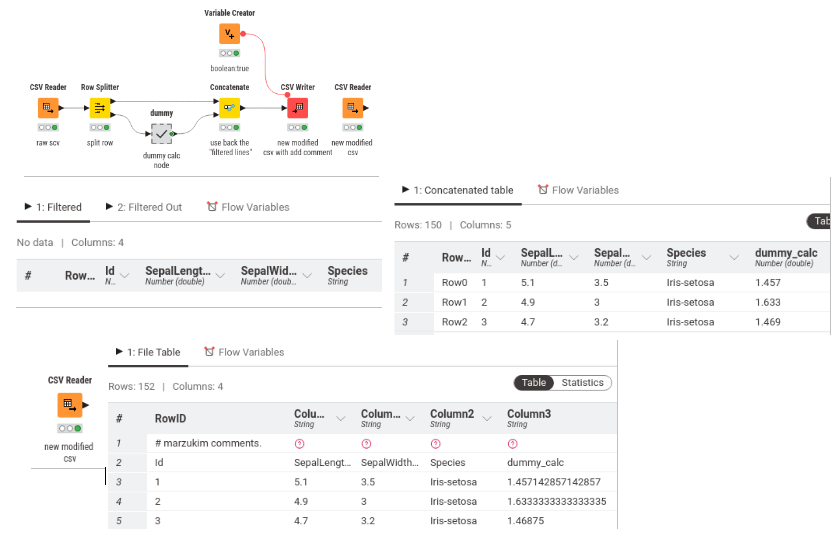
I need to change some CSV files which have a few comment lines at the top.
In the CSV Reader I am using the “Skip first lines” option to ignore them.
The CSV Writer has “Comment Header” Option where I could use “the following text” to output that header again.
How can I extract this header from the CSV in order to later use it in the writer?
hi @masgo
i’m not sure if my approach is the right way. perhaps other members have different methods that would be more efficient. I have attached my simple workflow, which extracts the header from the raw csv file and uses it in the writer of the new csv file.
Your idea will not work for me, because the first line has a completley different format, but it contains separation characters.
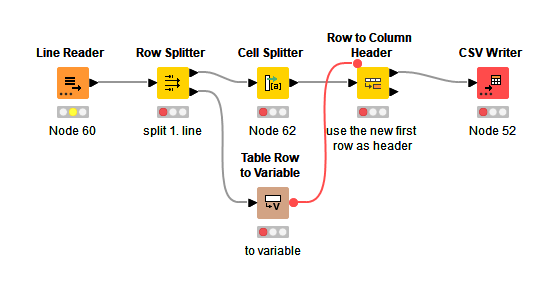
I found this solution.
It uses the Line Reader and splits the first line away. converts it to a variable which is then used in the CSV Writer.
The remaining lines are split up with the Cell Splitter. The Row to Column Header then uses the first row (2nd row in the original file) as Header.
The main drawback of this solution is the lack of options in Cell Splitter compared to the CSV Reader node.
Also, Cell Splitter does a type conversion (which can not be disabled). This causes strings like 01234 to be converted to the integer Nr 1234, which is a problem for things like Postal Codes staring with 0.
For my specific problem this solution is good enoug, but only because my data does not contain such corner-cases.