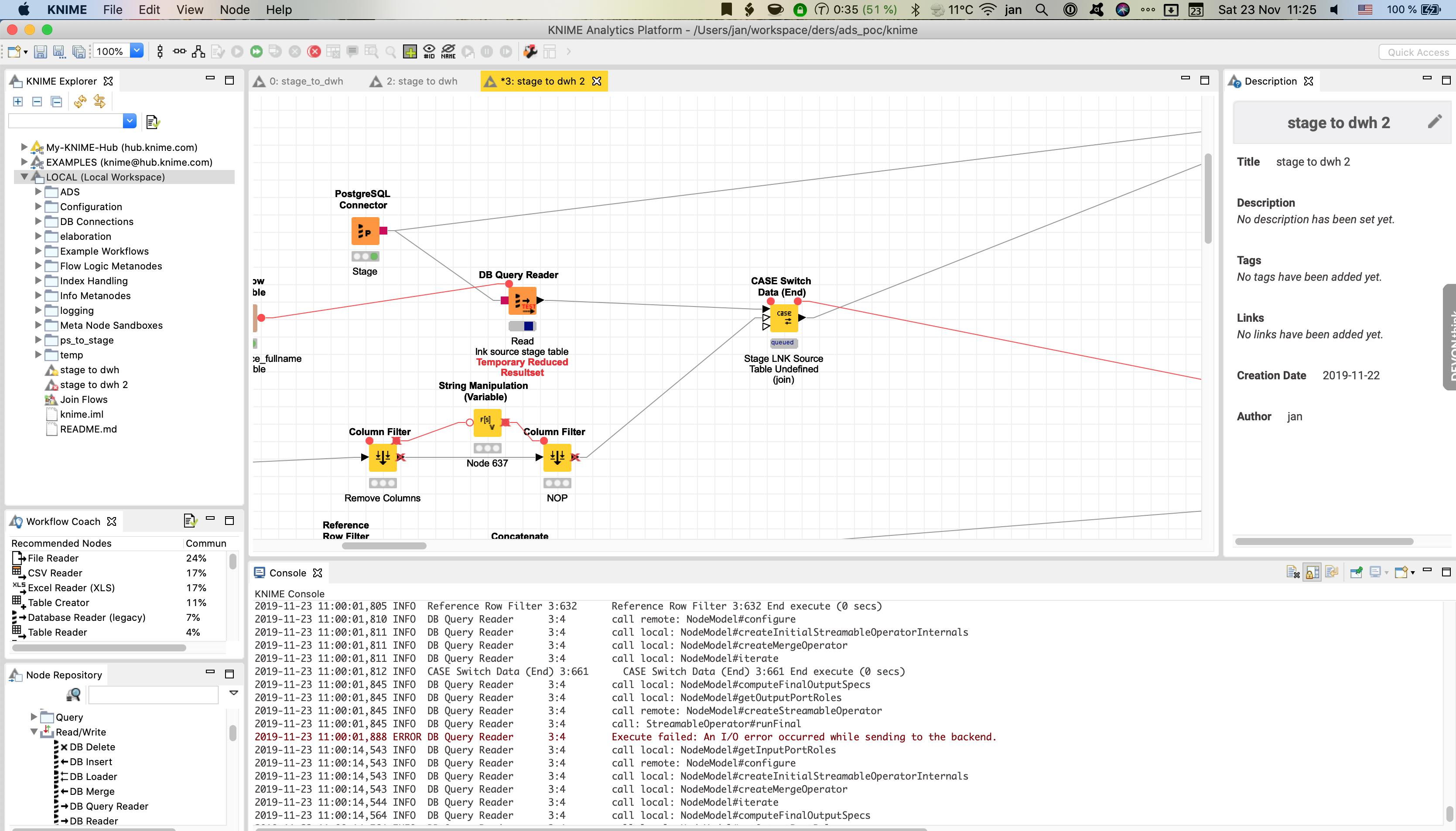
After upgrading to KNIME 4 I started replacing legacy database-related nodes (e.g. Database Connector, Database Reader, Database Writer and the other) with those recommended alternatives such the DB Connector, DB Reader, DB Query Reader.
I keep experiencing an issue that is very severe for me because it prevents me from noticing my workflow failed.
Let’s see an example. I nave a DB Connector in my workflow. Let’s note it was invoked a considerable time ago. Now it’s time for the DB Query Reader. It has changed its state to Invoking, it has marked as invoking (the indicator is moving). But what I can read from the log, it actually failed complaining about I/O Error. 25 minutes ago! But the node keeps indicating visually everything’s Okay, the workflow keeps pretending it’s working. As we can see, we could stop it’s execution right now.
I strongly believe this is the case, I could see the legacy node would state there is not an active connection in the pool (I’m not sure about the exact term for it) and re-connect the database. It is obvious the new generation of DB node have not this ability anymore.
I consider this a severe bug which makes KNIME workflows far from reliable for longer lasting jobs.
Thank you.
Jan
Just a note: I’m aware of two possible workarounds.
First: Ensure DB Connector invokes always before DB Query Reader making it dependent on the DB Query Reader’s immediately preceding node. I think this is not reliable unless our workflow is strictly linear. In other cases, we have no control over how much time it could take between the end of the invocation of a preceding and start of the invocation of an immediately following node because KNIME would invoke plenty of nodes in other branches in the meantime.
Second: Get rid of DB Connector and configure connection details right in db-related nodes. All of them, one by one. Ugh. This would be a very ugly and hardly maintainable solution. And as far as I know, these nodes can’t do this.
I current release, if you want a parallel data processing you will need separate DB connectors. So, no much saving. For me it is worst than old DB nodes with individual configurations…
To add to this topic, I have observed this behavior too. For sure in 4.0.2. In my case it’s also about canceling long running queries. Cancelling a query can lead to the state Jan observed that everything seems fine but the Reader just runs forever. Once you cancel again and reset the connector node, it works fine. actually this seems to happen every time one cancels. The issue is obvious, if you have 1 connector only and multiple long running queries, if you cancel one then you have to rerun everything to make it work.
currently it’s simply the best/most stable to use 1 connector per query.
Hello,
compared to the legacy framework the new database framework no longer tests if the database connection is valid or not prior every use in order to speedup execution. Instead we are relying on the database driver to properly handle these situations. However it seems that some drivers have problems with this and don’t throw a proper Exception.
So far we haven’t implemented automatic re-connection since it might cause other unexpected problems with session dependent objects such as temporary tables which are suddenly no longer available because KNIME uses a new connection. However we also see the need for this function especially for long running jobs. So we plan to add a re-connection feature to the framework which will allow you to specify how often KNIME will try to connect to the database if the connection is lost. Any number greater 0 will trigger that KNIME validates the database connection every time prior it is used in any of the nodes. What do you think about such a functionality?
Cancellation is also highly dependent on the JDBC driver. We use the standard API to cancel pending operations via the driver but not all drivers implement this functionality and not all operations can be cancelled by the database. If this is the case KNIME will move the cancellation the execution of a statement to the background to prevent KNIME from freezing. However if you then use the connection that KNIME tries to cancel in another node this node will wait until the cancellation is finally done.
If you re-execute the connector node KNIME will also move the closing of the connection into the background before returning a fresh connection. So all these functions highly depend on the database and the driver that are provided by the database vendors.
Bye
Tobias
Seems ok for me.
Just let’s admit here that we’re introducing a side-effect here because not only increase you a number of the reconnection attempts workflow is supposed to conduct before it gives up but you make it less likely that KNIME provides you with a failed DB connection. In other words, if you set the number of attempts back to zero, you disable the feature of checking a connection before it is used. From the UX and transparency point of view, I’d vote for two configuration inputs. The first one, whether to check the connection at all and the second one, how many times to try to reconnect.
This will work unless you configure your KNIME to invoke multiple nodes concurrently. Because after you do it you no more can be sure your nodes (a connector and a query) are invoked immediately after each other. After your connector gets executed you never know which other nodes KNIME decides to invoke before it is the subsequent query node’s turn.
Hi, Tobias,
Unfortunately in a non-sequential workflow, even if you control execution order of your nodes using variable ports, you can’t ensure a subsequent node invokes at the moment its preceding node gets executed. May be, if you messed up your workflow completely with variable ports.
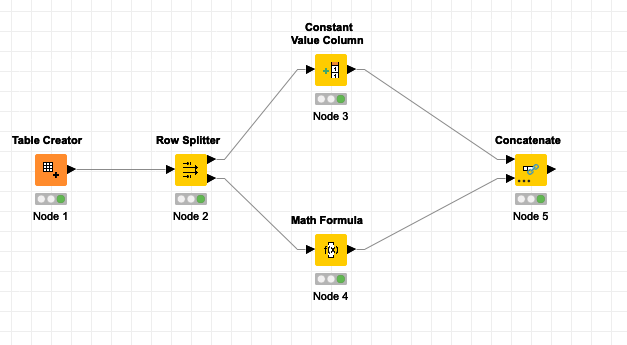
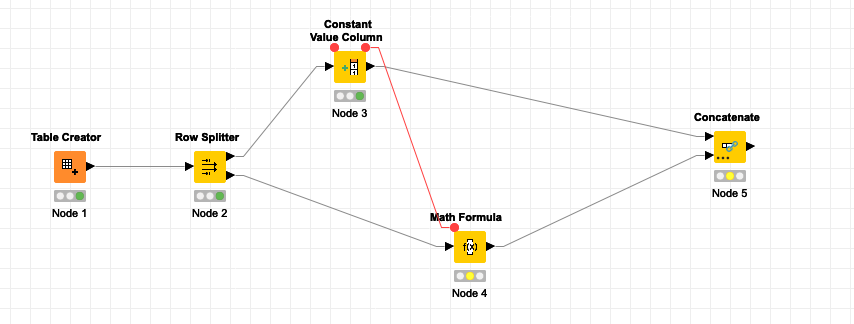
For instance this:
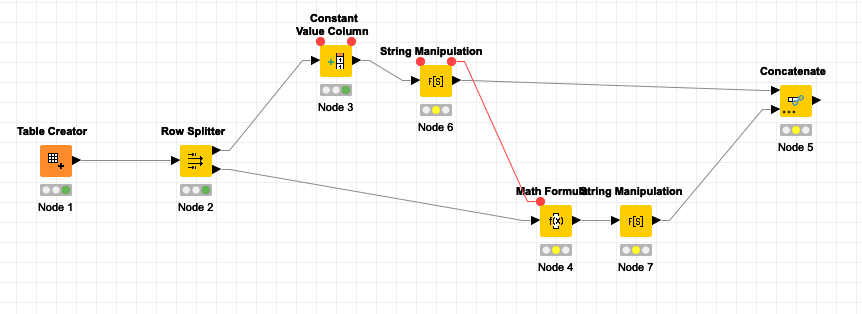
Could become this:
But there can be more branches, more alternative branches that can execute optionally which will make you introduce End If or Case Switch Variable End nodes which will impact performance of your workflow. The more complex your workflow is the more messy you get it.
So my conclusion is you can’t always ensure two subsequent nodes in your workflow execute immediately one ofter each other. Which made it possible you lost your connection DB Connector had created before subsequent DB Node invocation started. Now, you can configure your DB Connector to reconnect the DB after connection is lost and this is what makes using new DB nodes a bit less frustrating.
Hi,
the new database framework has now an option to automatic reconnect to the database if the conenction has become invalid. For details see this post.
Bye
Tobias