Hello KNIME Support.
When using the Pyspark Script node, the format of the Date & Time column is forcibly reformatted when exported to a dataframe in the Output Port.
In the image below, when I run the code within the Pyspark Script node, the Date & Time format of the Date column is output as 2010 - 02 - 05 00:00:000.
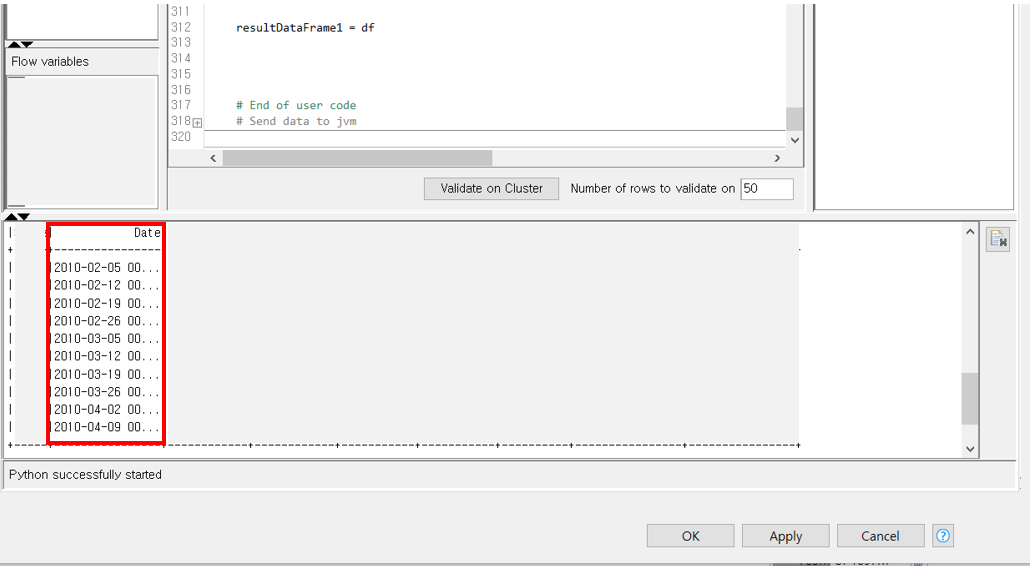
However, when you run that Pyspark Script node and export the spark.dataframe through the Output port, the Date column changes to the following.
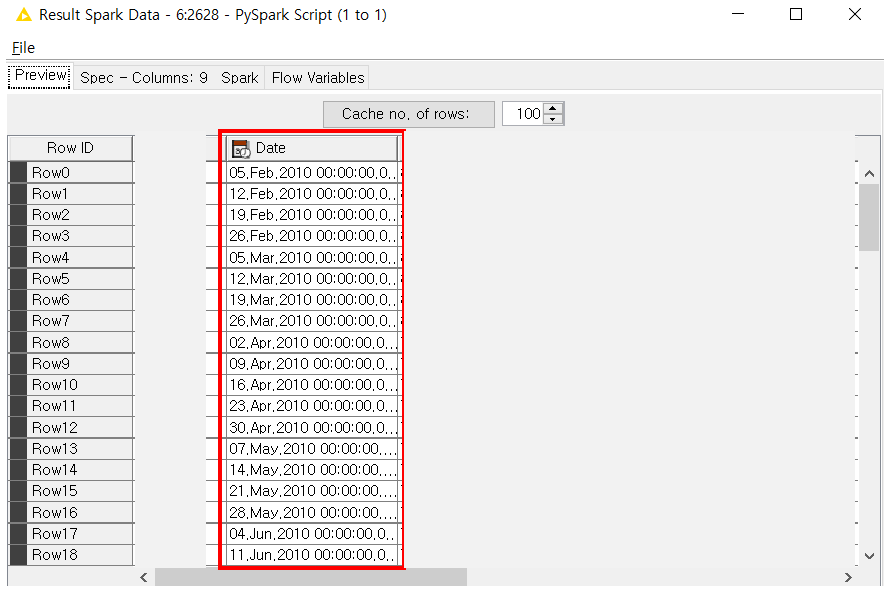
I need to use the format “2010 - 02 - 05 00:00:000”, which is the format of the Date column derived when executed inside the Pyspark Script which is the format of the Date column when executed from within the Python script, but the output is not what I want.
To change the column to the format I want, I need a node for Spark’s Date & Time conversion, which doesn’t exist.
Also, I can’t convert this to Spark to Table and use the Date & Time conversion node because the amount of data is so large that it would be very inefficient to convert it to table and preprocess it.
Unfortunately, I can’t share the code and data used due to ongoing customer security issues.
Is there a way around this, or is it simply an unsupported format within Pyspark Script?
Any answers would be greatly appreciated.