Here is an example. The primary key is ID and is used to identify the records.
|-----------------------------------------|
| ID | Name | Qty1 | Qty2 | Last_update_on|
|-----------------------------------------|
| 1 | Tom | 1 | 2 | 2020-01-01 |
| 2 | Ann | 3 | 4 | 2020-01-02 |
| 3 | Els | 5 | 6 | 2020-01-03 |
|-----------------------------------------|
I would like to merge with the following table.
|-----------------------------------------|
| ID | Name | Qty1 | Qty2 | Last_update_on|
|-----------------------------------------|
| 1 | Tom | 7 | 8 | 2020-05-14 |
| 2 | Ann | 3 | 4 | 2020-05-14 |
| 4 | Ron | 9 | 1 | 2020-05-14 |
|-----------------------------------------|
I would expect the result to be
|-----------------------------------------|
| ID | Name | Qty1 | Qty2 | Last_update_on|
|-----------------------------------------|
| 1 | Tom | 7 | 8 | 2020-05-14 | (1)
| 2 | Ann | 3 | 4 | 2020-01-02 | (2)
| 3 | Els | 5 | 6 | 2020-01-03 | (3)
| 4 | Ron | 9 | 1 | 2020-05-14 | (4)
|-----------------------------------------|
(1) This record was existing and had Qty1 and Qty2 updated => timestamp updated
(2) This record was existing but has not been changed => timestamp not updated
(3) This record was not in the merge, so it stays and remains unchanged => timestamp not updated
An alternative behaviour could be to remove the record (or to add a flag “DELETED = Y” and update then the timestamp.
(4) This record is new (i.e. new ID) and is added to the table => new timestamp
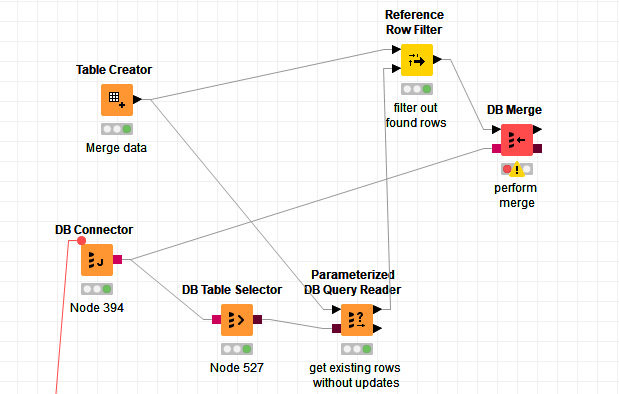
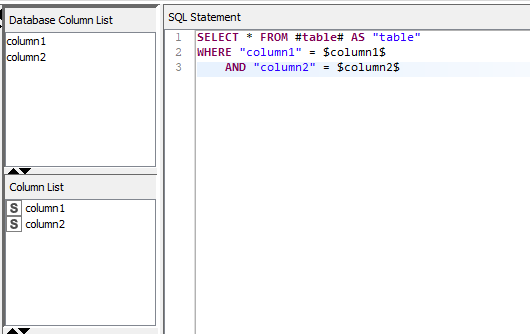
This seems to be a pretty common behaviour for an ETL-type job for a datawarehouse. Usually, with a bit of effort, I always manage to achieve what I need to do with Knime. But in this case, the solutions I have in mind seem too complicated for such a common task. So I ask on the forum. So maybe there is a magic node or a magic trick that this great community will help me to find… 
@AnotherFraudUser, if I understand well your proposal, it would not take into account properly the (2) and update the timestamp while I would need to keep it at 2020-01-02 (to know that this record has changed on 2020-01-02 and not on 2020-05-14).
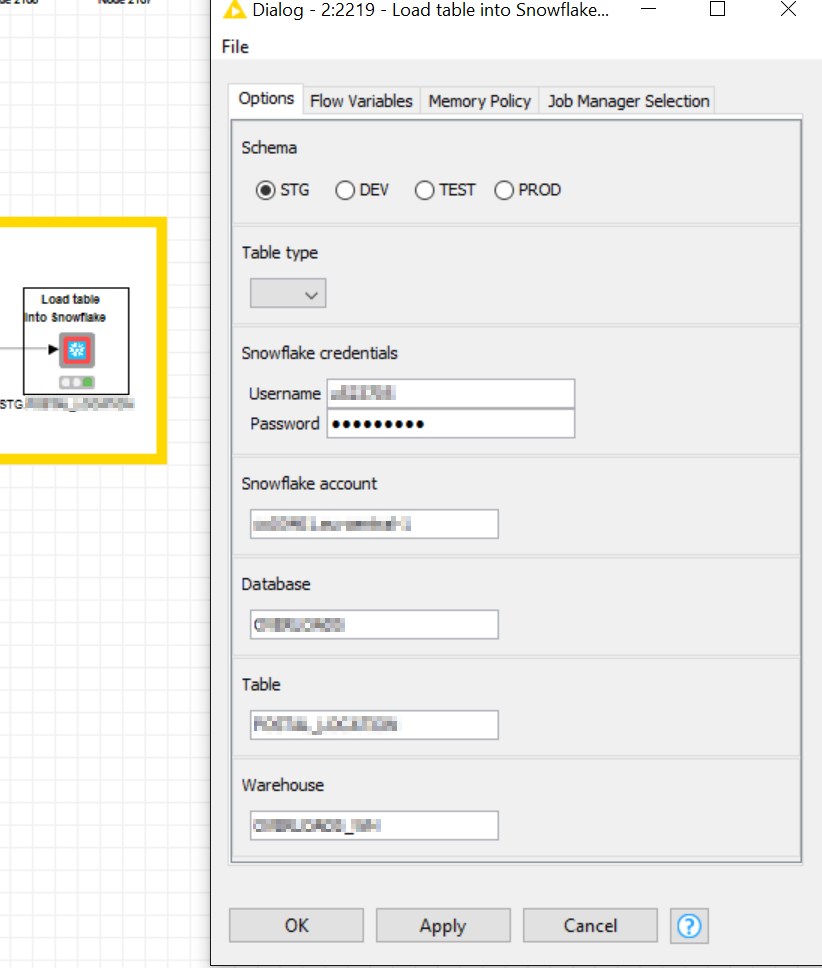
FYI, I am trying to develop a sort of generic and configurable component to “Load table into Snowflake”. For now, I rebuild the table from scratch at each load, but the incremental merge would also be interesting.