I have 17,000 tables with four columns and approximately 3,000-8,000 rows for each table. I am new to databases in knime, and I would like a simple example on how to create a database and import all those tables. Tables are created through a workflow and a variable that includes url links, and the resulted tables are string and double numbers.
I would appreciate any directions or tutorials or workflow examples for a knime beginner.
Thank you
2 Likes
First question would be so you want to set up a real database or just use a local one like SQLite or H2 and how big your 17.000 files would be altogether.
Would they all go into one DB or separate files. If it so happens that we are talking about the coordinates from this debate the offer for a Dropbox download link still stands ![]()
Maybe you explain a little more what you want to do
SQLite
H2, they exist in memory or on disc. The later would be for you
Hive (big data)
You can use a local example but if you need more power might have to switch to a real dB
To familiarise yourself with the concept I set up this:
If you want to read multiple files like CSV into a data base I came up with this example using Hive although I am not sure how it would scale up on a local machine.
If you need more power fast you could think about buying resources with KNIME on AWS. But my experience with that is limited
For data base connections in general there is the
KNIME Database Extension Guide
https://docs.knime.com/2019-06/db_extension_guide/index.html
2 Likes
Hello, this sounds like fun. KNIME can do this a lot of ways, depends how you want to do it. That many tables will take time, limit the input and test on 10 tables at the start. Even a more simple use case can lend an easier development environment, where the widgets need to be changed subtly VS re-engineered, a power of KNIME is this prototyping capabilities VS building the “production ready” database app that you need. With that said, my example will be more remedial but carry the same tools you need to complete the task/tasks.
Where are you today?
Have you automated building the SQL yet? This can be done with KNIME, and could be a good first step into looping through the database, although they make tools for this I’m sure. (im new too)
What’s going to be the way you do it? Have you made a decision on how you want to do it in KNIME? There’s going to be a lot of ways to do it.
You can use knime to automate writing SQL, or automate changing just the Table in the SQL code… then you use knime to run through each chunk, a looping process, each chunk of SQL can run through the tool. With every loop you push data where you want it to go.
Example solution; i built a python app that stores files in .txt, I later get a list of these file names and iterate it through a file reader… The same can be done with databases, iterating over a list of table names for example, and in the loop, you can migrate the data to another database or table.
url2 = “https://twitter.com/itylergarrett”
driver.get(url2)
r = requests.get(url2)
h = r.text
t = time.strftime("%Y%m%d-%H%M%S")
f = open(‘C:\Users\tyler\Desktop\scrape\profile’+t+’.txt’, “w”)
f.write(h.encode(‘utf8’))
This above is how I check my twitter page increase/decrease. This knime process below only grabs a few rows of the HTML today, however I want to store the HTML in a .txt format and change to something cool tomorrow.
Python bot makes files that have unique identifiers, using date/time + dimension call outs.
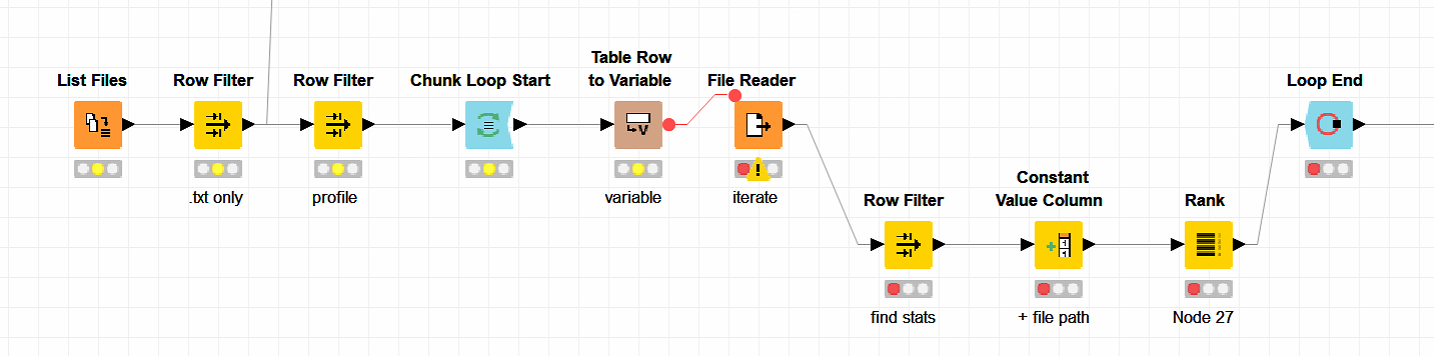
Above KNIME process explained
- list of files, or list of databases/tables/etc, to be used in the blue “chunk loop start”
- filter to what you want, i’m filtering to text files
- filtering more, i wanted a place to also filter unique identifiers in the app, it’s okay to have multiple things to clean up your pipeline.
- blue chunk loop start, set your chunks (amount to process per run) depending on your need
- table row to variable turns my column into something I can use on the FILE READER tool orange
- file reader, this is the tool you will be “looping” your SQL through, if that’s the path you choose
I like the flexibility of a tool that can process databases into other databases, it’s a smart way to start finding correlations and better labeling your data, without heavy lifting.
Good luck.
Best,
Tyler
3 Likes
This topic was automatically closed 182 days after the last reply. New replies are no longer allowed.