I was wondering if there have been any updates on a database union node that could perform unions in database? As opposed to having to read the queries into knime and concatenate them. I saw this older topic on the forum https://forum.knime.com/t/database-concatenate-node/4713 where Iris mentions that a node like this will be released in the near future. Then a few years later (2018) she mentions it will be in the next release but I can’t seem to find a node that will do this. It looks like there are a lot of other people who would be interested in this functionality.
Thank you in advance for any clarifications or updates on this!
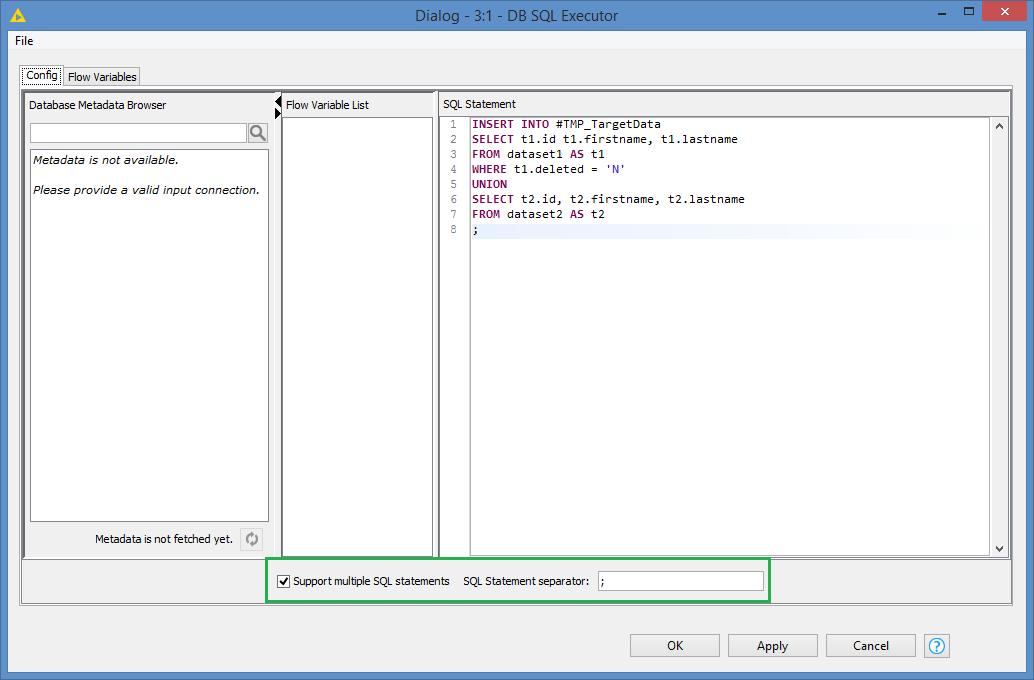
SELECT t1.id t1.firstname, t1.lastname FROM dataset1 AS t1 WHERE t1.deleted = 'N' UNION SELECT t2.id, t2.firstname, t2.lastname FROM dataset2 AS t2
And if you want to simulate the Knime Concatenate node, you’d use “UNION ALL” instead of “UNION” (UNION ALL does not remove duplicates, just like the Concatenate node, while UNION ALL does)
Thanks for the response @bruno29a!! Unfortunately that won’t work for my particular scenario because I’m trying to speed up a calculation that I’m currently doing in knime by recreating it on the database side so I need to have two separate branches of database nodes (both reading from the same DB connector) and union the two branches back together. I’m trying to avoid reading data into knime until I get to the point in my logic where I do a large group by so I’m reading less data in and it would be faster.
Currently I’m trying to write everything out in just raw SQL statements but when I keep chaining DB query nodes together it makes the syntax very strange and difficult to debug. I’m sure I can figure out how to format the SQL correctly as I chain them together but life would be a whole lot simpler with a DB UNION node. I was secretly hoping I am missing a node that was added already but at the very least would love to know if this is still on the roadmap for a future update .
Hi @Kaegan , no problem. I’m not sure that node exists, but I could be wrong.
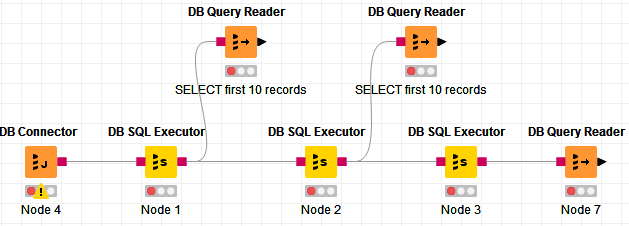
As an alternative, you could use temporary tables and do your db manipulation on the db side on the temporary tables, and then bring the data to Knime once the data is manipulated.
You could do your db manipulation, including creating the temporary tables via the DB SQL Executor node:
You can chain multiple of them, or you can actually run multiple queries in the same node (you can declare a delimiter for the queries, such as semi-colon).
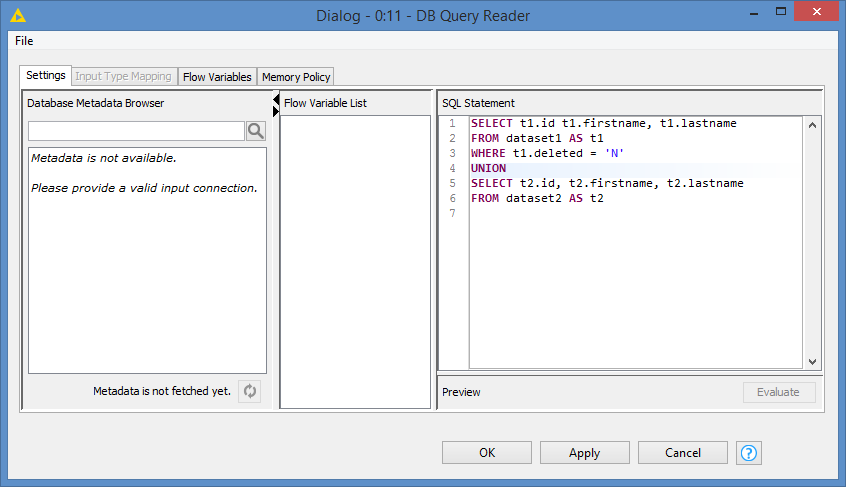
You can send your UNION’ed data into a temporary table and then keep playing with the data. In between the DB SQL Executor nodes chain, you can fork to DB Query Reader and run SELECT statements to check on the data should you need a preview or debug the queries:
We do have a couple of tickets for this in our system (internal reference: AP-11366 and AP-5752). This has come up a few times in recent weeks so I know our DB developers are aware of it.
Let me add a +1 from you on those tickets. Thanks for the feedback - it helps us prioritize future features.
From this I understand you are using a set of DB … nodes which do help you in constructing a complex SQL statement through these nodes. As you mention the actual SQL statement which is executed by Knime becomes pretty awful to read (and debug).
From my SQL experience I know that if performance is important, you really have to put the extra mile into the SQL statement yourself. Using these easy-to-use chained nodes will never be able to get the same performance as an own written SQL statement. These chained nodes will often produce subselected tables and the more you have of those the odds increase you performance will degrade.
But the main drawback in writing it yourself is that you need to know how to do this. This relies not only on SQL knowledge, but also on knowledge of your database (and tables in it) and which performance optimizations have been placed into it which you could use like
are there indexes you could use (execution plans can be helpful in pointing this out to you)
or might it be better to create an index to support your query
can you create temporary tables (even possibly with an index)
Dependening on the database there are different mechanisms which can help you getting a better performance.
So a DB Union node might be easy to use, but if it will give you the required performance in the end is a completely different story.
Thanks for the update @ScottF and thank you for the feedback @JanDuo!
I only wanted to chain together the nodes like that to keep myself sane because it’s going to turn into a pretty large query but I believe you are correct that if I want to take full advantage of the performance increase I’ll have to write it custom. I have already started scripting it out in one DB Query Reader node.
Thanks again for the quick support and advice everyone!!
often it might help if you could write out intermediate tables with joined results that you would later use to continue your work. So you are also able to check what your results are at certain points.
This of course very much depends on what database you are using (how large the data is) and what privileges you have (are you allowed to write temp tables). The type of database also is important since some databases have built in query optimizers while some have not. Some (like Big Data systems) expcet that you work with partitions while other DBs might just do the job for you.
 but at the very least would love to know if this is still on the roadmap for a future update
but at the very least would love to know if this is still on the roadmap for a future update  .
.