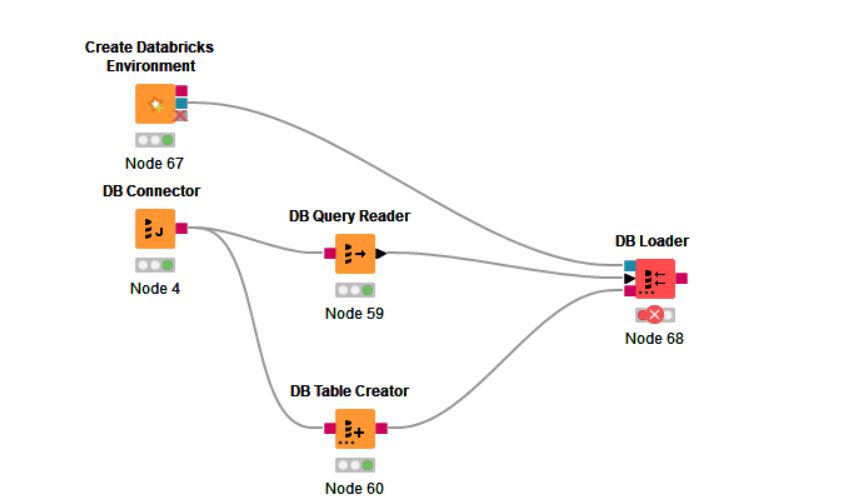
I’m trying to write to a table in Databricks. I understand that it is not possible to use insert, so I am using DB loader, but I am getting a nullpointerexception on “java.util.Map.get(Object)” before even executing the node. What could be ther problem? I hve tried updating all components to the latest version.
Hu Sascha! Thank you for your reply. I managed to solve one error by using the DB connection from the “Create Environment” node instead. However, I now got another error: “[UC_DATASOURCE_NOT_SUPPORTED] Data source format hive is not supported in Unity Catalog.”
Do you have any idea what that could be?
Here is the full output from the console:
ERROR DB Loader 5:68 HiveThriftServerErrors.scala:48)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.$anonfun$execute$1(SparkExecuteStatementOperation.scala:693)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at com.databricks.unity.UCSEphemeralState$Handle.runWith(UCSEphemeralState.scala:41)
at com.databricks.unity.HandleImpl.runWith(UCSHandle.scala:99)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.org$apache$spark$sql$hive$thriftserver$SparkExecuteStatementOperation$$execute(SparkExecuteStatementOperation.scala:571)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation$$anon$2$$anon$3.$anonfun$run$2(SparkExecuteStatementOperation.scala:422)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at com.databricks.logging.UsageLogging.withAttributionContext(UsageLogging.scala:420)
at com.databricks.logging.UsageLogging.withAttributionContext$(UsageLogging.scala:418)
at com.databricks.spark.util.PublicDBLogging.withAttributionContext(DatabricksSparkUsageLogger.scala:25)
at com.databricks.logging.UsageLogging.withAttributionTags(UsageLogging.scala:470)
at com.databricks.logging.UsageLogging.withAttributionTags$(UsageLogging.scala:455)
at com.databricks.spark.util.PublicDBLogging.withAttributionTags(DatabricksSparkUsageLogger.scala:25)
at com.databricks.spark.util.PublicDBLogging.withAttributionTags0(DatabricksSparkUsageLogger.scala:70)
at com.databricks.spark.util.DatabricksSparkUsageLogger.withAttributionTags(DatabricksSparkUsageLogger.scala:170)
at com.databricks.spark.util.UsageLogging.$anonfun$withAttributionTags$1(UsageLogger.scala:495)
at com.databricks.spark.util.UsageLogging$.withAttributionTags(UsageLogger.scala:607)
at com.databricks.spark.util.UsageLogging$.withAttributionTags(UsageLogger.scala:616)
at com.databricks.spark.util.UsageLogging.withAttributionTags(UsageLogger.scala:495)
at com.databricks.spark.util.UsageLogging.withAttributionTags$(UsageLogger.scala:493)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.withAttributionTags(SparkExecuteStatementOperation.scala:64)
at org.apache.spark.sql.hive.thriftserver.ThriftLocalProperties.$anonfun$withLocalProperties$8(ThriftLocalProperties.scala:161)
at com.databricks.spark.util.IdentityClaim$.withClaim(IdentityClaim.scala:48)
at org.apache.spark.sql.hive.thriftserver.ThriftLocalProperties.withLocalProperties(ThriftLocalProperties.scala:160)
at org.apache.spark.sql.hive.thriftserver.ThriftLocalProperties.withLocalProperties$(ThriftLocalProperties.scala:51)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.withLocalProperties(SparkExecuteStatementOperation.scala:64)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation$$anon$2$$anon$3.run(SparkExecuteStatementOperation.scala:400)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation$$anon$2$$anon$3.run(SparkExecuteStatementOperation.scala:385)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1878)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation$$anon$2.run(SparkExecuteStatementOperation.scala:434)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
Caused by: org.apache.spark.sql.AnalysisException: [UC_DATASOURCE_NOT_SUPPORTED] Data source format hive is not supported in Unity Catalog.
at com.databricks.sql.managedcatalog.ManagedCatalogErrors$.datasourceFormatNotSupported(ManagedCatalogErrors.scala:269)
at com.databricks.sql.managedcatalog.ManagedCatalogErrors$.throwIfDataSourceFormatNameIsNotSupported(ManagedCatalogErrors.scala:262)
at com.databricks.sql.managedcatalog.ManagedCatalogCommon.validateTableDefinition(ManagedCatalogCommon.scala:738)
at com.databricks.sql.managedcatalog.PermissionEnforcingManagedCatalog.createTable(PermissionEnforcingManagedCatalog.scala:81)
at com.databricks.sql.managedcatalog.ProfiledManagedCatalog.$anonfun$createTable$1(ProfiledManagedCatalog.scala:173)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.sql.catalyst.MetricKeyUtils$.measure(MetricKey.scala:319)
at com.databricks.sql.managedcatalog.ProfiledManagedCatalog.$anonfun$profile$1(ProfiledManagedCatalog.scala:55)
at com.databricks.spark.util.FrameProfiler$.record(FrameProfiler.scala:94)
at com.databricks.sql.managedcatalog.ProfiledManagedCatalog.profile(ProfiledManagedCatalog.scala:54)
at com.databricks.sql.managedcatalog.ProfiledManagedCatalog.createTable(ProfiledManagedCatalog.scala:173)
at com.databricks.sql.managedcatalog.ManagedCatalogSessionCatalog.createTableInternal(ManagedCatalogSessionCatalog.scala:768)
at com.databricks.sql.managedcatalog.ManagedCatalogSessionCatalog.createTable(ManagedCatalogSessionCatalog.scala:704)
at com.databricks.sql.DatabricksSessionCatalog.createTable(DatabricksSessionCatalog.scala:225)
at org.apache.spark.sql.execution.command.CreateTableCommand.run(tables.scala:206)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.$anonfun$sideEffectResult$1(commands.scala:82)
at com.databricks.spark.util.FrameProfiler$.record(FrameProfiler.scala:94)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:80)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:79)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.executeCollect(commands.scala:91)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$$nestedInanonfun$eagerlyExecuteCommands$1$1.$anonfun$applyOrElse$3(QueryExecution.scala:272)
at org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:166)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$$nestedInanonfun$eagerlyExecuteCommands$1$1.$anonfun$applyOrElse$2(QueryExecution.scala:272)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withCustomExecutionEnv$8(SQLExecution.scala:274)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:498)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withCustomExecutionEnv$1(SQLExecution.scala:201)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:1113)
at org.apache.spark.sql.execution.SQLExecution$.withCustomExecutionEnv(SQLExecution.scala:151)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:447)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$$nestedInanonfun$eagerlyExecuteCommands$1$1.$anonfun$applyOrElse$1(QueryExecution.scala:271)
at org.apache.spark.sql.execution.QueryExecution.org$apache$spark$sql$execution$QueryExecution$$withMVTagsIfNecessary(QueryExecution.scala:245)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$$nestedInanonfun$eagerlyExecuteCommands$1$1.applyOrElse(QueryExecution.scala:266)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$$nestedInanonfun$eagerlyExecuteCommands$1$1.applyOrElse(QueryExecution.scala:251)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$1(TreeNode.scala:465)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(origin.scala:69)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:465)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan.scala:33)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:316)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:312)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:33)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:33)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:441)
at org.apache.spark.sql.execution.QueryExecution.$anonfun$eagerlyExecuteCommands$1(QueryExecution.scala:251)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.allowInvokingTransformsInAnalyzer(AnalysisHelper.scala:372)
at org.apache.spark.sql.execution.QueryExecution.eagerlyExecuteCommands(QueryExecution.scala:251)
at org.apache.spark.sql.execution.QueryExecution.commandExecuted$lzycompute(QueryExecution.scala:203)
at org.apache.spark.sql.execution.QueryExecution.commandExecuted(QueryExecution.scala:200)
at org.apache.spark.sql.Dataset.(Dataset.scala:262)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.$anonfun$analyzeQuery$2(SparkExecuteStatementOperation.scala:565)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:1113)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.$anonfun$analyzeQuery$1(SparkExecuteStatementOperation.scala:536)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.getOrCreateDF(SparkExecuteStatementOperation.scala:526)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.analyzeQuery(SparkExecuteStatementOperation.scala:536)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.$anonfun$execute$5(SparkExecuteStatementOperation.scala:607)
at org.apache.spark.util.Utils$.timeTakenMs(Utils.scala:669)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.$anonfun$execute$1(SparkExecuteStatementOperation.scala:607)
… 36 more
What JDBC driver are you using? It might help to use a recent Databricks JDBC driver. You can find more information about installing the driver here: KNIME Database Extension Guide
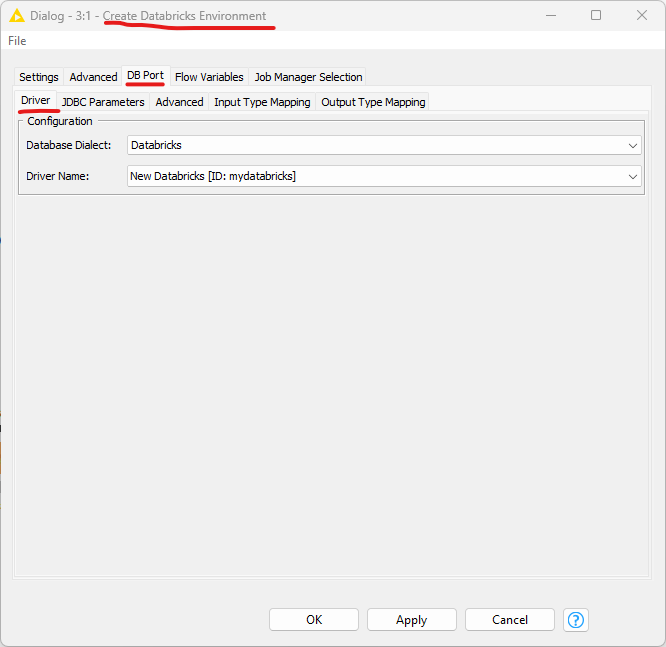
can you please make sure that the Create Databricks Environment uses the registered Databricks driver. To do so open the node dialog and go to DB Port->Driver and it should show the name of the Databricks driver that you registered
Hello @davidminer ,
unfortunately so far we weren’t able to reproduce the problem and also couldn’t find any information regarding the error message. Could you please get in touch with the Databricks support to ask them if they have an idea what this error message means:
[UC_DATASOURCE_NOT_SUPPORTED] Data source format hive is not supported in Unity Catalog
KNIME is executing the following statements to upload the data:
LOAD DATA INPATH '/tmp/knime2dbf677cd8cccf44206.parquet' INTO TABLE `default`.`test_09187358_adac_4784_b207_3e54d0ebc378` ;
INSERT INTO TABLE `hive_metastore`.`default`.`test` SELECT column0,column1,column2,column3,column4 FROM `default`.`test_09187358_adac_4784_b207_3e54d0ebc378` ;
DROP TABLE `default`.`test_09187358_adac_4784_b207_3e54d0ebc378`
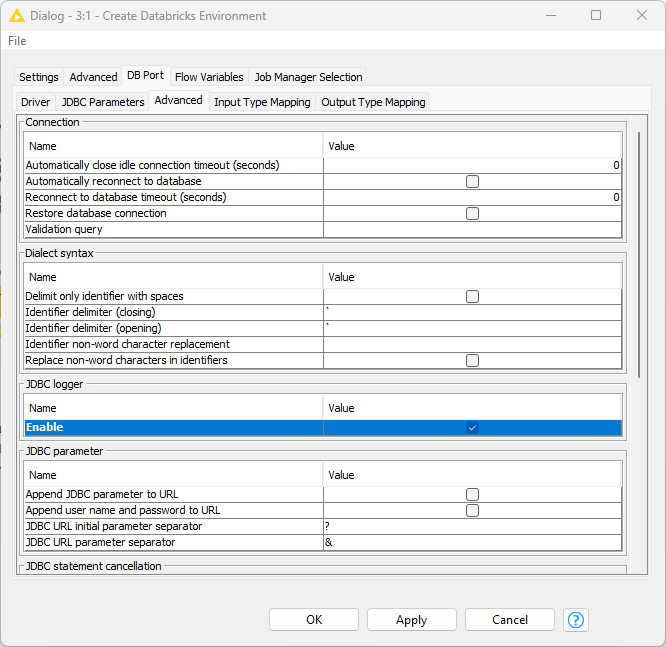
To view the statements in the KNIME log you can enable the JDBC logger via the Advanced tab of the DB Port tab in the Create Databricks Environment node:
Thank you Tobias! That is very helpful information and instructions about the logging! I will try it and reach out to Databricks support as a next step.