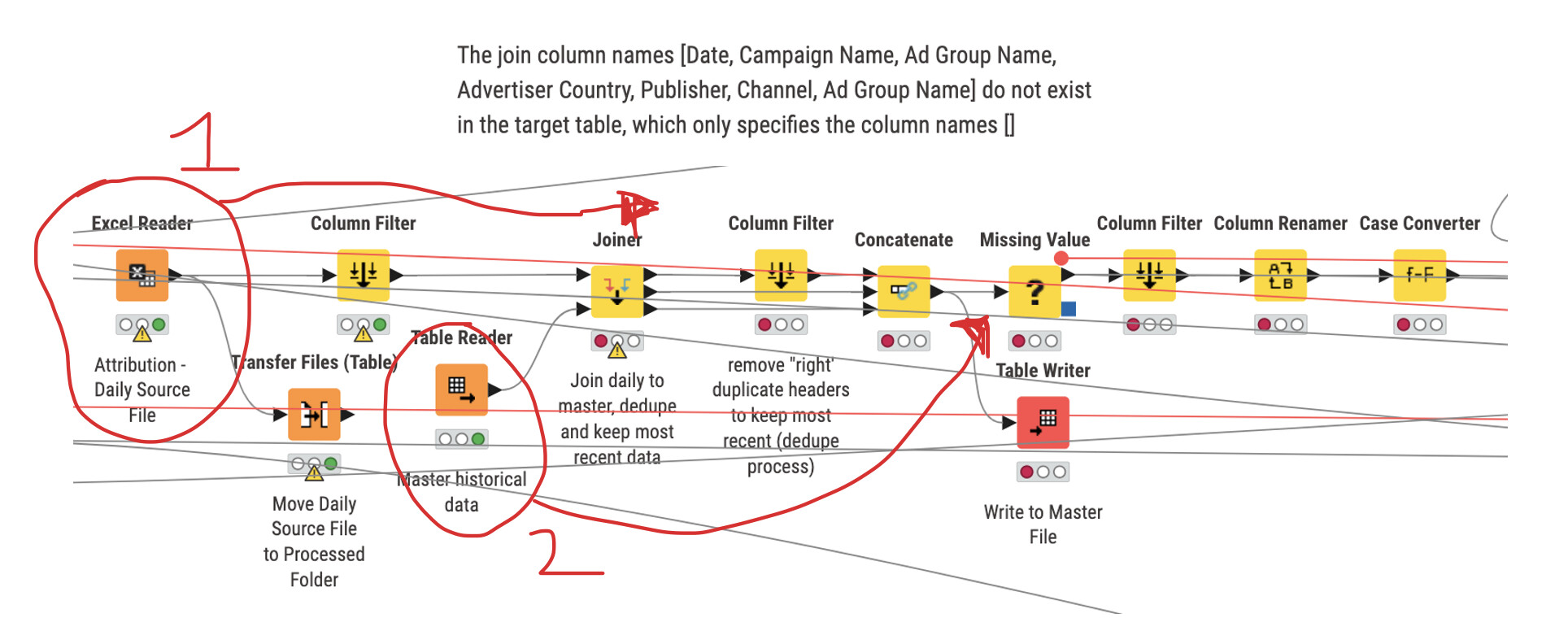
I have a workflow where I have several paths to ETL then union all feeds together. I have roughly 8 data sources - most I can grab through an API or Google Sheets, but there are a handful that get emailed to me daily or I have to download due to no API. I copy these files into a Dropbox folder. I take these data sources (usually last XX days to update any data items that may have changed (ie, Google Analytics as the day progresses). I join this file to a “master table” that I’ve created and saved locally, where the new data source overwrites any duplicates (joined). I then move the daily report to a ‘processed’ folder that empties the source folder and retains a history of the data files.
One of the files is now blank - data doesn’t populate daily. However, when that blank file joins to the master, the nodes are coming ‘red’. I (believe I) know that an IF switch should be used, but how would I incorporate that? What I would expect the workflow to indicate is something to the effect of: “If the daily source file is blank, then just pass the master table after the joins. If there is data in the daily source file, then join to the master table to dedupe and add the most recent data and pass through the workflow”
(All of the lines are from the other portions of the workflows that write to a Tableau file - side note; wireless connectors would be fantastic).
In below’s image - IF there is data in the daily source file data, THEN join to the master table and process through (path 1).
IF there’s no daily source file data, THEN ignore path 1 and use path 2 - passing the master table data through to the missing values node and continue as usual, bypassing the join, filter, and concatenate nodes.
is the file 1) “blank” i.e. the file exists but gets loaded as an empty table? Or 2) does the file “not exist” and therefore the excel reader errors out?
Depending on this the solution will look different.
If 1) Empty Table Switch Node should be the way to go
If 2) I think that may be a bit more complex and involve try-catch nodes… or getting a list of all files in the folder and checking the output if the specific name exists and then use case switch node…
Bit difficult to now create a basic scenario.
Maybe you can create some basic mock up data and provide the workflow? Would be happy to give it a crack then… (of course also clarify the questions above ).
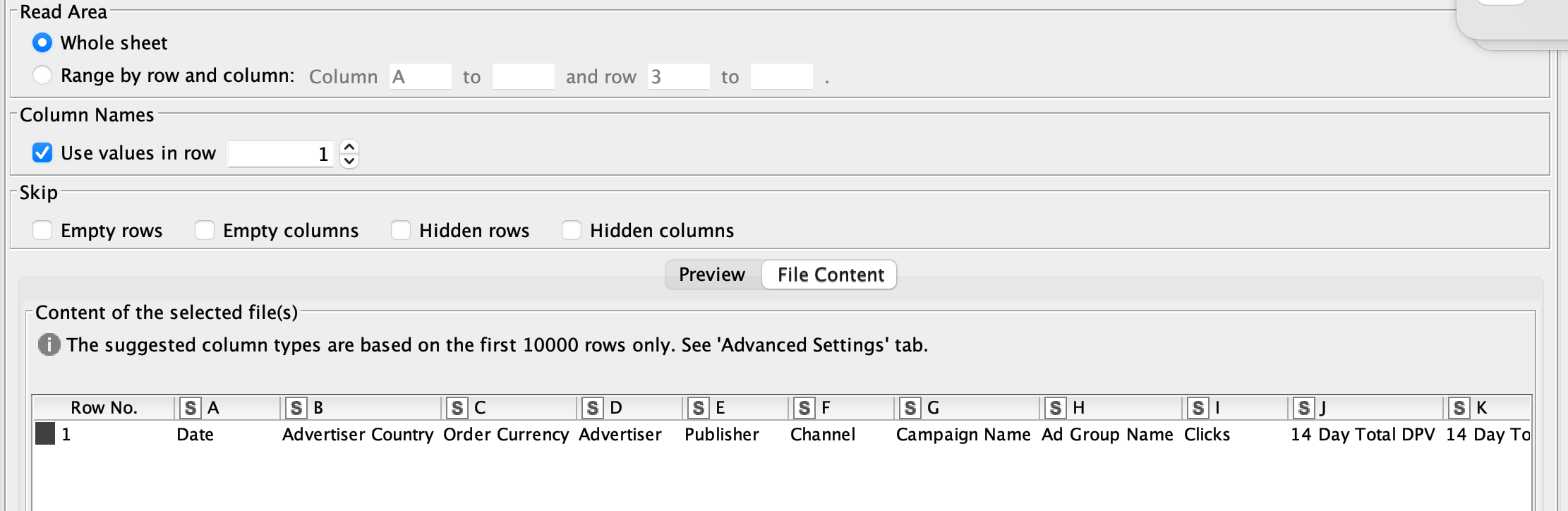
This particular file is an Excel - I had all of the “skip” rows checked initially. I deselected those, and the data passed through. However, because no data in the file (although there are header rows), the data passed through but with unknown data types, so there were negative impacts downstream (ie, three fields wouldn’t aggregate in the groupby because the data type was unknown when concatenating to the master table).
Because of this, I have to make adjustments to the entry path of the unknown (column expression to make the “?” field type for Date to Local Date, then use two string to number (one for integer, one for double), but the concern then becomes if data does get populated, the data types will then be different.
I doctored up the data and exported a working sample. KNIME_project2.knwf (104.0 KB)
Great - could you provide me with the test files as well?
I noticed that you read from local file system - that means that the files are not included by default.
Easiest way for you to share without having to worry to provide the files is:
navigate to your knime-workspace in your normal file explorer
navigate to where your workflow is saved and open up the folder that is named after your workflow (e.g. “KNIME_project2”)
Inside that folder, create a folder named “data” - save all files you need for your workflow in that folder
in all your Excel / CSV Readers etc. change the “Read from” setting to “Relative to” and select “Current workflow data area” (= the data folder you created) from the drop down. When you then click “Browse” you are immediately inside that data folder and can choose the filder.
Major benefit: The file becomes part of your workflow - if you share it on KNIME hub or export it and upload it, the example files are “part” of the workflow and whoever downloads it can get cracking right away
On the other question I raised:
However, because no data in the file (although there are header rows)
I take that the file “TEST FILE Downloaded.xlsx” will always exist, but sometimes will have no data in it correct?
Thank you! I learned something new - didn’t realize the data subfolder existed in the workflow and that’s how you export with data, thought it automatically did so. Appreicate that.
I think I did this correctly? I exported the workflow into a new area, but has the data subfolder populated.
the ‘TEST’ file is the ‘master table’, and the ‘TEST download’ is the file that gets downloaded. The reason this came to light was I use a moving “last 30 days” so there was always data in the downloaded .xlsx from the platform. Once I hit day 31 without data, the file came through completely blank (except the header rows). But I have other data sources that don’t go that far back that I will need to do the same thing with (if blank data, only process master file, if data populated, join to master and dedupe).
I think covers your questions. I greatly appreciate your assistance.
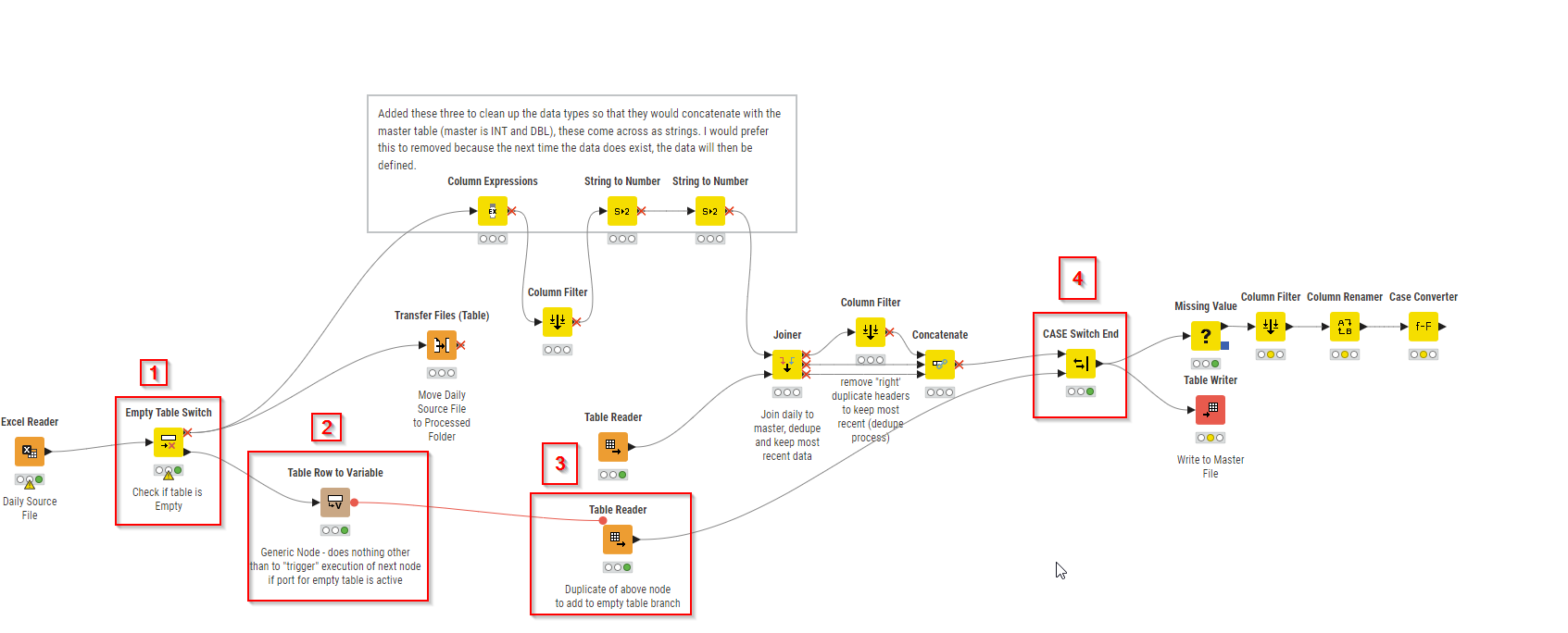
It looks like the file exists, but indeed just produces an empty table. That’s good as it allows to solve it like this:
1 ) Added Empty Table Switch Node to branch the workflow depending on whether the table is empty or not. Top port activates if table is not empty, bottom port activates if it is empty. Top branch stays unmodified until the end (4)
2/3) if I understand correctly then if the table is empty the same table that is read in the the table reader node is read and the process continues with missing value node. To achieve this I had to duplicate the Table Reader to ensure there is one for each of the to branches. To trigger it I used table row to variable node as a “dummy” - the only purpose is to be the first node in the empty table branch that then triggers reading the table with the variable port
4 ) to merge the two branches together we use CASE Switch End node and connect it to the missing value node…
Hope I understood correctly and this works for you