Hi,
I have normalized my dataset to train my MLP. After using the PREDICTOR node, a new column is appended to the dataset with the predicted values. But the “Denormalizer” node does only denormalize all other columns but not the one with my predections. But that’s exactly what I need because I want to compare the values of the new column with one column which is already included in the dataset. I’m really lost with that, can someone help me out?
Best
Hi
I would not normalize my target variable. Only the features
bR
2 Likes
Hi
Unfortunately, that‘s not an option. The RProp MLP Learner is requesting all columns in range [0,1] and is therefore not running. I‘m quite frustrated as the neural network is working smoothly but I really need to get the predection denormalized, otherwise it‘s useless. I tried two denormalizer in a row but can‘t get it right.
Other ideas?
Best
Is it possible to have 2 separate normalizers in this case? If not you could also scale your target class using nodes like Math Formula or Columnexpressions yourself
1 Like
Hello @SirMike,
and welcome to KNIME Community!
Prediction column needs to have same name as in Normalizer node. Check here:
Br,
Ivan
I’ve Seen this Post before. When I do so, there‘s an error message from MultiLayerPerceptron Predictor: Configure failed: duplicate column names at position 5 and 12…
Hello @SirMike,
if I got it right after predictor node you have to split prediction column from all other columns (using Column Splitter node for example or even better Reference Column Splitter node where reference table is one from partitioning node). Then apply denormalizer on both output ports. As said columns names need to match so rename prediction column (Column Rename) to target column name between splitting and denormalizing. Give it a try and if you need workflow example drop me a message and can create one.
Br,
Ivan
1 Like
Yes. I just had to do this. It’s pretty tedious and requires 5 extra nodes in order to be able to get back to a target column and a prediction column in order to use the scoring node downstream. I wonder if there’s a way to somehow manipulate the model output from the normalizer node to include the prediction column?
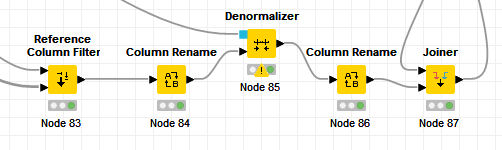
Hi Ellie
I think, I’m too stupid really. Now, the predicted column from the predictor does not get together anymore with the data from the test set in the reference Column Filter. Could you have a look at the screenshot and tell me, where I get things wrong?
M
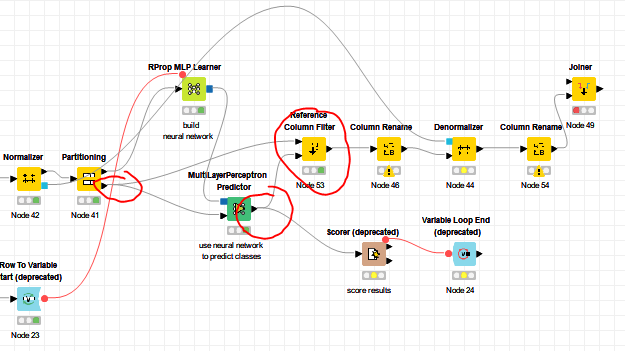
Believe me, I get your frustration. In looking back, I was wrong when I said i had to add 5 extra nodes. It was actually 6! I also had to add a denormalizer node after the predictor to first denormalize the target column, then my 5 nodes to filter down the columns to just the prediction column, change its name to the target column, apply the denormalization, change its name back to the prediction column and then join back to all of the other columns in my table. Whew!
Here’s a broader view of my flow with both denormalization nodes:
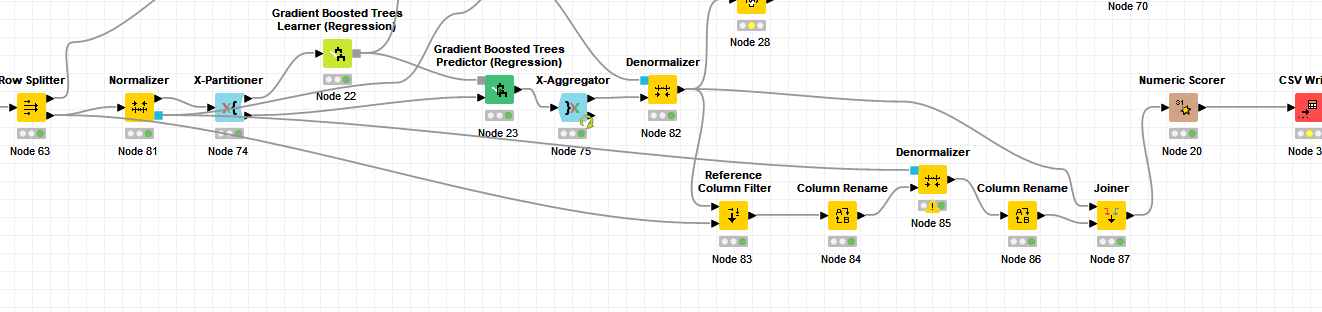
1 Like
Not sure if you’ll be able to make sense of my chicken scratch, but this is what I think you need to do.
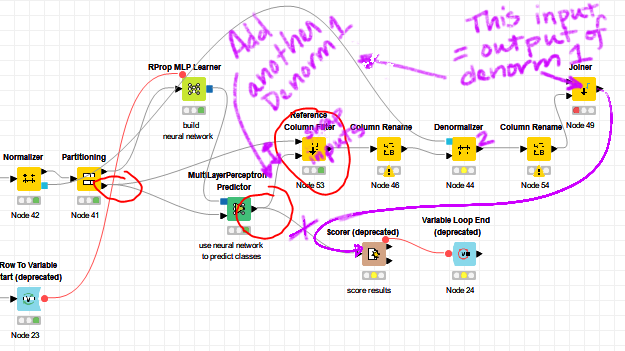
Hello @SirMike,
in case you still haven’t managed to denormalize your predictions here is workflow example on KNIME Hub that should help:
Br,
Ivan
2 Likes
Thank you so much Ivan, it works perfectly now, finally!
BR
Mike
1 Like
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.