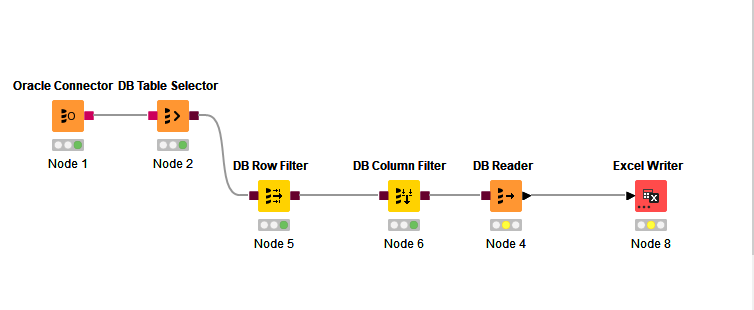
I am using DB Reader Node, After the Row & Column filter nodes to fetch data from a Oracle database. I am facing a performance issue while using a DB Reader just for fetching 10000 rows.
I have updated the fetch size in Oracle Connector node from 10000 to 5000, I have updated the KNIME.ini file for memory usage to 8gb, which has increased a bit of performance, but not much.
Checked network and antivirus issue, both is fine.
At present to fetch the 10000 rows with 5 columns it is taking 30 mins.
Can anyone please support on this.
Hi @VishalM0228 , the amount of rows being retrieved has very little impact on what can be a performance issue.
In fact, depending on how things are done, a query that’s retrieving 1 row could take minutes to retrieve while another query retrieving 100k records could take just a few seconds.
It all depends on how you are retrieving the records, how many rows are you filtering from - any joins? any where conditions? any sorting?
It would be helpful to see your WF. As I understand, you used DB Row and Column filters. Possibly the better solution to filter directly using SQL in DB Query Reader
I had provided a where condition on a date field in the DB Table selector node by a direct sql query.
Though I have doubt for the DB Table reader configuration, is it better to select the ‘Cache Tables Memory’ or ‘Write Tables to Disc’. At present I have selected write tables to disc.
Hi @VishalM0228 , sounds like you are using a custom query for the DB Table Selector.
If you are already writing a query with where condition, why not write the whole SQL using the DB Query Reader instead?
Essentially, the DB Row Filter is just applying another WHERE condition.
Is any of the fields you are filtering on indexed? The date field for example, is it indexed? Or any of the fields you are filtering on for the DB Row Filter, any of them indexed?
And how big is the table you are reading from?
All these questions are what impact performance, not the fact that you are pulling 10000 rows
Ya @bruno29a I will update the flow, removing the row filter.
and adding the conditions in the SQL.
The table is not indexed, but yes it is pulling data from different tables in Oracle.
There is separate team working on Oracle DB, so a request for finetuning the table will take considerable time.
So I am trying to bring up a flow that shall pull the required fields.
@VishalM0228 if it is a view the main work will be done on the ORACLE server and KNIME itself can do little to speed things up since the data will have to be processed at hoc on the server. This is why it does not matter how many lines you choose since the VIEW will have to be processed anyway (especially if there are complicated joins with no indexes are involved …).
What you could take into consideration
set filters as early as possible to a Oracle code optimization might use them well in advance (‘report’ them to the stream, will depend on the database). If you only need a sub set of the data tell that right away
if it is a simple VIEW it might be an option to separately load data from the two underlying tables (with filters!) and then join them in KNIME. This of course very much depends on just how large the files are you want to load
test with single table and a larger amout of data to see if maybe your LAN connection is a bottle neck
Then you could think about trying to load the two tables in chunks (if there are suitable IDs or somthing) and store them locally and then join (again: how large is the data overall).
If you can or do not want to use CSV for this you could store the single loop results as individual parquet files in a folder and then read them back as one file - thus saving the column types.