hello
I want to delete the duplicate data at the db level, please introduce me the relevant node or workflow.
Hi @alex1368,
You can use DB Query node to delete data directly from your database
for eg use this query to delete data
DELETE FROM your_table
WHERE id NOT IN (
SELECT MIN(id)
FROM your_table
GROUP BY Product
);
Regards,
Yogesh
1 Like
Hi @yogesh_nawale and @alex1368 ,
if you want to execute a data manipulation statement that permanently alters your data in the DB please use the DB SQL Executor.
If you only want to eliminate the duplicates when retrieving the data but don’t want to do this permanently in the DB you can use the DISTINCT command e.g.
SELECT DISTINCT * FROM #table# AS "table"
in the DB Query node.
Bye
Tobias
2 Likes
@alex1368 if you have more complicated scenarios you can use the WINDOW function in SQL (depending on your database) to have more control about what duplicate you want to remove.
Write me a piece of code for a db query that reads my SQL table and deletes duplicate rows.
Preferably, the code should be such that there is no need to write the names of the columns
Explanation: I want to read the information code in the table line by line and delete it if there is a duplicate line.
That should do the trick since it is independent of any column names and will only return the distinct rows.
Tobias
2 Likes
Hi @alex1368,
May be you can try something like this.
For eg this is my table

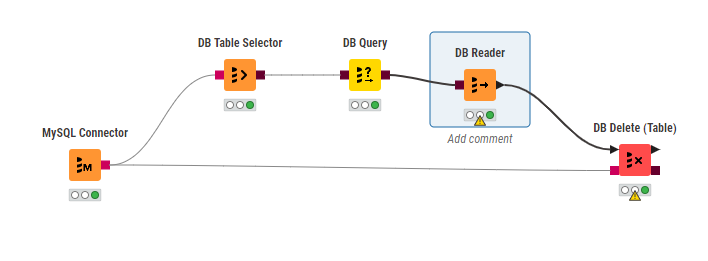
Steps
- Select table using DB Table Selector node
- Using DB Query node find out the duplicates.
This SQL query is designed to identify duplicate rows in a table based on the combination of theFirstName,LastName, andDepartmentcolumns, and it returns only the duplicate rows (i.e., the rows withrow_num != 1).
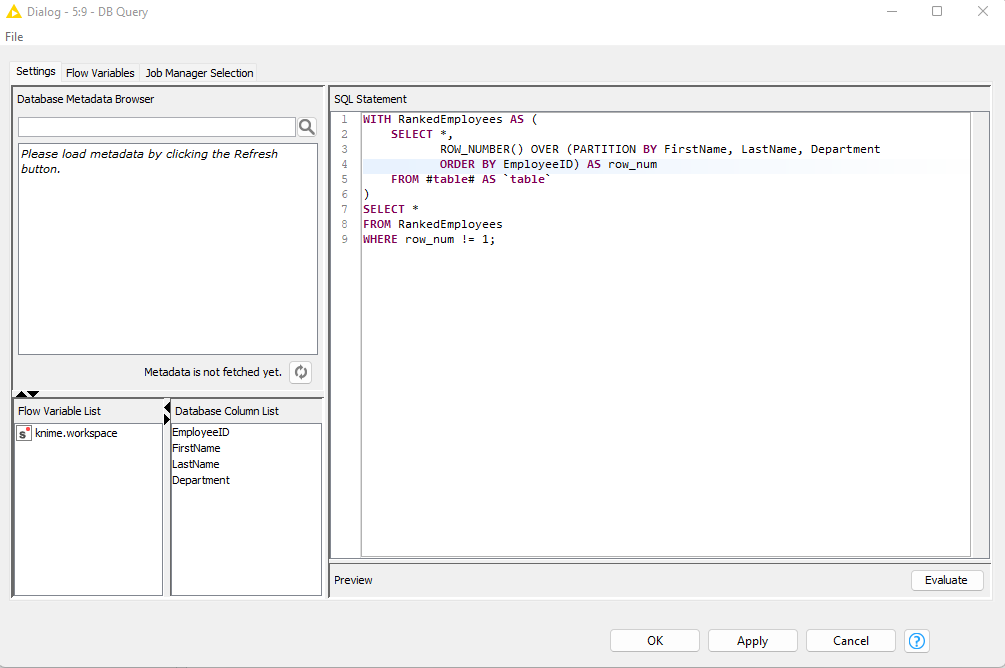
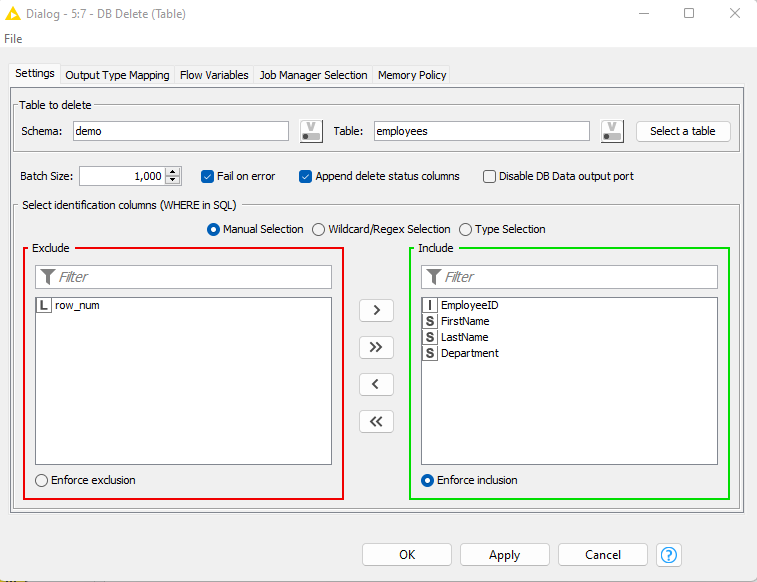
- Use DB Delete(Table) to delete this duplicate rows
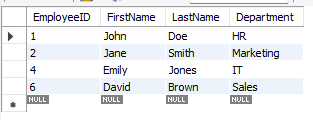
- My output table
Delete duplicate information at the db level.knwf (81.1 KB)
See if it helps
Regards,
Yogesh
2 Likes
thank you
Your answer was much more than I expected, thank you
1 Like
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.