload the data to the HDFS file system prior moving it into the Hive table. However as far as I know the MapR implementation of httpFS is based on an old implementation from Cloudera which in some cases has problem with our client implementation.
Bye
Tobias