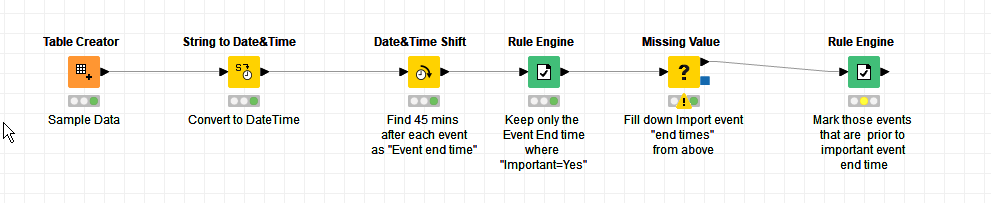
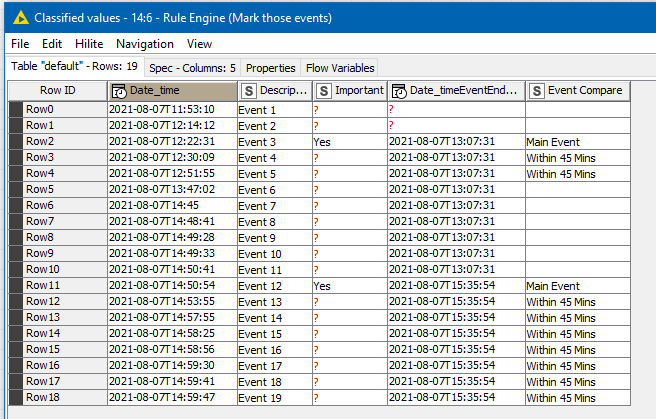
One approach to this is to calculate the time 45 minutes after each event, and then keep only those marked “important=yes”. After that a Missing Value node can be used to “Fill down” the “important event end time”, and you can then compare the time of each event with the last “important event end time” using a Rule Engine.
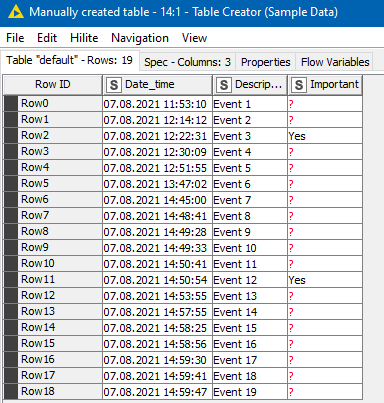
(I’ve assumed your dates are dd.mm.yyyy format, but if they are mm.dd.yyyy format you’ll need to change the format mask in the String to Date&Time node)
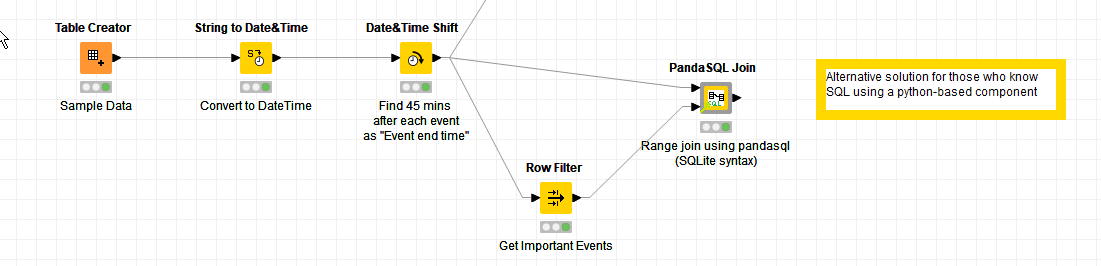
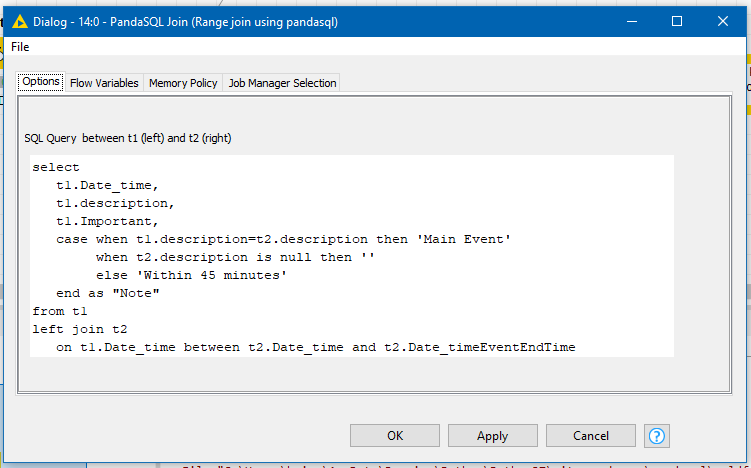
Just as an additional option, I don’t know if you have python installed, and know SQL… but one of the common issues with general joining in KNIME is “range comparisons”. This can be overcome using SQL, and I put together a component a while back to assist in such situations.
In the attached workflow, I’ve added an example of my PandaSQL Join component. So here, it takes the dataset and performs a sql join between “all rows” and just the important event rows.
 . Can anyone help me please with an idea how to make the next step …
. Can anyone help me please with an idea how to make the next step …