Hi,
Is it possible to delete everything in a excel cell after a defined name? There are many cells where the first part is the same (the name of an organization) and the second part is different in every cell (the department within the organization).
Is it possible to delete everything in a cell after a defined name? So when I have a list as follows:
XX AA
XX BB
XX CC
YY AA
YY BB
YY CC
How can I delete everything after XX and YY to have only XX and YY in my list in the end.
Welcome to the forum @JulianK98.
There are several ways to do this, but I would use a String Manipulation node to replace everything after the first 2 characters with nothing:
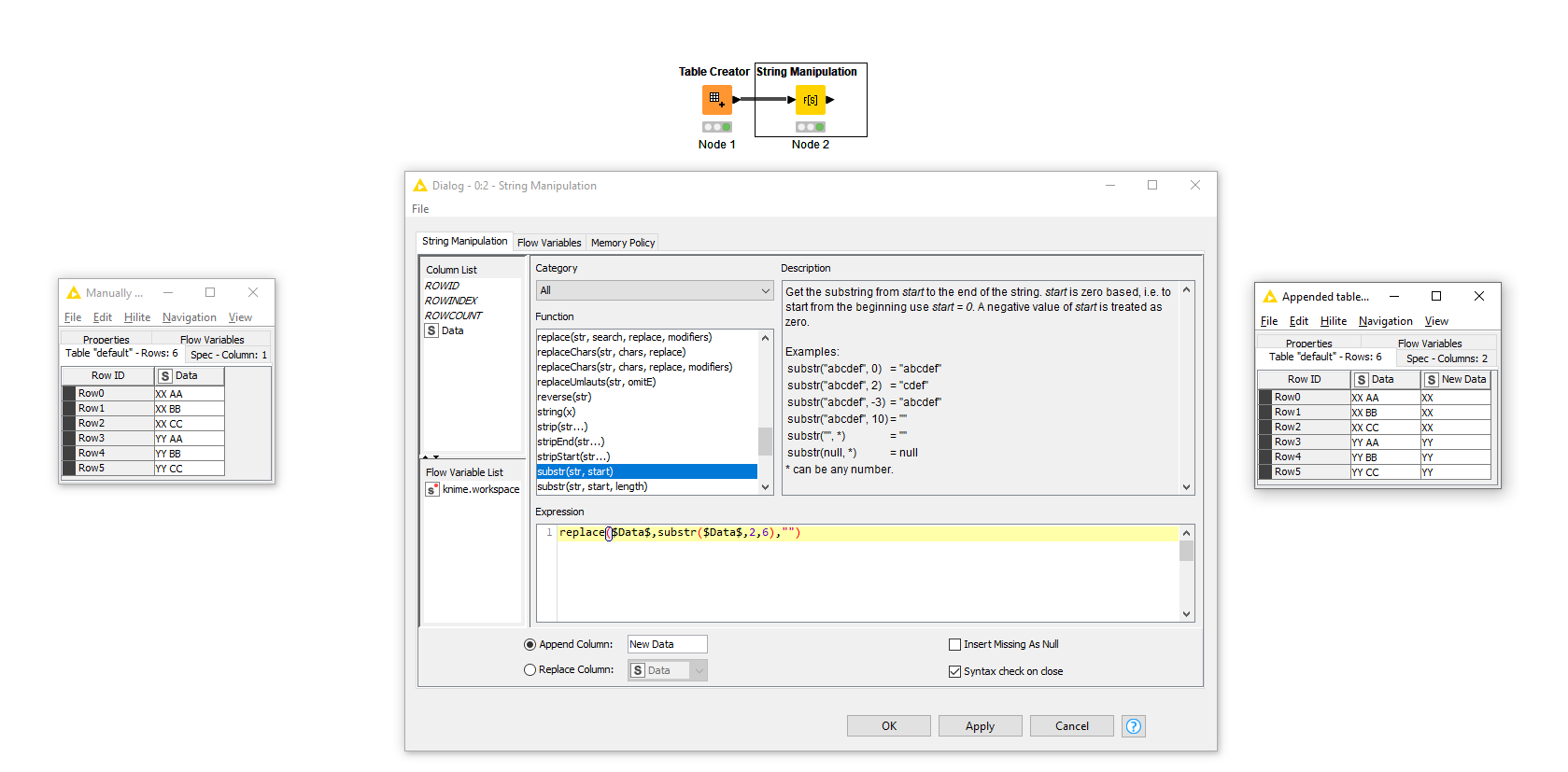
Hi @elsamuel , it’s probably to do the other way around, that is extract the first 2 characters only ![]()
substr($Data$, 0, 2)
1 Like
Thank you, that’s close to what I want.
But the real list contains of different names of organizations and departments in these organizations. So let’s say we have Google Procurement, Google Marketing, Google Research, Apple Procurement, Apple Marketing, Apple Research, Apple HR and so on. (The real list is much longer). Now I want to delete everything after the Word Google, Apple etc. so that I have a List which only contains the organizations. In this case, I think it won’t work to simply replace everything after some characters.
Maybe one thing would work with your solution above: Can I somehow choose the rows in which I want to delete characters. Then I could delete everything after the 6th character in all the rows of “Google”, everything after the 5th character in the rows of “Apple” and so on
In the future, it would be best if you provided realistic example data and/or a workflow for us to work with.
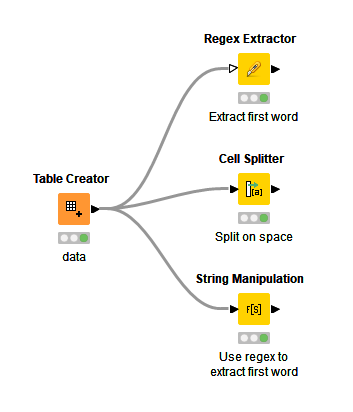
A couple possible solutions for keeping only the first word:
- Use a Cell Splitter Node with a space as a delimiter
- Use ReGex in a Regex Extractor, Regex Split, or String Manipulation node to extract the first word
1 Like
Your proposal in the string manipulator allows me to delete everything after the 10th character in the column.
replace($CAE_NAME NEU$,substr($CAE_NAME NEU$, 10, 100),"")
Is it possible to do this for a specific range of rows not just for the whole column?
Sorry, maybe I’m asking dumb questions but I am absolutely a beginner.
You can conceivably use the Column Expressions node with a series of if-then statements that contain the replace and substr functions (or just the substr function as @bruno29a pointed out). However, I don’t see why you’d want to go that route when there are simpler and more generally applicable options.
1 Like
Yes by splitting the rows with row splitter ,apply transformations and concatenate them back together.
I would also assume regex would be a good option (without seeing your data here)
br
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.