Hi Forum,
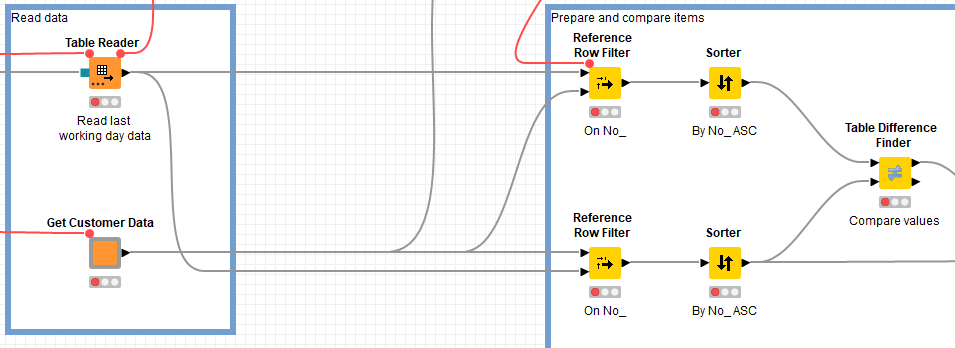
I’m trying to find a way to do version control on a set of data that is updated very regularly. So not the workflow in Knime but the data that is imported. For example, within the dataset there are a number of fields and these fields consists of different field types for example Text Fields, Picklists, Date Fields etc. These fields can be changed from time-to-time and I have to evaluate which fields have changed when the data is imported. This is where I need to do version control, in order to determine which fields have been added, deleted, edited etc.
I have tried doing this with a series of joiner nodes where I was able to join the old dataset to the newest dataset and evaluate the differences in the fields.
Is there a better way of doing this?