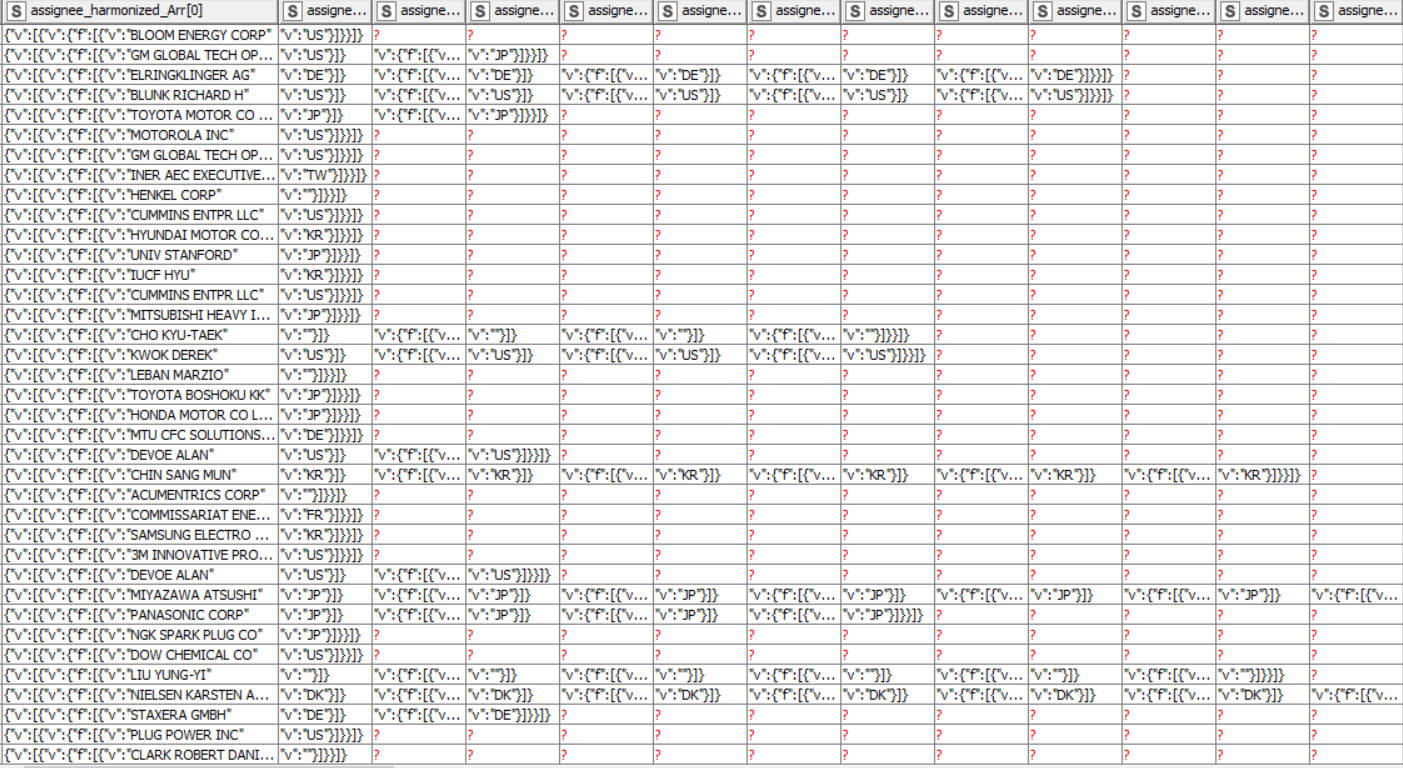
I try to delete specific characters as you can see in the picture.
For example for the first cell in the first column →
{“v”:[{“v”:{“f”:[{“v”:“BLOOM ENERGY CORP”
I like to delete everything except of BLOOM ENERGY CORP
MY LOGIC is that every letter and character should be deleted except of the big letters A,B,C…Z and numbers 0,1…,9.
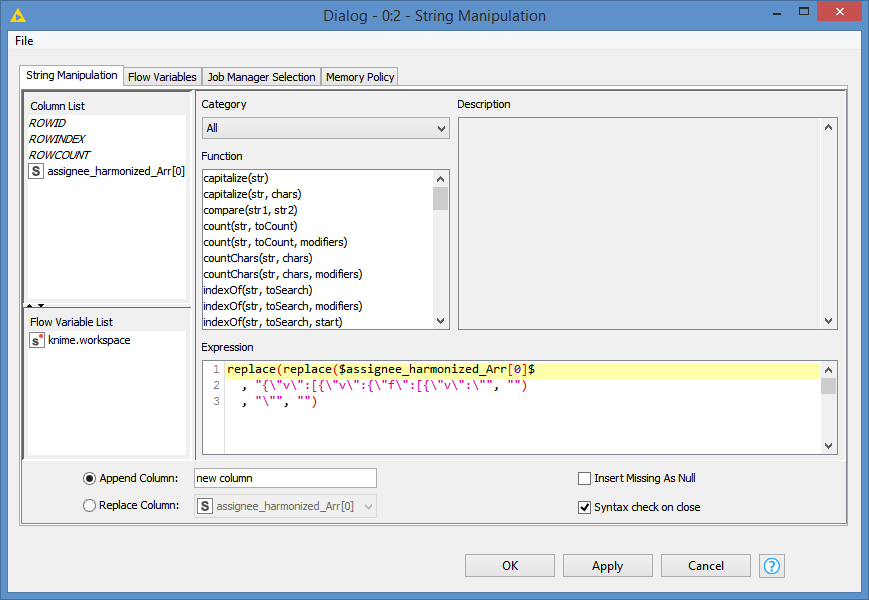
Hi @8bastian8 , you can use regex if you want to apply your logic, or, based on your screenshot, the data looks like to be some sort of extract, and it seems to be quite consistent with having your data in the first column as this: {"v":[{"v":{"f":[{"v":"YOUR DATA"
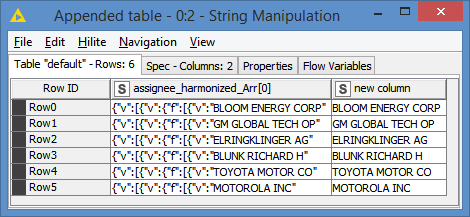
So, you could just remove the {"v":[{"v":{"f":[{"v":" at the beginning, and the closing quotes " at the end. Both removals can be done via a single String Manipulation:
Wonderful solution @bruno29a !
How can I use this logic for multiple columns?
Is it possible to use this method for more than one column and create more than one new columns at the same time?`
now I like to preceed with every column like this:
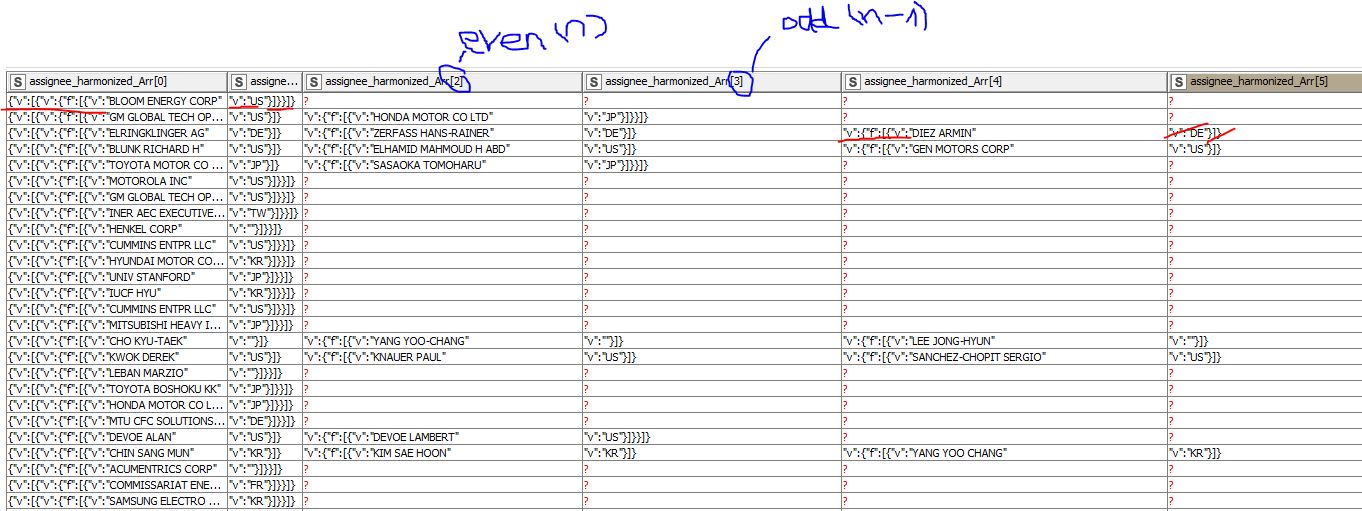
CASE1: when I have columns like $assignee_harmonized_Arr[0]$
→ I like to use the replacement of @bruno29a. CASE2: when I have columns like $assignee_harmonized_Arr[2*n+1]$ (odd number)
->“v”:“US”}]}}]}
->“v”:“JP”}]}}]}
Etc… the Number of closing brackets is different CASE3: when I have columns like $assignee_harmonized_Arr[2*n+2]$ (even number)
->I like to use another precedure to replace all characters for example for these entries:
examples:
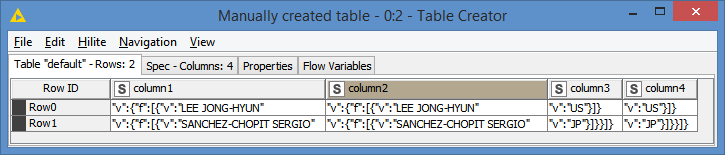
“v”:{“f”:[{“v”:“LEE JONG-HYUN”
“v”:{“f”:[{“v”:“SANCHEZ-CHOPIT SERGIO”
Here the entries are similar to the first case…
I attached you a picture for a better understanding of my logic…
Hi @8bastian8 , as I pointed out, there was a constant string that was there in that first column.
Now, you have changed the requirement, and the approach should be different.
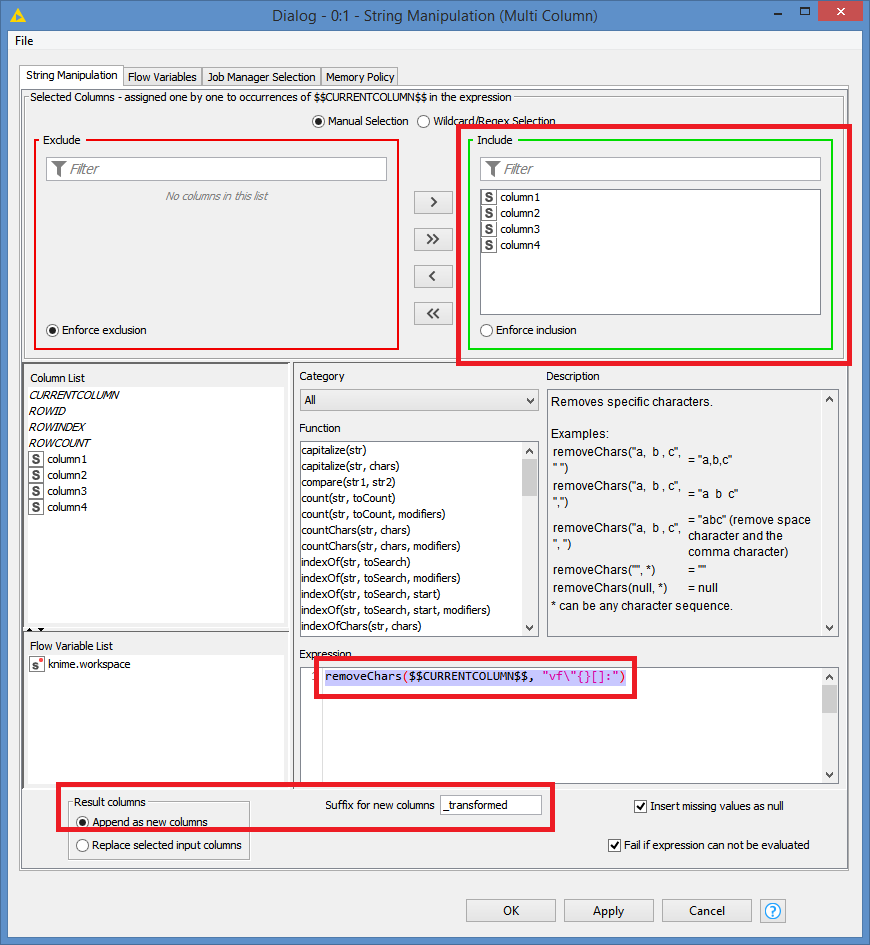
Looking at all the data in all the columns from your workflow, it looks like we just want to remove each of the following characters: v f " { } [ ] :
And we can apply this removal to all of the columns - no need to check for odd/even. For my test sample, I’ve copied the same column twice, consecutively, to break the odd/even sequence, like this:
Notice also for the US, the pattern is different from the JP one (that’s what I saw from your screenshot). It does not matter in the end, as Knime will look for the characters I mentioned above, no matter how many times they are repeated in the data.
So, I just apply this rule to the String Manipulation (Multi Column): removeChars($$CURRENTCOLUMN$$, "vf\"{}[]:")
You can decide to add the manipulated data as new column, in which case you can add a suffix to identify the new columns, or replace the original columns. In my case I will append new columns with suffix “_transformed”