@VishalM0228 if it is a view the main work will be done on the ORACLE server and KNIME itself can do little to speed things up since the data will have to be processed at hoc on the server. This is why it does not matter how many lines you choose since the VIEW will have to be processed anyway (especially if there are complicated joins with no indexes are involved …).
What you could take into consideration
- set filters as early as possible to a Oracle code optimization might use them well in advance (‘report’ them to the stream, will depend on the database). If you only need a sub set of the data tell that right away
- if it is a simple VIEW it might be an option to separately load data from the two underlying tables (with filters!) and then join them in KNIME. This of course very much depends on just how large the files are you want to load
- test with single table and a larger amout of data to see if maybe your LAN connection is a bottle neck
Then you could think about trying to load the two tables in chunks (if there are suitable IDs or somthing) and store them locally and then join (again: how large is the data overall).
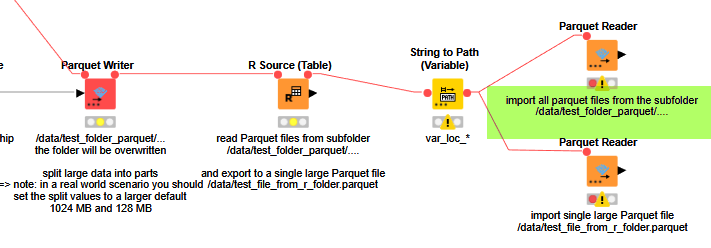
If you can or do not want to use CSV for this you could store the single loop results as individual parquet files in a folder and then read them back as one file - thus saving the column types.