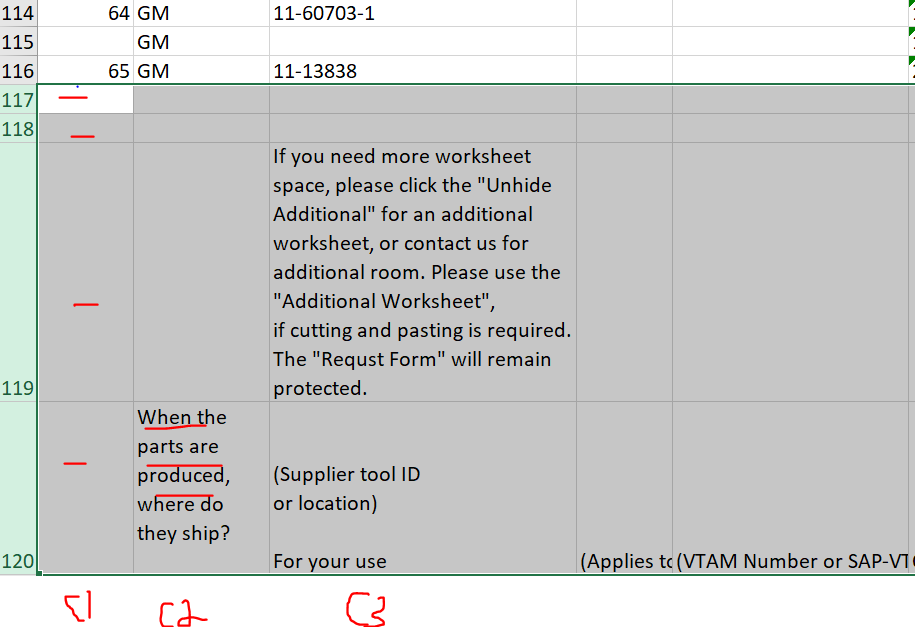
Hi everyone, I have a table which is made out of several excel files and certain worksheets with in those files. I need to join all the worksheets which are same. i have managed to do this but there is alot of extra data in my tables that is not needed. the reason i need to remove it because i would need to sum certain columns later on. so, there are totals in those columns that are not needed because it will ruin the sum later on. So basically, if I find a certain string character in a column i need to remove that row and three rows before it. How would i go about doing that. So when i find the string “When the parts are…” in column2, i need that row and the3 rows before it to delete (highlighted).
Welcome to the KNIME community!
Is that pattern of column2 always the same? Meaning that after the last valid records, it’s always a few empty rows until “When the parts are…” after which the next sheets starts.
Because if it is, you can use something like this:
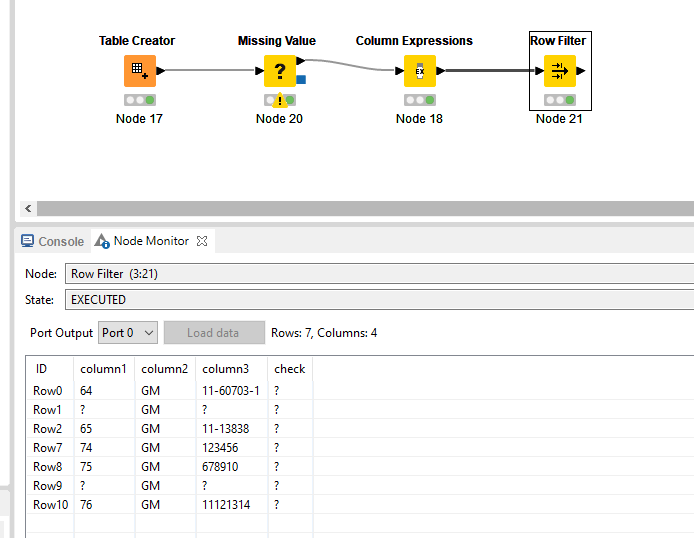
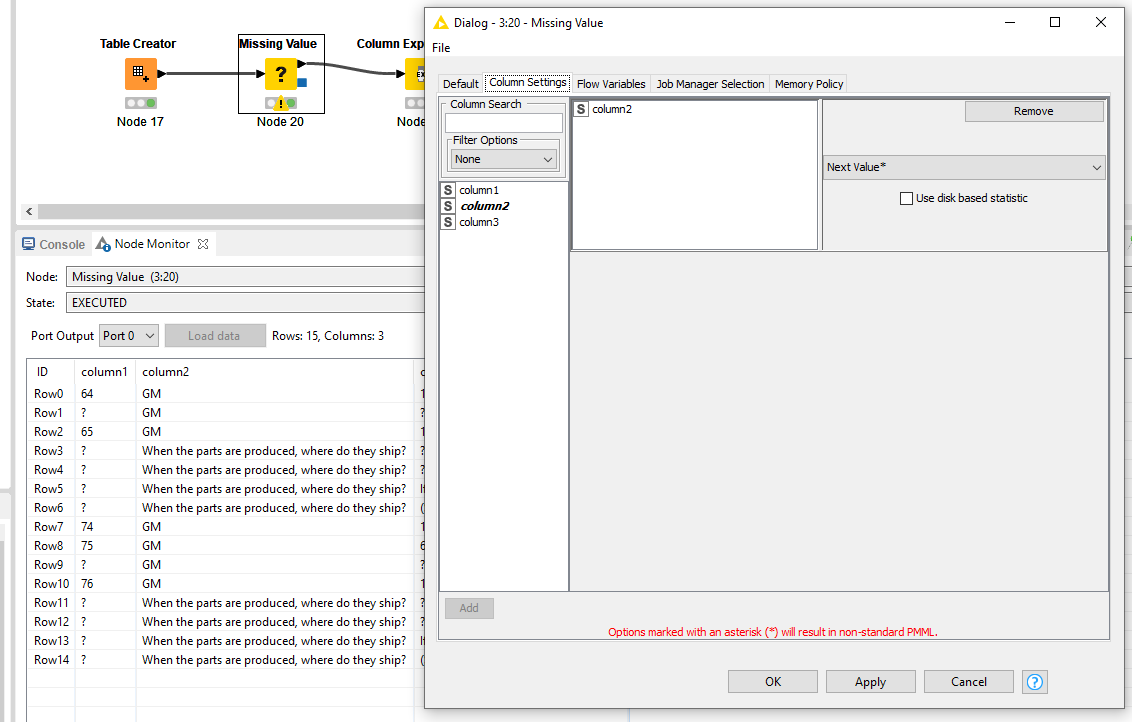
With a missing value node, replace the nulls in column 2 with the next value.
Then determine which rows contain “When the parts are…” by using
if (contains(column("column2"),"When the parts are") == true) {
1
} else {
null
}
Alternative a Rule Engine with
$column2$ LIKE "*When the parts are*" => 1
TRUE => 0
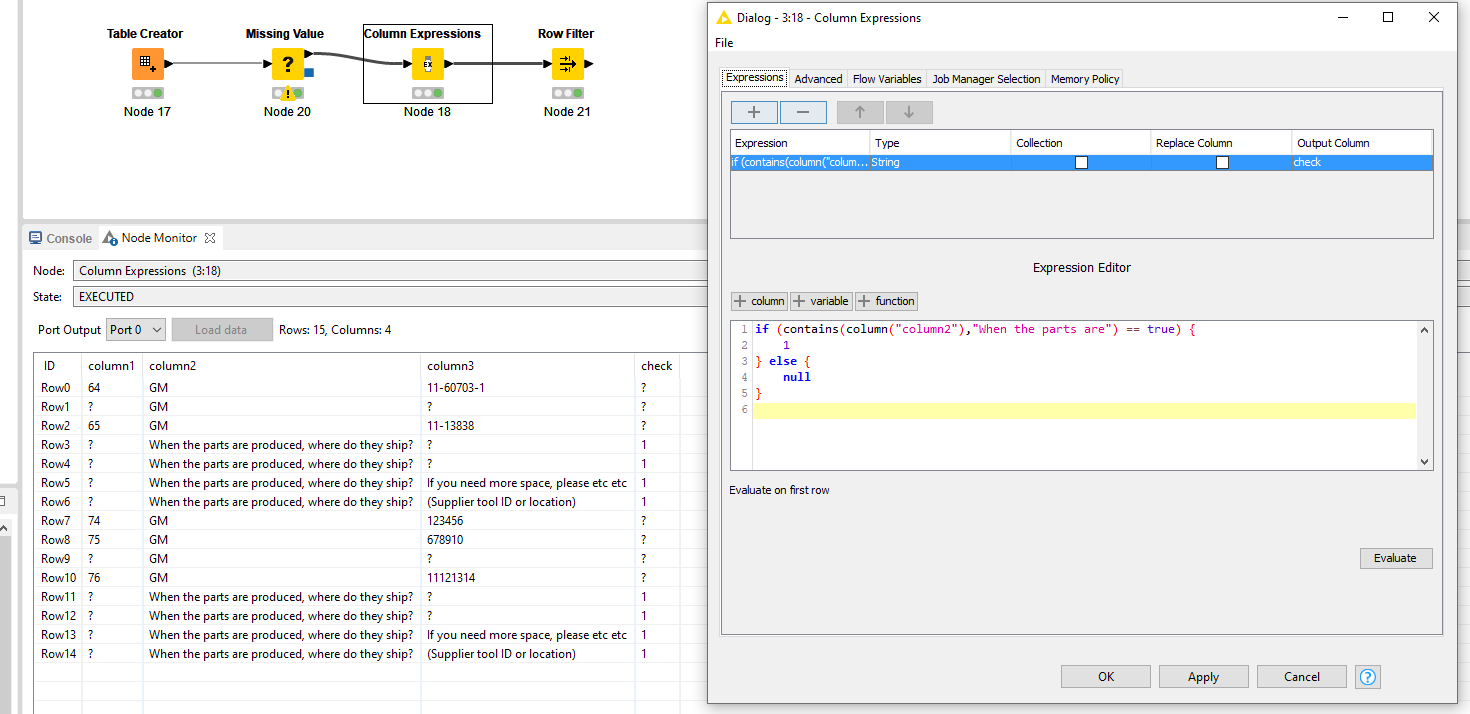
Then exclude where the check value is equal to 1.
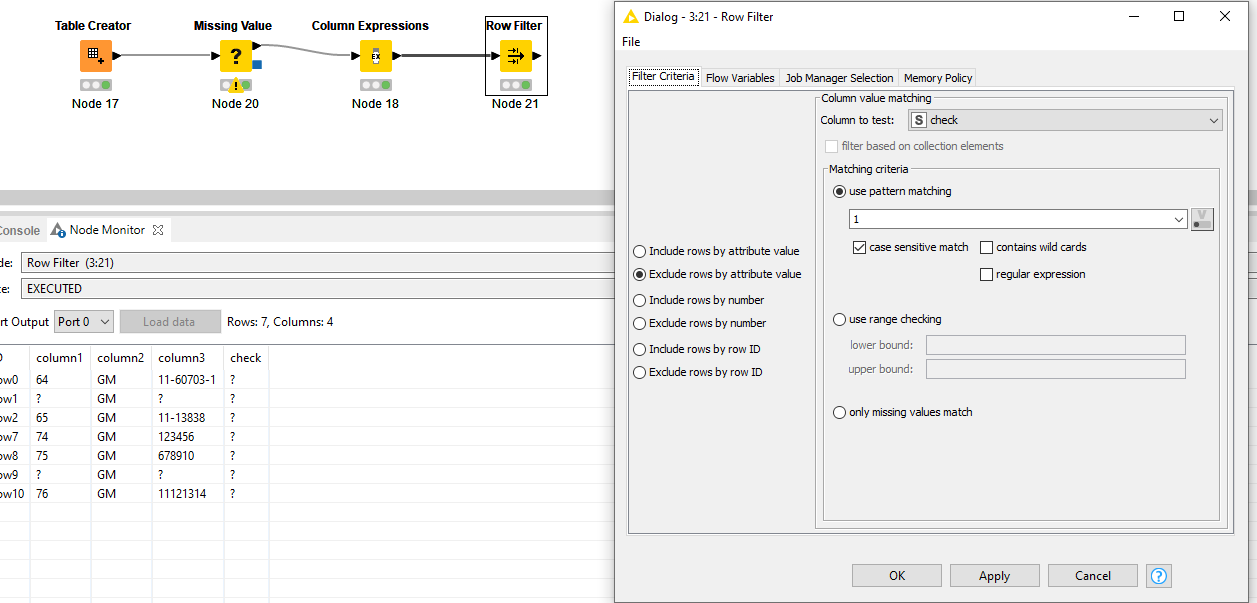
4 Likes
This is great solution. But there is one issue here. Sometimes in Column 2 there are numm values in some sheets. so it is not always GM. but you are right in assuming that after the last valid records there are a few empty rows and then the “When the parts…” cell starts. that is the start of the new sheet btw.
I will show you what the second sheet looks like:

You see that the new sheet starts with “When the parts are …”. but the rest of the column in this new sheet is empty. but Column 1 starts with 1 again. I am not sure how to mark the end of one sheet and the start of new one. I was thinking if there is an expression that i can write that whenever column 2 encounters “When the parts are…” it should delete that row and the preceding three rows before it. Not sure how to do that though.
1 Like
Such a dynamic offset is quite a difficult thing to properly implement. I’m thinking it could still be achieved in a similar way based on the combination of the values of the different columns but it’s very hard to judge its correctness due to the small example that you have provided.
One pattern could be when column1 is null and column2 is null or column2 contains When the parts are …
Input:
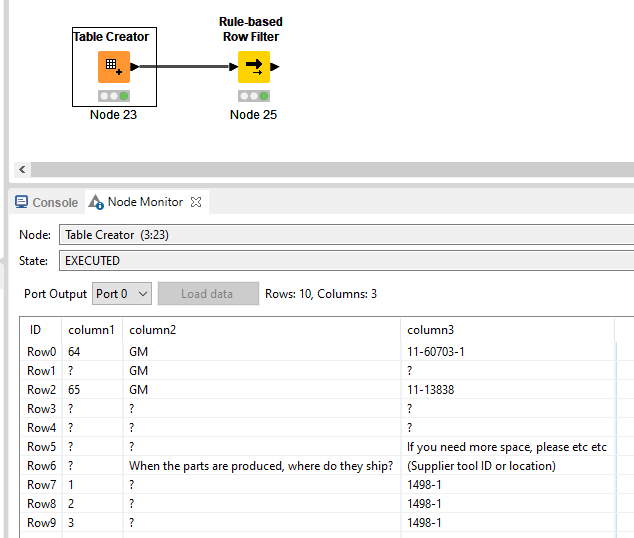
Rule Based Row filter:
(MISSING $column1$ AND MISSING $column2$) OR $column2$ LIKE "*When the parts are*"=> TRUE
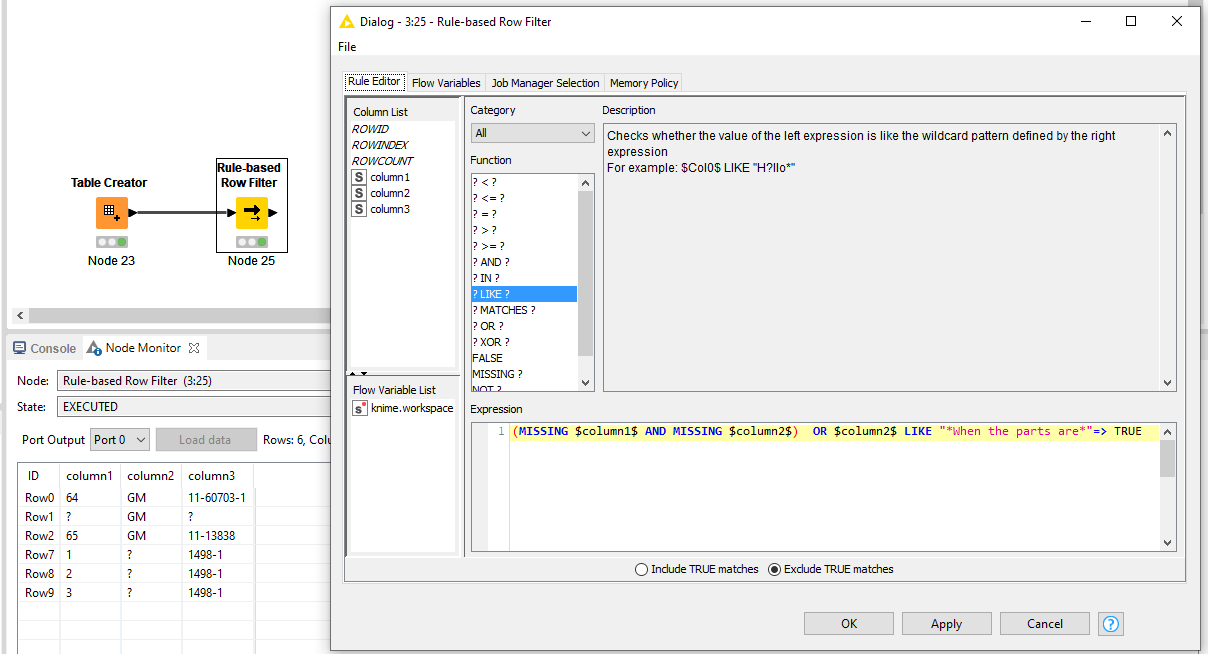
Again, this would work based on the small sample but there could be other cases.
5 Likes
Oh wow this works so perfectly! that’s exactly the rows i needed to filter out. Thank you so much for your help I really appreciate it!!
Another solution i was working on was to combine two of the columns and then “Mark” the start of the rows and the end of teh rows based on a regular expression.

But none of my regex were being accepted by the Row Filter node. This is what i was trying. Can you tell me what i am doing wrong here? I might actually need to use this method later on.
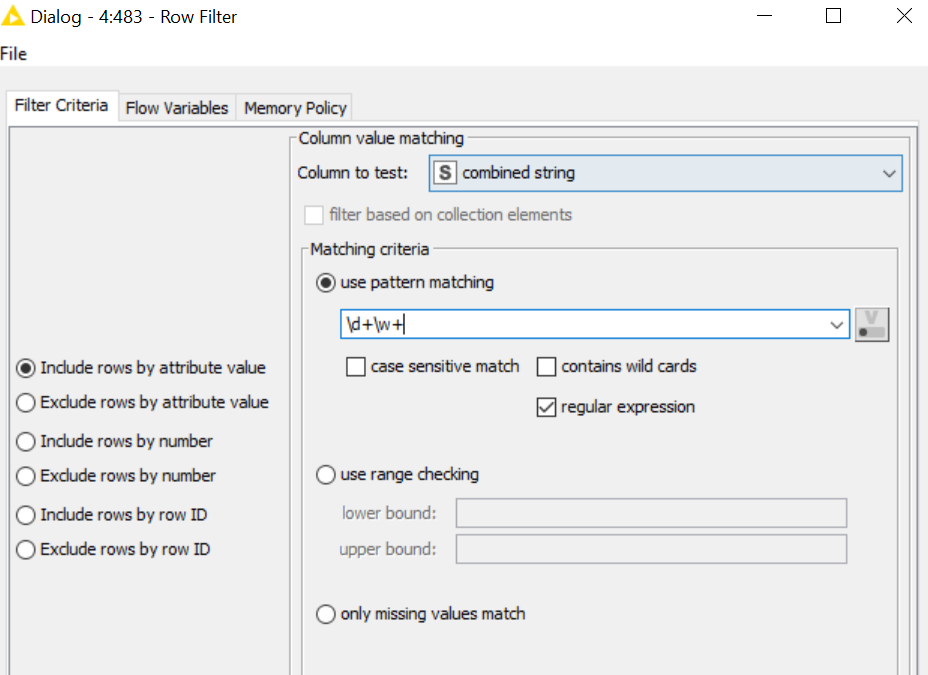
1 Like
When using Regex in KNIME you need to escape special characters which includes slashes, so the correct expression would be \\d+\\w+
1 Like
Thanks once again:) This helps a lot. I am not sure why different nodes require different flavors of Java in knime. For example, Column expressions and Rule engine etc. I wish there was some documentation or a cheat sheet of sorts that could make it easy to learn.
Regarding dealing with regex → Go to regex101.com , construct your expression accordingly based on a data sample, click on Code Generator, select Java and copy the contents of final String regex to KNIME and it will work accordingly.
3 Likes
@zainabzeeshan as it happens I have tried to implement a set of multi-column conditions in another example (positive and negative ones) and based on the aggregated combinations of true and false have then selected rows that would meet the conditions. Although me being late to the party you might want to take a look:
1 Like
Good reference!
I had something similar on the shelf ready to go in case the others solutions were not sufficient for the use case mentioned in here . The access features are definitely a good option here. I opted for the start and ending RowIndex and use them as flow variable in a row filter.

2 Likes
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.