Hello,
I use this workflow i found in the hub.
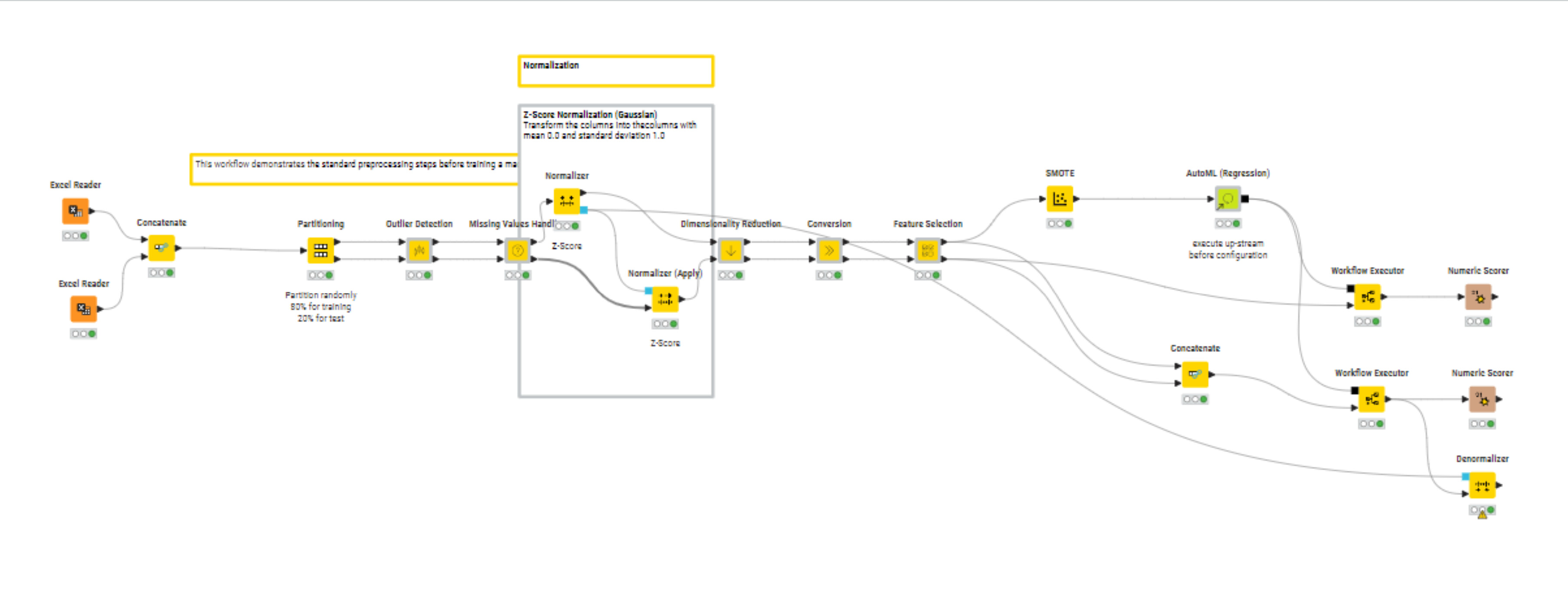
I want to denormalize the Prediction column. What am i doing wrong ?

Thanks
Hello,
I use this workflow i found in the hub.
I want to denormalize the Prediction column. What am i doing wrong ?
Thanks
Hi @Brain -
Just going off of screenshots alone I’m not sure. Can you upload the workflow itself in progress, along with a mention of the warning message you’re seeing in the Denormalizer node?
Just for reference, here’s a workflow you might want to look at further:
HI @ScottF
Thanks for your answer.
Following your example i have a problem :
Quality is denormalize
Prediction Quality is not denormalize.
04_Data_Preprocessing_for_ML_Models1.knwf (2.4 MB)
The features have change of name and are not denormalize that is logic.
Thanks
Nobody has an idea ?
I took a look. I had to go find the wine quality dataset you used since it wasn’t included in the workflow you uploaded.
You’re trying to denormalize columns that no longer exist by the time the data makes its way to the Denormalizer node. These columns are being removed in the Dimensionality Reduction component, but it’s not immediately clear to me why. You might try digging there.
@Brain if you used an initial normalization of the Traget column and now want to use the same settings on the Predicted Target Column then you would have to temporarily rename the column and do the denormalization and then rename it to the original name like “Target (Predicted)”
You save the normalization of the Target variable in a separate (PMML or zip) file so to be able to specifically use this later individually.
You can explore the example how to use this for housing prices for “MultiLayerPerceptron Predictor”.
Another remark: if you use the Wine Quality dataset. This can be interpreted as a multi-class task besides the quality being recorded in integers. Technically you can also treat this as a regression although this also might be misleading and you will in the end have to make a decision what to do with a float number.
These things will need some planning …
EDIT: besides the mentioned points you might want to check the whole setup of your workflow. The example you used (Data Preprocessing for ML Models – KNIME Community Hub) walks you thru several steps and combines domain knowledge with some analytical insights (outliers) and then does some data cleaning. Maybe you also check again the steps taken and try to adapt them to your case.
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.

