Greetings Knimers, hope everyone is well.
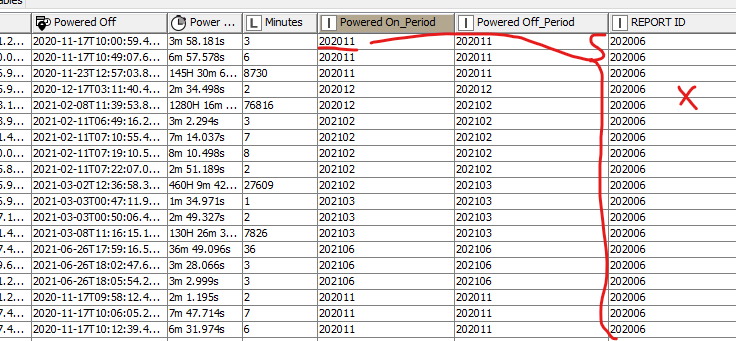
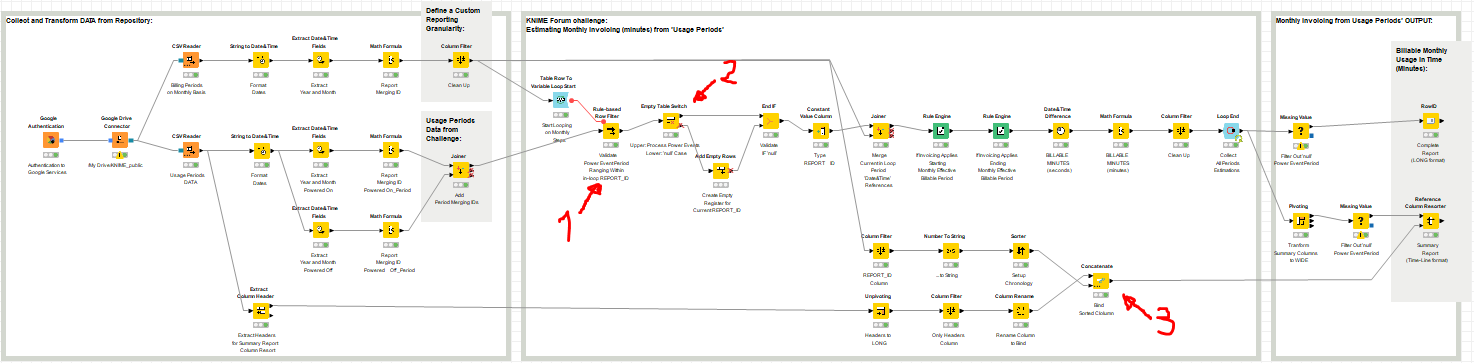
I have server farm power usage data, periodically provided as csv, containing records per server, spanning a range of months. In those records one can see, per server, power On/Off events: sometimes they are minutes apart, sometimes hours. This usage needs billing on a monthly basis and to achieve this I can pivot the server power event data into columns for “Power On date/time” and “Power Off date/time” and then use wonderful tools like the Knime “Date & Time Difference” node to accurately demonstrate the period a given server was powered on for.
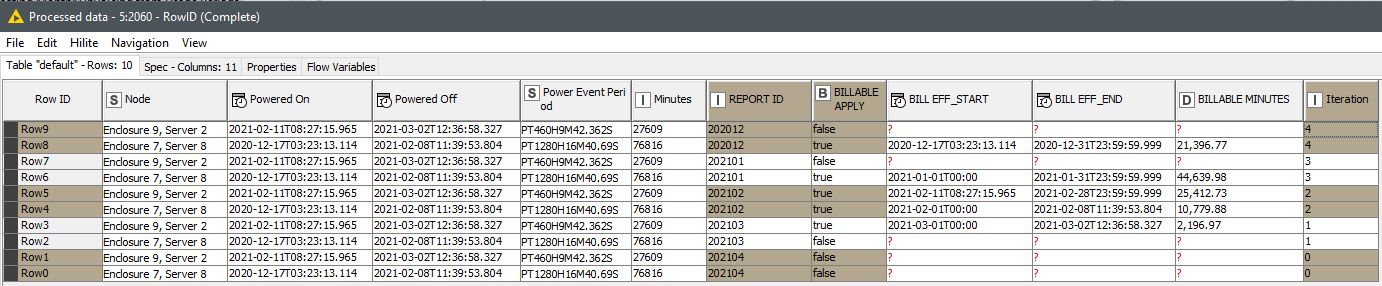
The problem I’ve run into (well, a couple of problems) is when a server has run from, lets say, the 11th of one month, to the 2nd of the next. Whilst in this case I can determine the duration, I need to be able to attribute one portion to one month’s billing and the remainder to the next month’s billing.
Here are two classic examples of this conundrum, one spans multiple months, the next spans two:
| Node | Powered On | Powered Off | Power Event Period | Minutes |
|---|---|---|---|---|
| Enclosure 7, Server 8 | 2020-12-17T03:23:13.114Z | 2021-02-08T11:39:53.804Z | PT1280H16M40.69S | 76816 |
| Enclosure 9, Server 2 | 2021-02-11T08:27:15.965Z | 2021-03-02T12:36:58.327Z | PT460H9M42.362S | 27609 |
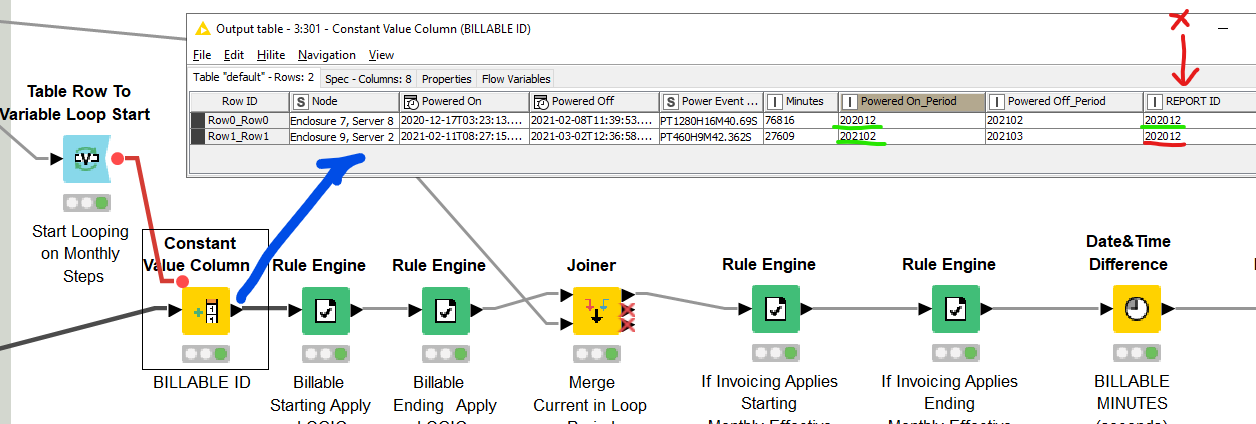
I perceive I need to somehow punctuate the threshold between months with an artificially inserted MonthEnd & MonthStart record. I am certain I’m not alone in juggling data like this - has anyone found, or can anyone conj our, a solution?
Sincere thanks
Cardinal
PS: Another closely related issue is the tracking of server power state at the end of a set of records.
Using the first row entry as an example, imagine my data set, at one point in time, ended 2020-12-31, Encl7,Srv8 would be an open ended record (with the server left in an on-state needing capping). It’s debatable then if by the end of 2021-02 if the whole of January would be billed as no recorded power event would show until the “off” event 2021-02-08T11:39:53.804Z. Has anyone come across these data issues?