Members of the KNIME community,
I would like to clarify a doubt about truncated data. I have the following flow of nodes for a 7GB CSV document with UTF-8 characters and string and numeric columns.

MySQL Connector node has string → VARCHAR data type mapping. When running the Table Reader (CSV) node set, MySQL Connector, and DB Table Creator, they are completed without restrictions. However, on DB Insert I get the message: Data truncation: Data too long for column.
MySQL Connector node has data type mapping: String → VARCHAR. When running the Table Reader (CSV) node set, MySQL Connector, and DB Table Creator, they run without restrictions. However, on DB Insert I get the message: Data truncation: Data too long for column.
By consulting the threads in the community, I identified three different ways to solve this issue:
-
Change the data category: MySQL Connector → Output Data Mapping → String → LONGVARCHAR. However, when running the DB Table Creator node with this change, the message is: Execute failed: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'longvarchar, …
-
Use the DB Loader node to read massive data, instead of DB Insert. When rebuilding this stream of nodes with this change, the first three nodes are executed, but DB Loader fails with the message: Execute failed: Invalid utf8mb3 character string: '“901 جينوا ب ينوا بوليفار س ينوا باوث '”.
-
Adjust characters in DB Table Creator node → Table Creator Settings → Columns. Unfortunately, my database is not editable, as the image below suggests (similar to item 1).
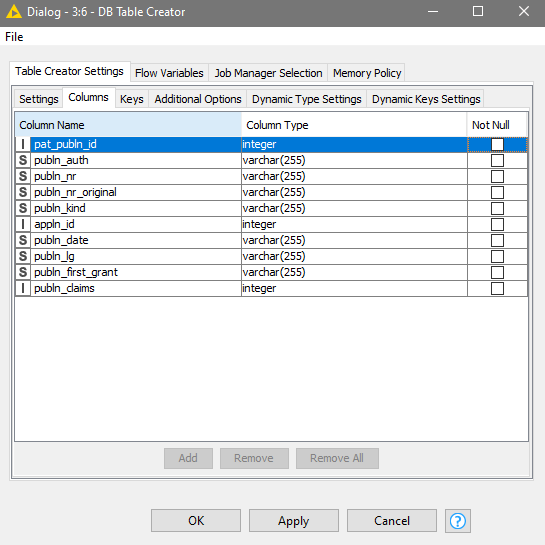
As the data is non-editable I would like to know if there is any solution to run the node set.
Regards.