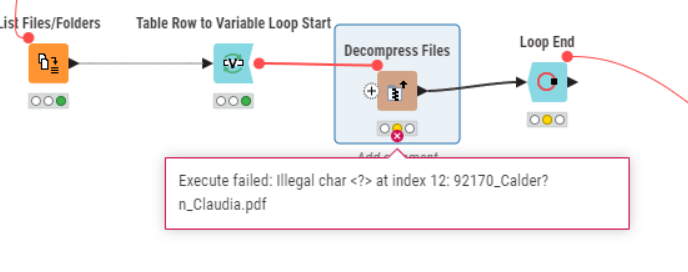
I am unzipping a .zip file that has files inside that may have accents in their names. When pasting the files into the destination folder it changes the accented letter to a question mark (?), and under these conditions the file cannot be copied and the node fails. In a previous post (2021) it says that they have it on a ticket to fix this issue, but apparently it still persists.
Thank you very much. I appreciate the proposed solution, however, where I need to implement it they have a python restriction.
Can you think of anything else?
Thanks
I’m using Windows. I’ve been traying to make the extraction with a java snippet but the available library to do it is the filesystem one, but has the same restriction so I think is the same the node uses. There is another one named Apache Commons Compress, but the package is not in the KNIME installation so I’m trying to know how to put it available.
Any other idea?
@mlauber71 is the same problem really. I use to have problems installing extensions with that client, so I usually have to solve everything with basic nodes.
The Apache Commons Compress library provides a functionality to decompress .zip files no matter what format the filenames are in. So, I downloaded the .jar library and added it from the Java Snippet Libraries tab, which enabled the use of the library in the node. Then I just did the code and it worked!!! I leave the code in case any of you find it useful!
// Path of the .zip file you want to unzip
String zipFilePath = “pathToZip/file.zip”;
// Destination folder where files will be unzipped
String destDir = “PathToDestination/Destinationfolder/”;
// Create a ZipArchiveInputStream object to read the .zip archive
try (ZipArchiveInputStream zipIn = new ZipArchiveInputStream(new FileInputStream(zipFilePath))) {
ArchiveEntry entry;
// Iterate over each entry in the .zip file
while ((entry = zipIn.getNextEntry()) != null) {
String entryFileName = entry.getName();
// Construct the full path to the file
String entryPath = destDir + entryFileName;
// If the entry is a directory, create the directory
if (entry.isDirectory()) {
File dir = new File(entryPath);
dir.mkdirs();
}
else {
// If the entry is a file, extract the file
File outFile = new File(entryPath);
// Create the necessary directories
new File(outFile.getParent()).mkdirs();
// Write the contents of the file
try (FileOutputStream fos = new FileOutputStream(outFile)) {
IOUtils.copy(zipIn, fos);
}
catch (Exception e){
out_catch =e.getMessage();
}
}
}
}
catch (Exception e){
out_catch2 =e.getMessage();
}
@lsandinop I’m currently looking into a closely related problem where non-ASCII characters in file system paths don’t work properly. Could you execute the “Extract System Properties” node in your AP and report all properties containing encoding?
I’ve been creating a workflow to upload it here and I saw that the error occurs when I zip the files with the default Windows zipper. I mannaged unzip the files but the lose the accents and the “ñ”.
Here you can see a workflow with the java script to decompress zip files with files that have special characters.
While looking for the solution I realised that the problem is mainly in the files compressed with the default Windows compressor. I tried the Decompress node with zips created with other tools and it extracts perfectly the files with accents and ñ, but with the ones created by the Windows compressor I couldn’t do it with the node, and I had to adjust the Java Snippet to replace the special characters with “-” and I could write the files.
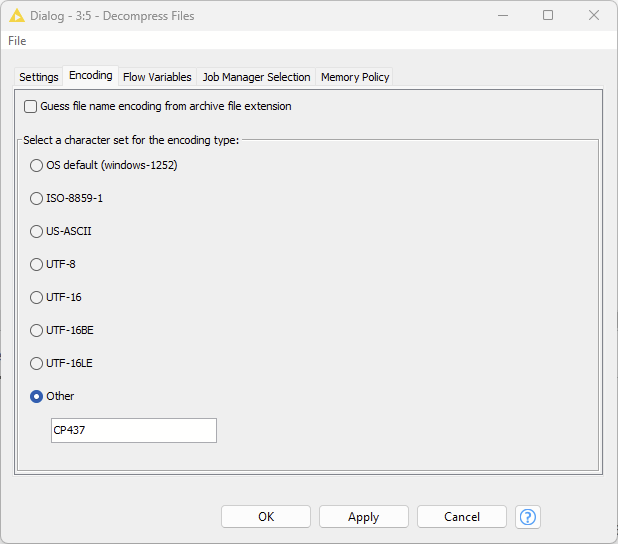
The Decompress Files node can be configured to either use a specific encoding or guess it from the extension. The default encoding for .zip is UTF-8, but your ZIP file uses CP437 to store the file names. So if you go to the “Encoding” tab in the node settings and set the encoding to “CP437”, your ZIP should extract fine.
I know this solution is not perfect (you have to know the encoding first), but it’s very hard to find a universal solution and UTF-8 works in most cases.