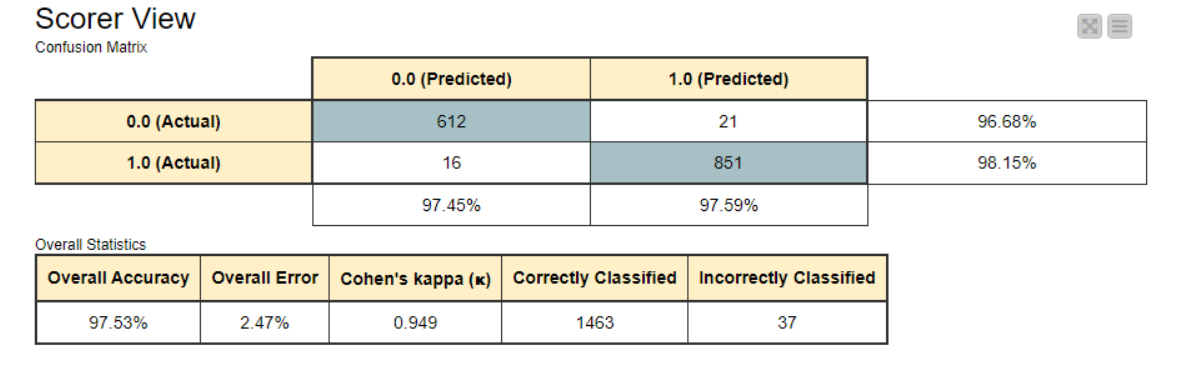
Hello. I seem to be having an issue with the decision tree learner node in KNIME. I have posted my workflow below so that it is easier to understand the issue. The confusion matrix seems to show that the target column is predicted to be just one type of classified data (as 1) but the actual data is classified into both 1 and 0. Thus, I think the model is overfitting. I changed the configuration options many times in the decision tree learner node but it did not fix the issue. Hope someone could help me out here. Thanks in advance!
Please note that I am only using this decision tree learner node because I want to write it into a PMML model. And I could not find any machine learning model nodes such as random trees, etc. that allowed me to easily convert the trained model into a PMML model.
@akhtarameen concerning overfitting you might want to read about the evaluation of predictive models. In this case the question might be where to cut-off the 0/1 decision. The default of 0.5 might not be the right one.
Beside the already given (great) advice
Decision Tree node should allow you to apply pruning which can help you in regards of overfitting.
Also you might give ensemble models (random forest,…) a try which might be of help here. @aworker is right.
You always want to give some sample if possible
br
@mlauber71 I tried turning off the configuration setting of the average split point setting for the decision tree learner. However, that did not work either and it was still overfitting. Also, the other models that are supported by PMML such as SVM, clustering, etc. are not suitable for my evaluation. I currently have a dataset of 5000 ECG values, from which some are classified to be normal (1) and others as abnormal values (0). From this dataset, I need to be able to predict the abnormal values correctly. Either I train the model using a 70-30 train-test split or I train it with only normal values and try to make the model test with the whole dataset and predict the abnormal values. So for that a random forest, isolation forest or decision trees seem to be quite suitable to my knowledge. If there are other models that would be suitable please do let me know as I may have missed out on them.
Also @mlauber71 you said the MOJO format from H2O.ai would also be an option, but the output from the trainer node in MOJO format does not support PMML. So I am a little confused on how I can move forward from here. Hope you could clarify this thank you!
I have posted my dataset below, sorry for the inconvenience!
@Daniel_Weikert I did try pruning but that too does not seem to help
And if I am not wrong, only some ensemble models can be used to create a PMML model right. And those models I think would not be suitable for my dataset and the goal I want to achieve.
Thank you for your replies everyone, I appreciate it.
Regards!
Thanks for testing it out. And oh wow that looks good! My confusion matrix only gives values for the first column. The second column is just 0. So I am assuming it is because all the data points from the predictor node are overfitting to be just one class. Can I see your workflow and decision tree learner node configuration settings if you don’t mind? That would really help me solve my issue.
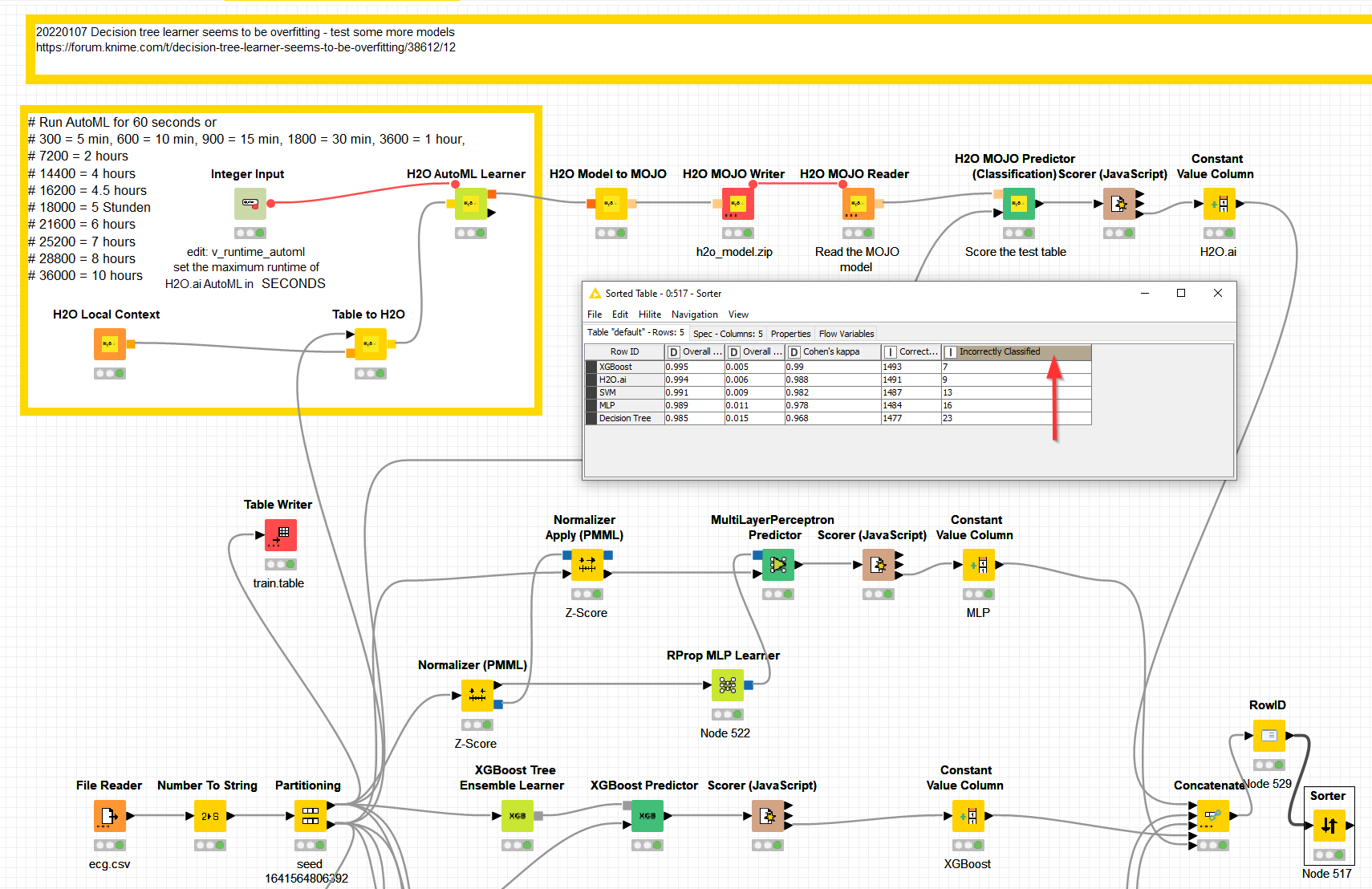
@akhtarameen the Decision tree of @aworker does a wonderful job. I wanted to see what else is possible so I took it up a notch. H2O.ai and XGBoost are able to do an even slighly better job with more correct classification (on the test set).
Admitteldly H2O.ai would add a further level of complication since it would use an ensemble of models to predict the outcome. If you data would differ over time very complicated models might also be less robust than a tree model. But from my experience a lot of systems (and namely KNIME) are good at handling MOJO files - so this might be an option if explainability is not the most important thing.
Using this approach with preparing the values first with vtreat brought down the number of miss-classified lines in the test file down to 5 although that might be an accident - or it might indicate that if you invest in data preparation even more precision might be doable.
Looking at variable importance Column104, Column117, Column105 are very important but not in a way that they would be considered a leak. But you might have to be careful about Column104 which carries something lik 40% of all explaning power - so to speak.
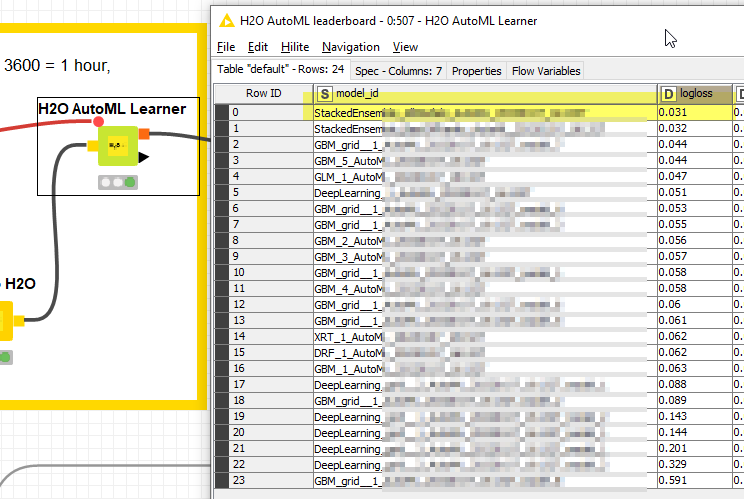
Also the AutoML leaderboard is full of GBM models so this might be an indicator that (Boosted) tree models might be a good fit; indicated by XGBoost taking the lead in the first place
Oh nice. I did run the AutoML node as well but got some different results. Maybe I will try it again and see. The important thing for me was to convert the trained model into PMML in order to test my model in python. That is why I was limited to using certain learner nodes in KNIME.
Furthermore, does anyone have experience in importing a PMML model into python and trying to predict results from there? I tried doing so but my confusion matrix in python again seems to be giving me similar results to this:
Does anyone know how I can fix this? I feel like it is an issue with the way I am importing my PMML model which is as follows:
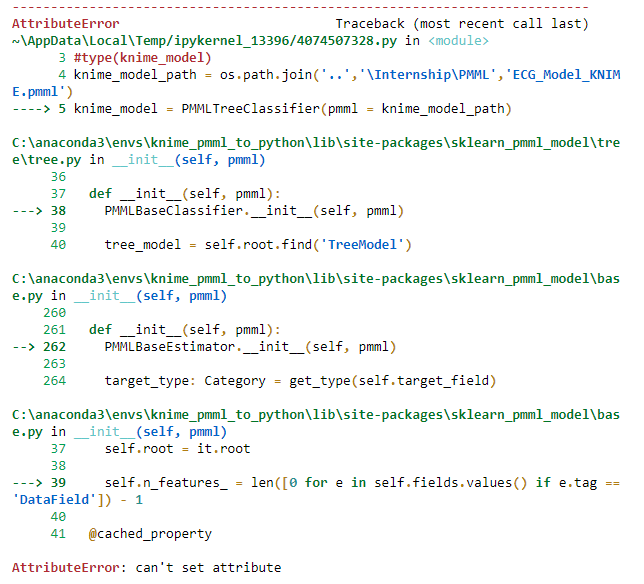
I tried another method of importing the PMML model which is as follows:
But importing the model using the second method gives me this error:
Thanks for you response! I want to compare the accuracy of the trained KNIME model after exporting it through KNIME as a PMML model by finding predictions and evaluating the model through python, with the results that I obtain when I directly train the model through python and test the model through python as well.
@akhtarameen you can import H2O.ai MOJO models into KNIME, R, Python and Spark (and back). That is why I like to use this format - for example I can develop a model on an R machine and then deploy it on a big data cluster.
This collection actually contains Jupiter notebook that basically does the same thing. So you might want to try that. There you might also see how to use relative paths in a notebook.