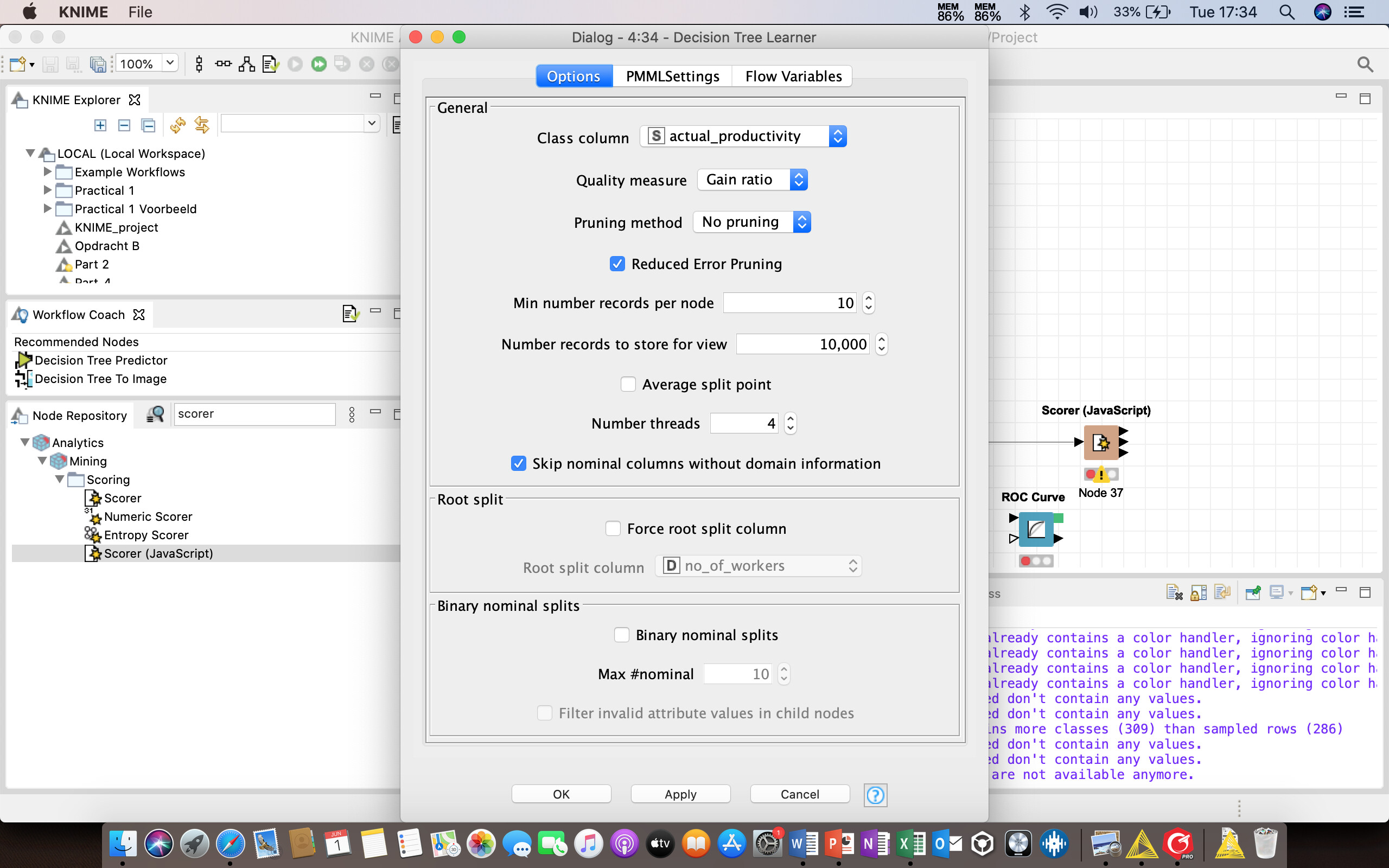
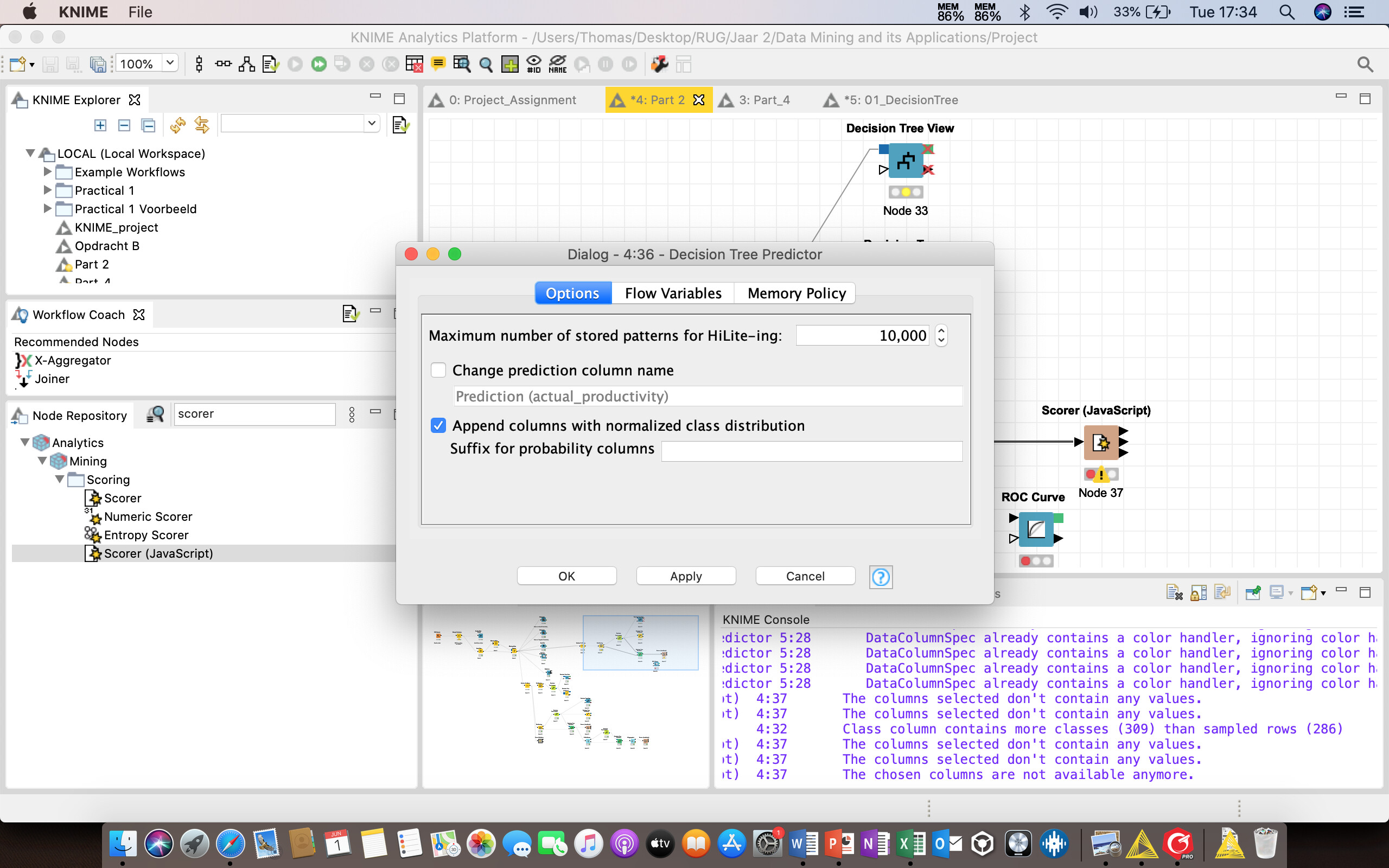
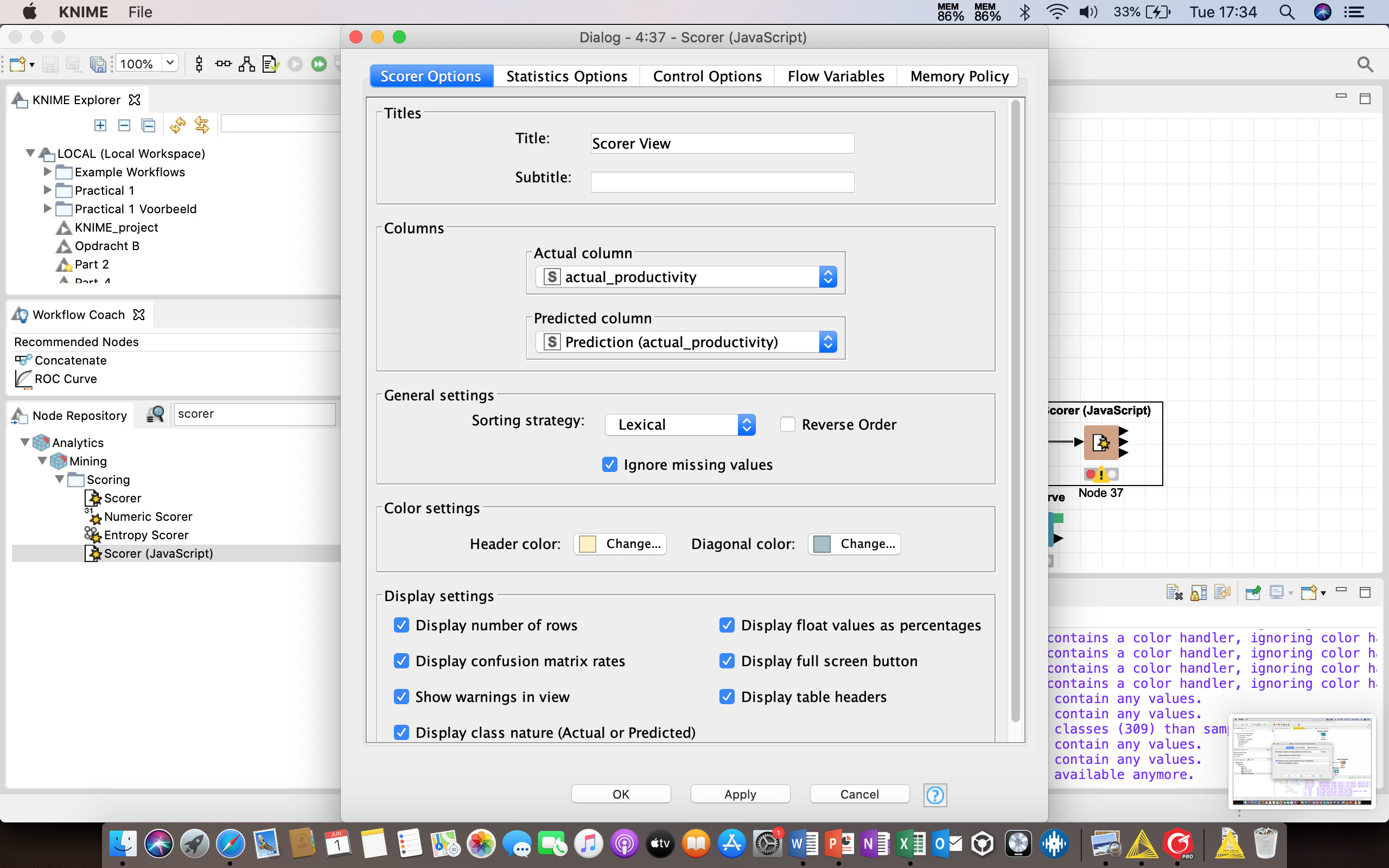
I try to make a Decision Tree analysis by using the Scorer Node. The node before this one, is the Decision Tree Learner. A comment I get from this node, is “Class Column contains more classes (309) than sampled rows (286)”. Next, I get a warning from the Scorer Node, that “The columns selected don’t contain any values.”
Can anyone please help me how I can solve this problem?
Most probably a configuration problem of the Decision Tree Training learner node. Would it be possible for you to share the workflow or at least a minimalist version of it with dummy data so that people can take a look at the problem ?
Unfortunately I cannot share the workflow with you guys. I have included screenshots of the Decision Tree Learner, Decision Tree Predictor, and Scorer (Javascript). I hope you have an idea how our problem can be solved!!
Nothing I could say it’s wrong in the configurations you have set. What strikes me is that you get such a message:
I cannot understand how the number of classes can be more than the number of rows. Could you please at least tell us
How many rows has your initial set before doing any splitting of data into training and test sets ?
How many classes (or different nominal values) has your initial set (before doing any splitting) ?
if before training you do splitting, could you do a “group by” on both your training and test sets, based on your class column and tell us the resulting number of rows in both ?
It may happen that not all the classes are represented in the splitting, which would justify such kind of error message.
This is all I can guess without more information so far. Something that would help too is to have an snapshot of your whole workflow if you cannot share the workflow itself.
The initial dataset has 4 classes (strings), namely Date, Day, Quarter, Department. However I have used the Number to String node to change some numerical data into a string as well. I have used this to change the data of Actual_Productivity into a string. The goal of the project is to make a correct prediction of the productivity of employees.
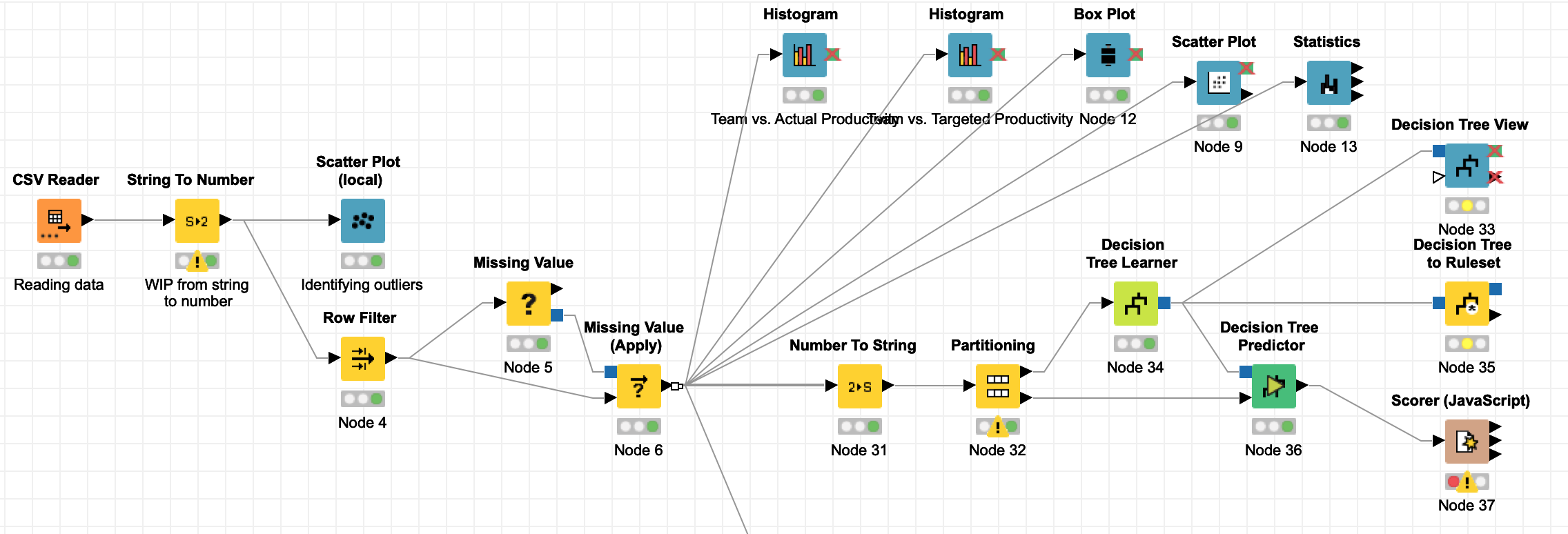
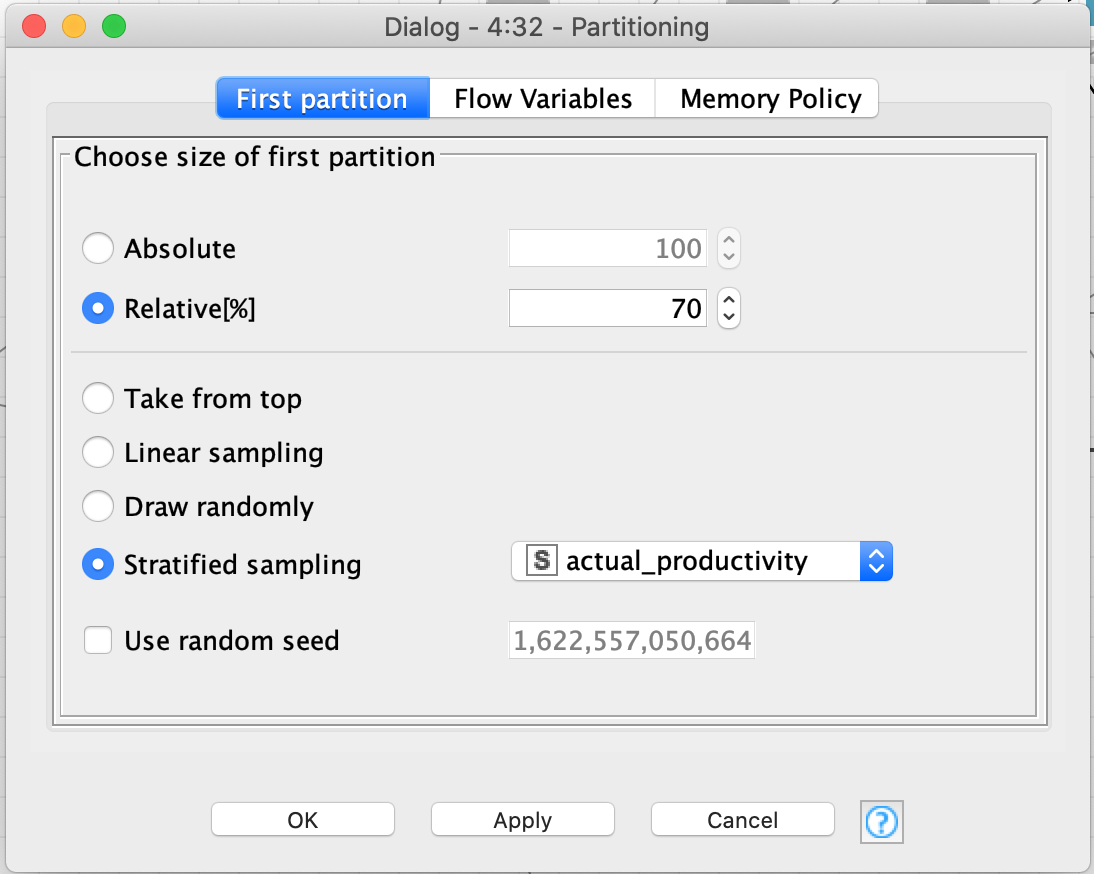
I have added a screenshot of the complete workflow. As you can see, I get an exclamation mark at the Partitioning node. This is the place where I get the error “Class Column contains more classes (309) than sampled rows (286).” So I also added a screenshot of the configuration of the Partitioning node.
I hope I understood the differences between attributes, classes and rows correctly. If not, please tell me
I see. From your last message, I believe there is missundertanding of what are “classes”. Aren’t these rather descriptors (columns) to predict you column class (“actual_Productivity”) ?
How many different possible values do you have in your “actual_Productivity” class column ?
Could you please apply the test I suggested in my previous answer :
How many different nominal values has your initial set (before doing any partitioning)? You can know this by doing a “group by” based on your Class column (“actual_Productivity”)
Before training, you do partitioning (splitting). Could you please do too a “group by” on both your training and test sets, based on your class column “actual_Productivity” and tell us the resulting number of rows in both ?
I’m sorry for my misunderstanding haha. In our dataset, we have different teams (from 1 to 12). Each row in the dataset is thus connected to a team. Next to the Actual_Productivity, we also have an attribute Targeted_Productivity. In total, we have 718 rows, which are 718 measuring moments.
In the “Actual_Productivity” class column, I have 718 possible values.
Answers to your questions:
2. When I want to use the “Group By”, I get an error saying “No Aggregation column defined”. I am not sure what I have to do in this case…
I get the same error when placing the Group By after the partitioning.
I’m sorry, I am a real amateur when it comes to using Knime…
I have been able to share the workflow with you. I hope some things get clear by having the complete workflow. I am again really sorry about my lack of knowledge about Knime.
No problem at all. I just had a quick look at your excel file and its content explains the kind of problems you are facing: your column to predict “actual_productivity” is numerical with very diverse values, not nominal, even if you convert it into a string type:
You are trying to solve the prediction of a numerical value as if it were a class with nominal values. Obviusly this is not a classification problem (hence not a problem to give to a Decision Tree training node) but a regression problem which should be tackled using for instance the “Simple Regression Tree Learner”.
Please have a look in the KNIME forum or hub at the many examples were the problem of Numerical Values prediction using a regression models has been demonstrated:
Finally, the reason why you were getting this weird message is that if you convert a very diverse numerical value into a string, you partition it (split it) and you do training and testing separately, the most probable is that “classes” (if we can call them this way ;)) that are present in the testing set were not represented in the training set and obviously the Prediction node cannot handle them and complains. That’s why