I have a doubt on what is the best way to control the flow of my DB statements. I have different sql statements to run, and some of them need to run before others. I also want to take advantage of parallel processing.
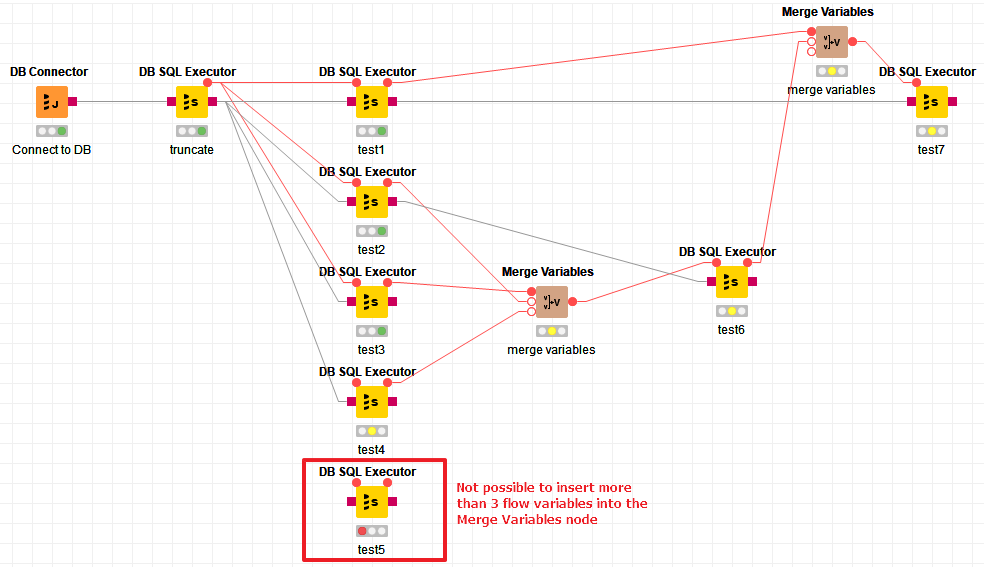
In this example, I have 7 nodes that perform different things.
Nodes called “test1” through" test5" can run simultaneously.
Nodes “test2”, “test3”, “test4” and “test5” have to run before “test6”.
Nodes “test1” and “node6” have to be run before running the final node “test7”.
I have read that the way to control the execution of the nodes I have to use flow variables. I have some questions:
A- How do I control the flow if more than 4 nodes or more are needed before running “test6”? The node “Merge Variables” only lets you merge up to 3. Is there a way to do it without cascading many “Merge Variables”?
B- Given that I use many DB SQL Executor nodes, is there a way of connecting all of them with the same DB connection without cluttering the canvas?
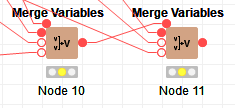
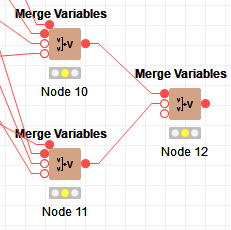
You can add an additional flow variable input to the Merge Variables using the hidden port at the top left (as you have on the DB SQL Executor nodes). If that isnt enough, you can daisy-chain multiple Merge Variables nodes - take the output from one (or more) into the inputs to another:
or
Etc.
It is worth noting that if you have duplicate variable names with different values at the various inputs, then the value at the top-most port will take precedence.
I thought you would want to know that we are planning on adding dynamic ports for the Merge Variables node in the next release. We already have these in place, for example, on the Concatenate node - you can see what that looks like here: