Hi.
I have a strange problem - my DB Table selector does not display all Hive tables. It can display all databases. I have tried many jdbc drivers and the result is the same. This problem is also with the legacy nodes.
I can see the tables when i use beeline so there is no problem with user rights.
Is there a way to manually configure, test or fix the DB table Selector node? Maybe pass some jdbc parameters or something like that? I get the feeling that it somehow reaches a table display limit or can’t retieve all tables.
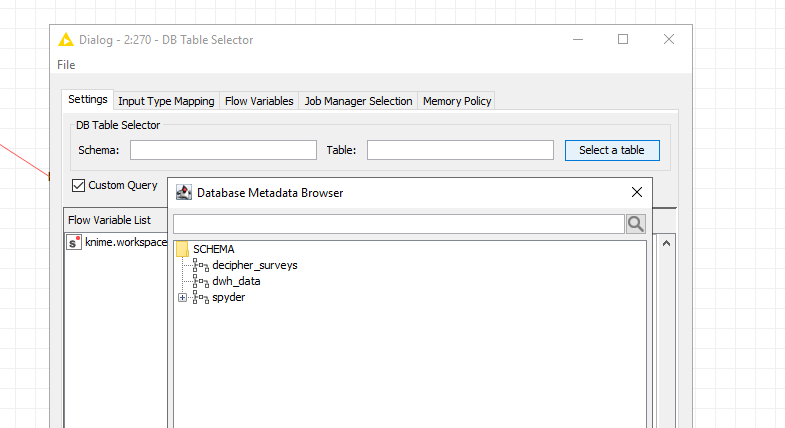
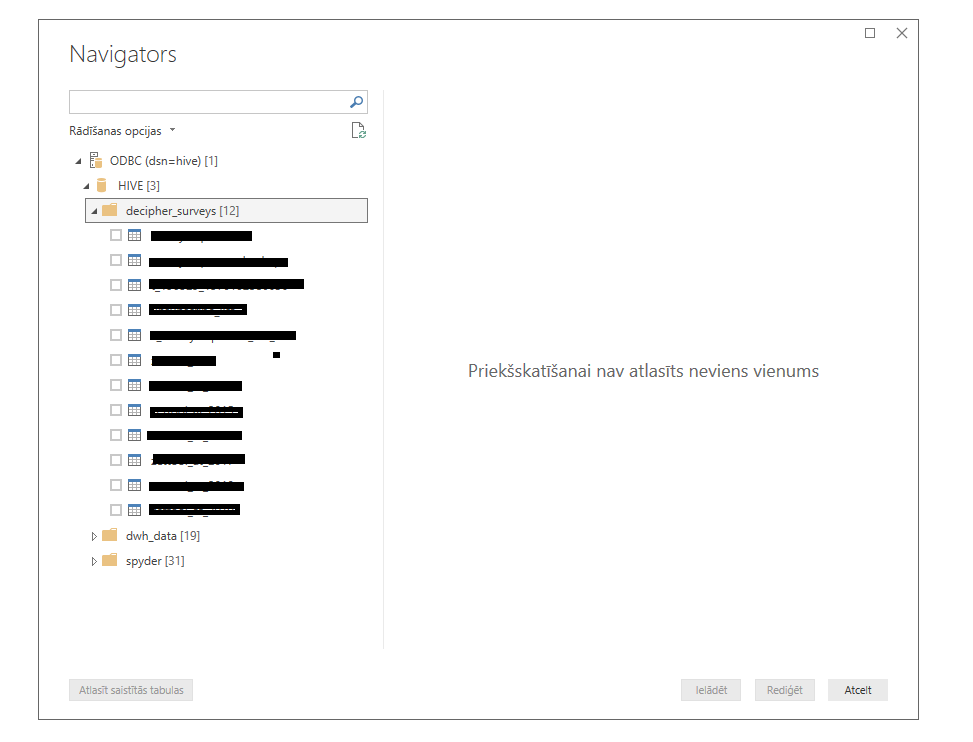
I hope someone can help me. I also tried an odbc driver and it displays all tables. I also added some pictures for comparison. The table names are masked.
Im using:
Knime analytics Platform 4.0.1
HDP-3.1.0.49 and the driver is official hortonworks hive driver
Can you access the ‘missing’ table? So it might be there.
You might try to tell your big data system to calculate statistics for your table thru Impala (yes I know it sounds strange).
With an Impala connector you could use an SQL executor and try:
INVALIDATE METADATA “default”.“your_hive_table”;
COMPUTE INCREMENTAL STATS “default”.“your_hive_table”;
Hive can then access the statistics created by Impala. Hive itself cannot create statistics but it can read Impala statistics.
Isn’t impala a cloudera tool? I have hortonworks data platform. Also i don’t have admin rights. I assume you need those to recalculate metadata. And i see those tables when i use an odbc driver foe example in microsoft power bi. It means that the odbc driver can read the metadata right?
As i said i will think of it and ask my admin.
Hi there @jcielens,
welcome to KNIME Community Forum!
Using Custom Query option and selecting existing table from dwh_data schema is successful or not?
Br,
Ivan
Sadly in the new nodes i can’t select the table with custom query option if i can’t see its metadata. I get an error that says “table or view is not found”.
It is different with the legacy nodes - there even if i don’t see the tables i can still query them.
I know you will say i should use legacy if it works but i want to understand why this problem is happening.
Have you tried just to access the table via SQL executor? Or by:
Also you might use a custom query in the database selector. Maybe just type in the query without questioning the metadata first.
I have no experience with hortonworks (which has been acquired by Cloudra) but I do not think you need admin rights to calculate statistics.
Edit: there seems to be a command in HW to generate statistics
ANALYZE TABLE mytable COMPUTE STATISTICS;
Hello jcielens,
the new node is not doing any checks in KNIME based on the meta data. If the node complains about a table it can not found then it is the database itself that complains and not KNIME. What might cause this is that the new nodes always quote identifier whereas the old nodes only quoted if the identifier contained a space. So maybe the case isn’t correct.
Bye
Tobias
Thanks for the answers but you guys are trying to solve the wrong question. I know how to query the table and which nodes to use. The question was about metadata: why does knime nodes not return the table list?
And the other question: can i somehow remake the nodes or reconfigure so that they do it?
I talked about this with our admin and he says the problem must be within the app because the odbc driver in microsoft power bi can retrieve them so why can’t the jdbc driver in knime?
Maybe I still do not understand the point. Maybe you can add a few screenshots where you would expect the metadata to be and make sure the table is actually there by executing a query retrieving data from it.
Then I would suggest to try to recalculate the metadata because from my experience this is what sometimes hinders external tools or drivers to “see” the tables in the first place,
Another possibility is to use a generic SQL query to see the tables.
show tables in default like ‘my_table*’;
Also youmkight want to confirm if the metadata is there if you access your big data system without KNIME, like from Hue.
According to screenshots: please see my first post. I hid the table names but the main idea should be clear. The number in brackets shows how many tables are retrieved. The missing + in knime screenshot show that if did not found any.
And also in the first post i wrote: i can see the tables when i use beeline. Beeline is hive cmd and yes i can return the list if i write the show tables command there.
Ok, lets return to this on monday, i will see if i can recalculate them and see if something changes.
With screenshot I was thinking about how this looks in KNIME to get an idea where to look next. Wish you success on Monday, recalculation would be my next bet.
Indeed you posted that before. Some DB nodes have a little button to refresh the data. I am sure you have pressed that. Just to make sure …
Hello jcielens,
please execute the show tables statement in the DB Query Reader node in KNIME. Do you see any tables from the decipher_surveys or dwh_data schem at all?
What happens if you execute a
SELECT * from <YOUR TABLE NAME>
query in the DB Query Reader node? Do you see any data?
Are you connecting to a Kerberos secured cluster or do you use user name and password for authentication or is this an unsecured cluster?
Did you register the JDBC driver provided by Hortonworks for you platform as described here?
Bye
Tobias
@tobias.koetter thanks it really does return the table list and i can select data.
Indeed we are using a kerberized cluster but we connecting with a username and password.
So what is the difference between retrieving metadata and the ‘show tables’ command? Can you please tell me where does knime look to fetch metadata because i’m arguing with our admin that knime looks somewhere and he just says that he does not see any queries in logs. I added a picture where you can see that no metadata are returned but the surveys database has 11 table in it and the Database query reader can return them. Is this a knime bug?
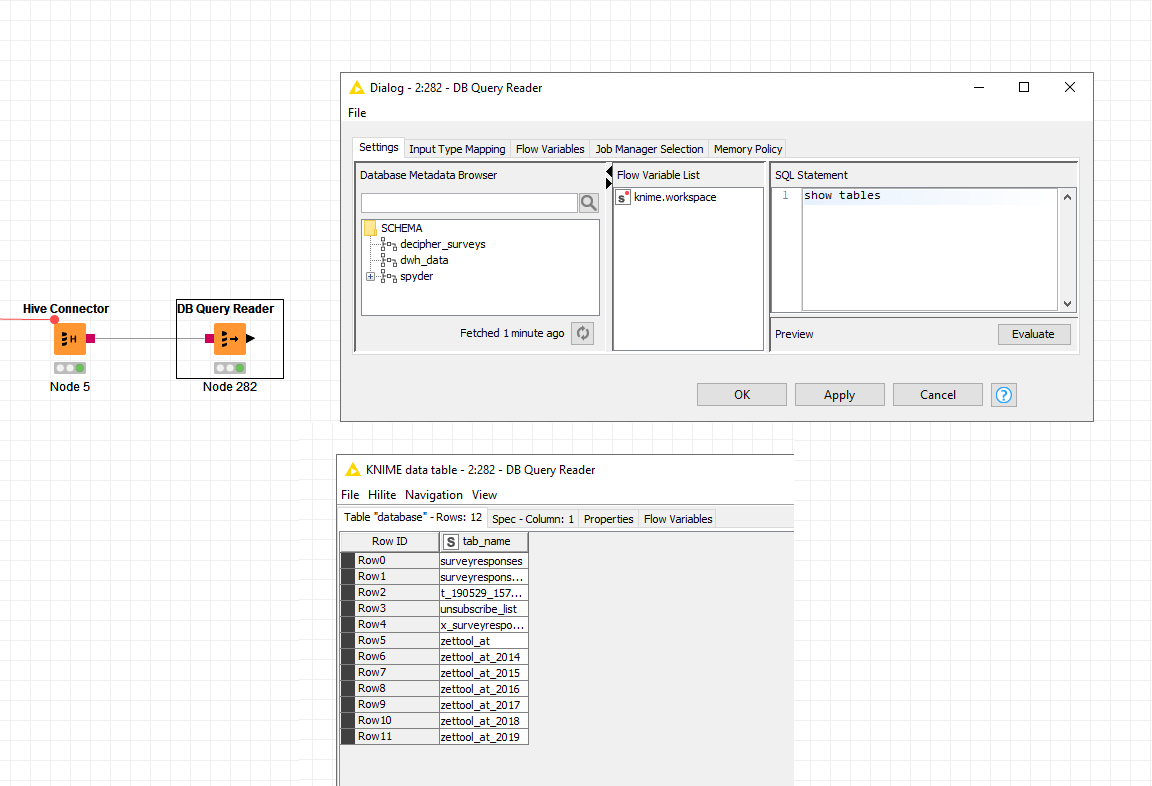
Hello,
KNIME uses the getSchemas() method of the DatabaseMetaData class of the JDBC driver to get all schema names. In addition it also uses the getCatalogs() method to get a list of all catalogs. For each schema and catalog it then calls the getTables() method to get all the tables.
I created a schema with the same name as yours in our secured HDP 3.1 cluster. Using the build in Apache Hive driver I get the following list of schemata and tables including the created decipher_surveys schema and surveyresponses table

Maybe this is a problem with missing permissions in your cluster setup or a bug in the JDBC driver. Please also contact Hortonworks support regarding this problems and let us know if they require further information.
Bye
Tobias
@tobias.koetter great thanks, i will contact them. And i marked your previous answer as sollution because it can be used to see available tables.
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.