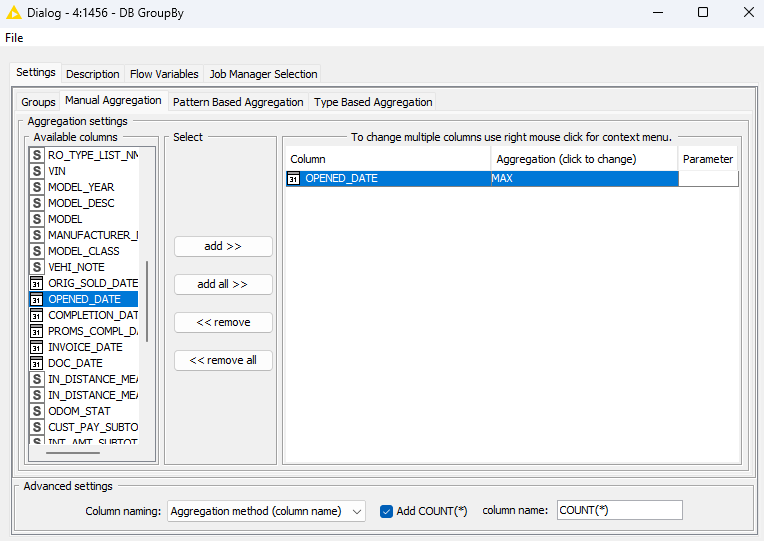
I’m using Knime v5.1.2 with the latest DatabricksJDBC42-2.6.36.1062 driver. I’m finding that the DB Group by node is throwing an error when trying to use any of the aggregation functions on the Manual Aggregation tab. Possible bug with interacting with Databricks? Work as expected with other DBs. Does not appear to generate the correct SQL when using Databricks looking at the console log.
Creates SELECT * FROM (SELECT COUNT() AS COUNT() FROM (SELECT * FROM catalog.schema.table)
Count function works as expected when generated via manual SQL.
SELECT count(*) as count_rows FROM catalog.schema.table
Thanks for getting back to me Sascha. The Group By node works as expected if I only add fields to the Group tab but adding any type of manual aggregation causes the node to throw an error with Databricks. I don’t even get an option to run the node, I get this message>
WARN DB GroupBy 4:1456 java.sql.SQLException: [Databricks]JDBCDriver ERROR processing query/statement. Error Code: 0, SQL state: 42601, Query: SELECT * F***, Error message from Server: org.apache.hive.service.cli.HiveSQLException: Error running query: [PARSE_SYNTAX_ERROR] org.apache.spark.sql.catalyst.parser.ParseException:
[PARSE_SYNTAX_ERROR] Syntax error at or near ‘(’.(line 1, pos 45)