@akhtarameen the Decision tree of @aworker does a wonderful job. I wanted to see what else is possible so I took it up a notch. H2O.ai and XGBoost are able to do an even slighly better job with more correct classification (on the test set).
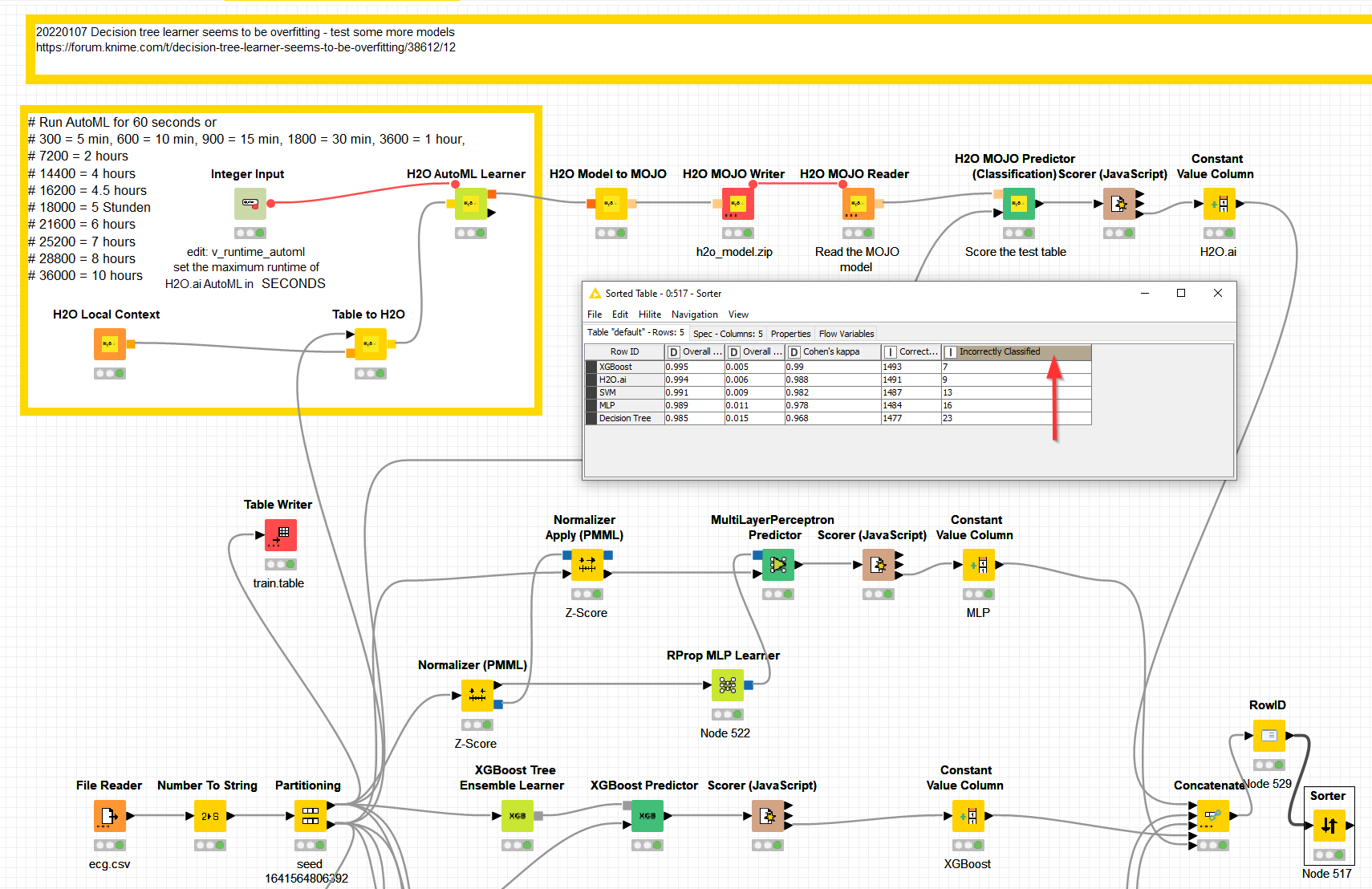
Admitteldly H2O.ai would add a further level of complication since it would use an ensemble of models to predict the outcome. If you data would differ over time very complicated models might also be less robust than a tree model. But from my experience a lot of systems (and namely KNIME) are good at handling MOJO files - so this might be an option if explainability is not the most important thing.
Using this approach with preparing the values first with vtreat brought down the number of miss-classified lines in the test file down to 5 although that might be an accident - or it might indicate that if you invest in data preparation even more precision might be doable.
Looking at variable importance Column104, Column117, Column105 are very important but not in a way that they would be considered a leak. But you might have to be careful about Column104 which carries something lik 40% of all explaning power - so to speak.
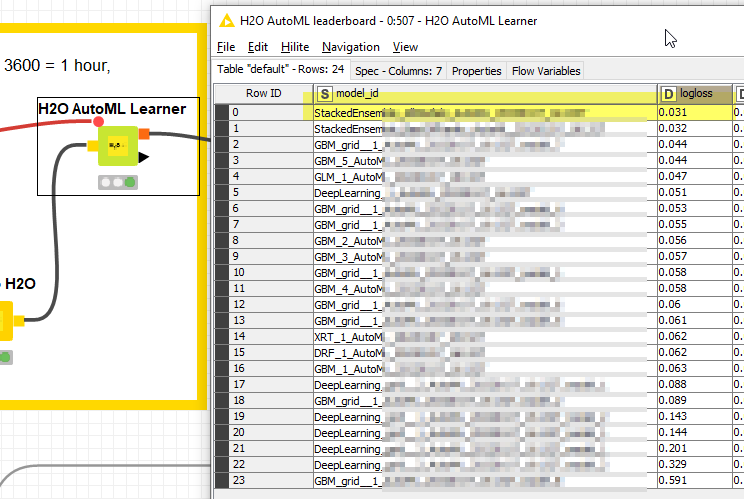
Also the AutoML leaderboard is full of GBM models so this might be an indicator that (Boosted) tree models might be a good fit; indicated by XGBoost taking the lead in the first place 