@akhtarameen you can import H2O.ai MOJO models into KNIME, R, Python and Spark (and back). That is why I like to use this format - for example I can develop a model on an R machine and then deploy it on a big data cluster.
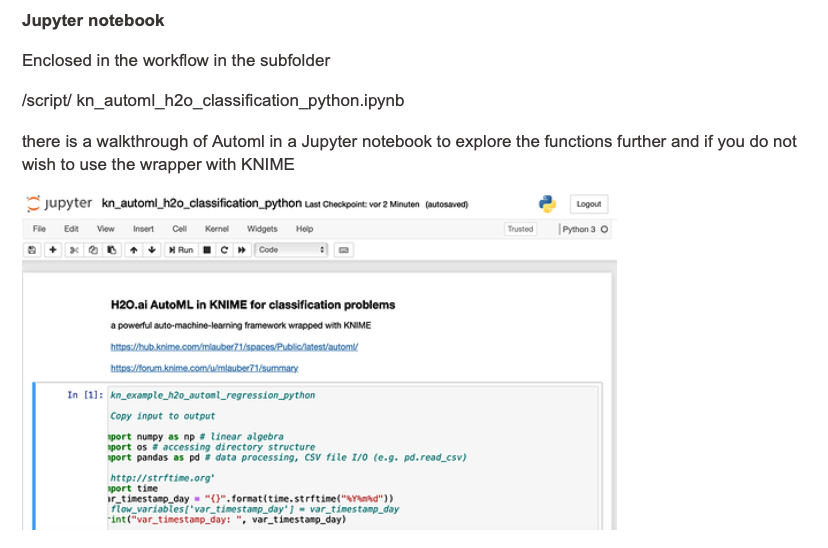
This collection actually contains Jupiter notebook that basically does the same thing. So you might want to try that. There you might also see how to use relative paths in a notebook.
This might be because of different splits in test and training, data preparation with vtreat and longer runtime with model building.