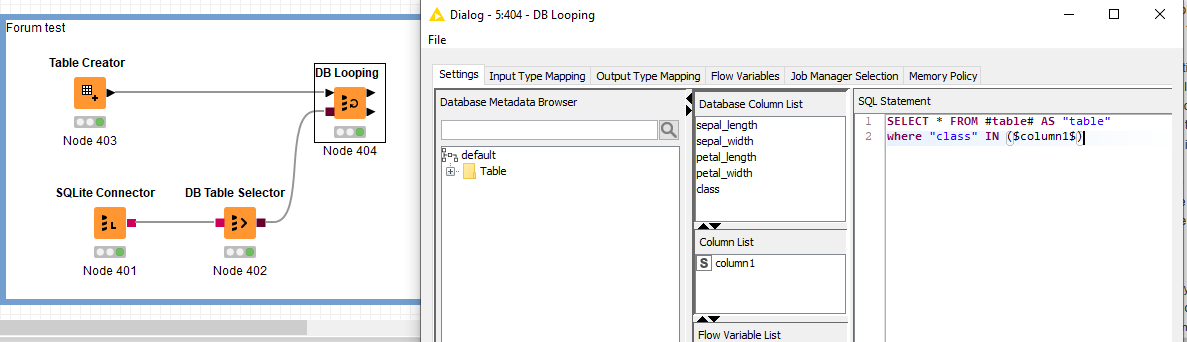
I have searched but am confused by “db looping” node. I have studied the examples but not sure I understand it compared to what I need. I will try to simplify what I am hoping to accomplish.
Let’s assume I have a table of transactions which has a few million rows. Included in transaction columns is a customer_id.
My workflow is that I pull from a spreadsheet to get a set of customers (say 10 that includes a customer_id) then I want to pull from transactions where Transaction.customer_id = spreadsheet.customer_id.
Option 1: I could pull customers from spreadsheet and join to transactions but pulling the transactions into knime takes time and hoping I can more or less use db looping to pull just the transactions I need.
Option 2: Another approach I guess is to import the customer_id into the database and then join in database.
I suspect option 2 likely is faster, but I’d like to try option 1 first. The problem is the db looping node does not seem very clear to me.
In the db looping configuration I see three areas:
Database Column List
Column list
SQL query
SELECT * FROM #table# AS “table”
Here’s where it’s a bit fuzzy.
is #table# is my example the transactions table (how to I ensure it is?) Then do I add to query where transaction.customer_id in ($customer_id$) <from spreadsheet?>
I have connected spreadsheet customer_id table to input port 0 and the query of transactions to port 1. If I run it run it, in the end I have to cancel it as it never finishes.
Question 1: Have i missed how to write query in sql query portion?
Question 2: Maybe this is not right approach and I need to use option 2 or another method.
Thoughts?
Thanks,
Jeff