Hi all, I wanted to understand how can i manage the following:
I have a query which works as a model to build a large data set.
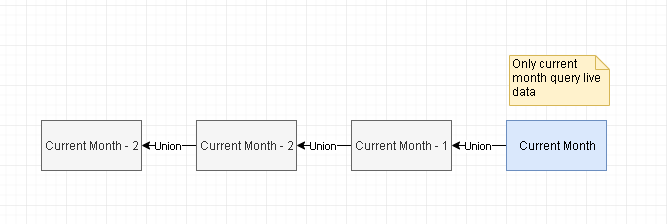
The query has a year/month parameter and always run 1 month at once because it is a lot of data.
The query is instanced 12 times to build a full rolling year data set, the 12 individual result sets are unioned into one.
The query does not need to refresh past months, only current month in process, so once queried past months are cached in disk and reused from there, unless the cache needs to be rebuilt.
Can you sugest me how can i build a query i can instantiate and how can i cache result sets with the capability of refreshing them?
For building a query (I suppose it is a DB query) you should use database nodes (https://nodepit.com/category/database). For query parameterization in order to get data only for current month you can use flow variables. To union data use Concatenate node. Once you got all 12 month data together in KNIME save it locally in .table format which is KNIME internal format (https://nodepit.com/node/org.knime.base.node.io.table.write.WriteTableNodeFactory). Now when you go to second iteration and read data for new month you should also read previous 12 month you saved locally. Filter only last 11 from it using some of KNIME filtering nodes (https://nodepit.com/category/manipulation/row/row-filter?page=1&limit=15) and union with new data you just read. Save that data again.
Responses were very creative, I’m marking this one as correct because is the most general approach that could also apply to other ETL technologies.
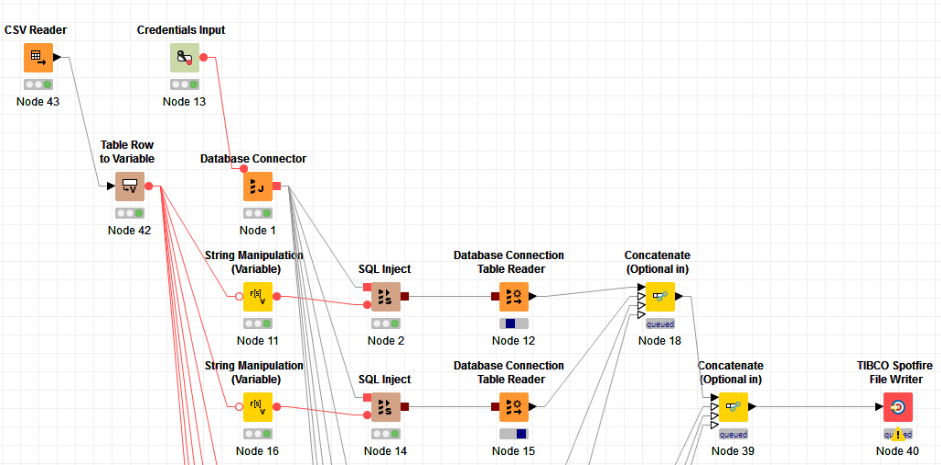
I’m creating a parameterized query in a txt file, then i load it into a variable and do a string manipulation to replace the parameters with the desired values.
I’m planning to run 11 months in one branch of the flow and the 12th month in a second branch, conditioning the execution of the branches in any switch node that gives me the desired behavior.