Hi @gabrielfs2 , this is a good example of how knowing your data is crucial to describing the problem, and resolving. Without seeing your data we can only guess at the problem and the solutions provided will of course reflect those guesses.
On the face of it though, the new problem you have outlined is not insurmountable.
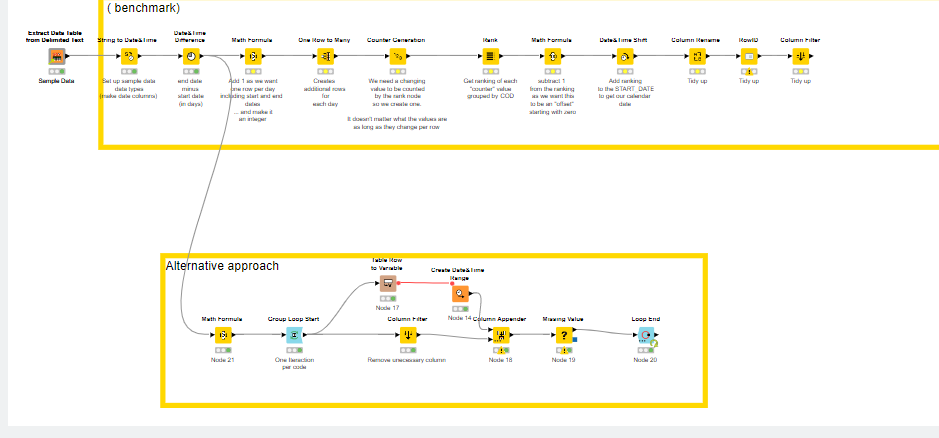
What you are looking for in database terms is a unique or “primary” key for the rows. The solution I provided is reasonably generic and involves the “rank” node grouping by one or more columns, and fortunately this can therefore be easily adapted to the new scenario.
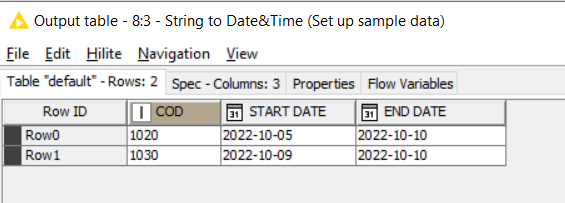
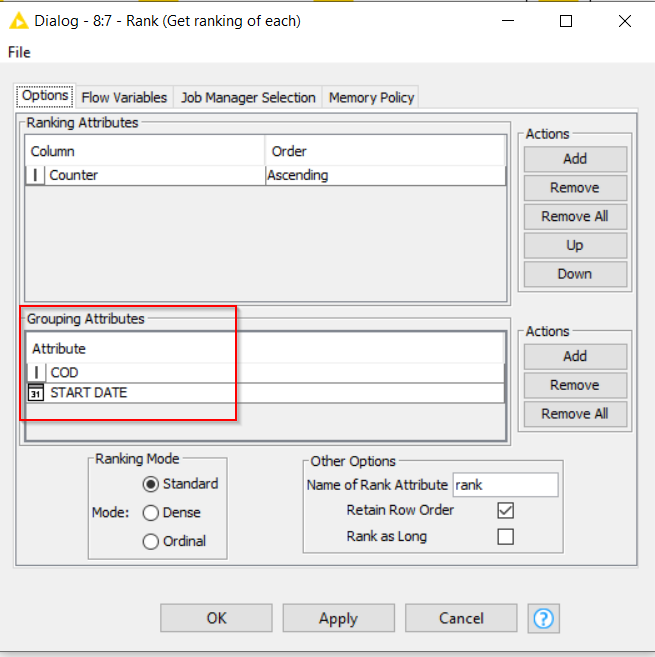
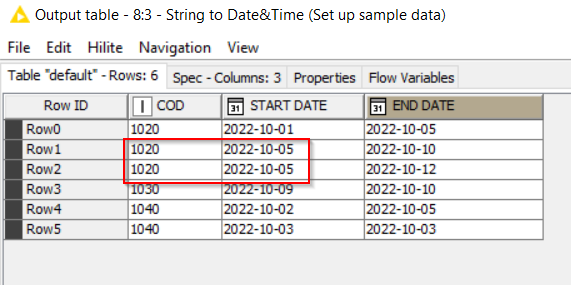
Your initial data sample suggested that the primary key for your problem would be COD. Therefore the “rank” node in my uploaded workflow used “COD” as the grouping column.
If you have now determined that the combination of COD and START DATE together form the “primary key”, then change the RANK node so that it groups by COD and START DATE
ie
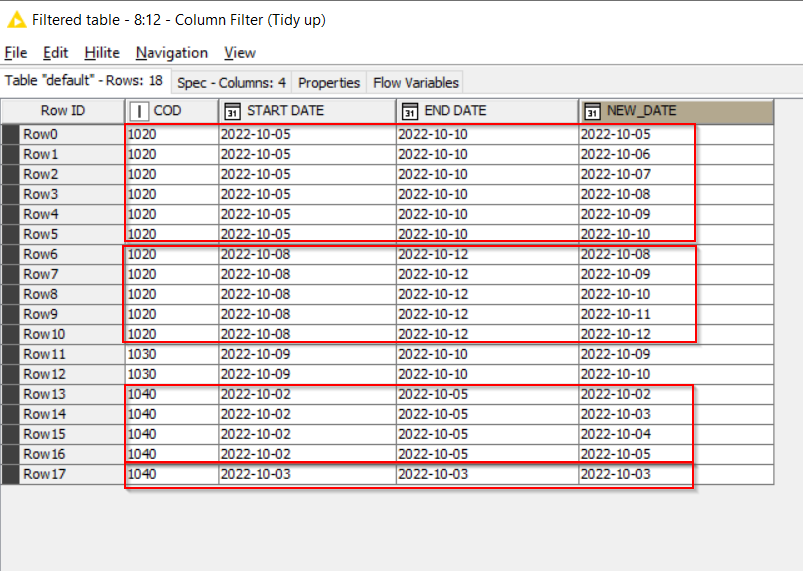
With some different sample data as shown here, this would then handle those groupings
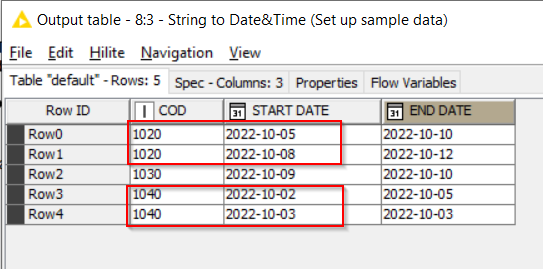
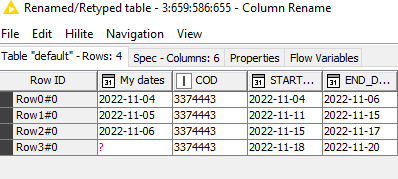
Of course, I can only once-again second-guess whether this will work for you with all of your data, and I’m going to now make the assumption that it is NOT unique on COD + START DATE.
It is quite possible that it IS unique on COD+START DATE+END DATE in which case I could use all three as the grouping in the Rank node, but I’ll show you what to do if it isn’t.
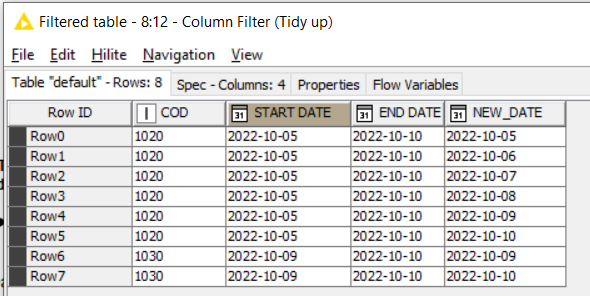
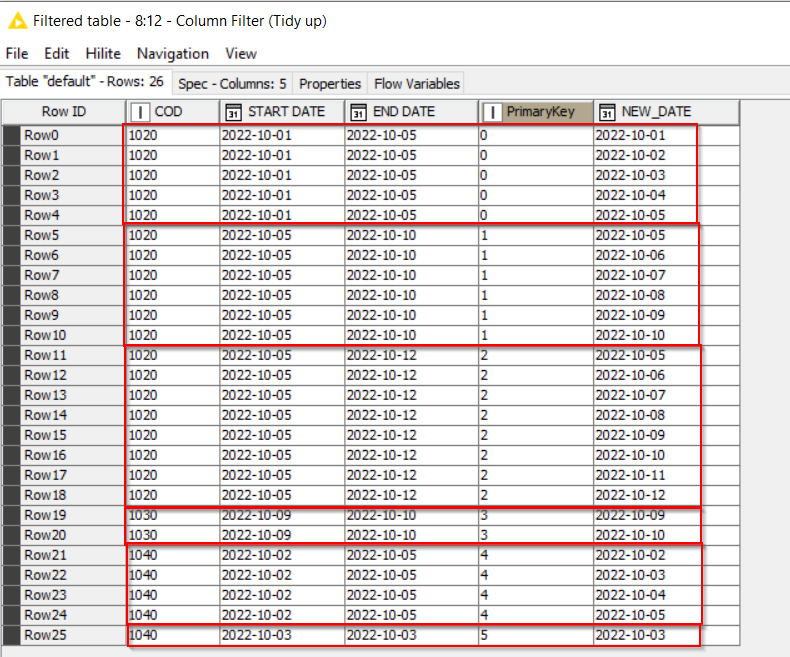
i.e. what do you do when you discover that no combination of columns makes your data unique. Well in that case you might want to question why you have duplicate rows, and possibly remove them, but let’s say for the sake of argument this scenario is valid. If you haven’t got a “unique key”, then you need to MAKE one! Placing a unique key on every row is actually easy. Just use an additional Counter Generation node prior to the One-Row-to-Many node. (and for good measure maybe rename the counter column as “PrimaryKey”). You can then group by just this PrimaryKey in the Rank node.
Then even if your initial data is not unique by any combination, this flow will still work.
I’ve left the new “PrimaryKey” column in to demonstrate the point. You’d probably want to add that into the column filter at the end to tidy things up.
Fill in dates between- primarykey.knwf (59.0 KB)
[Edit - you can see from the two responses, both from me and @Adrix, the solution in both cases is the same: change the “grouping” so that it groups by something that uniquely identifies the row of data ]